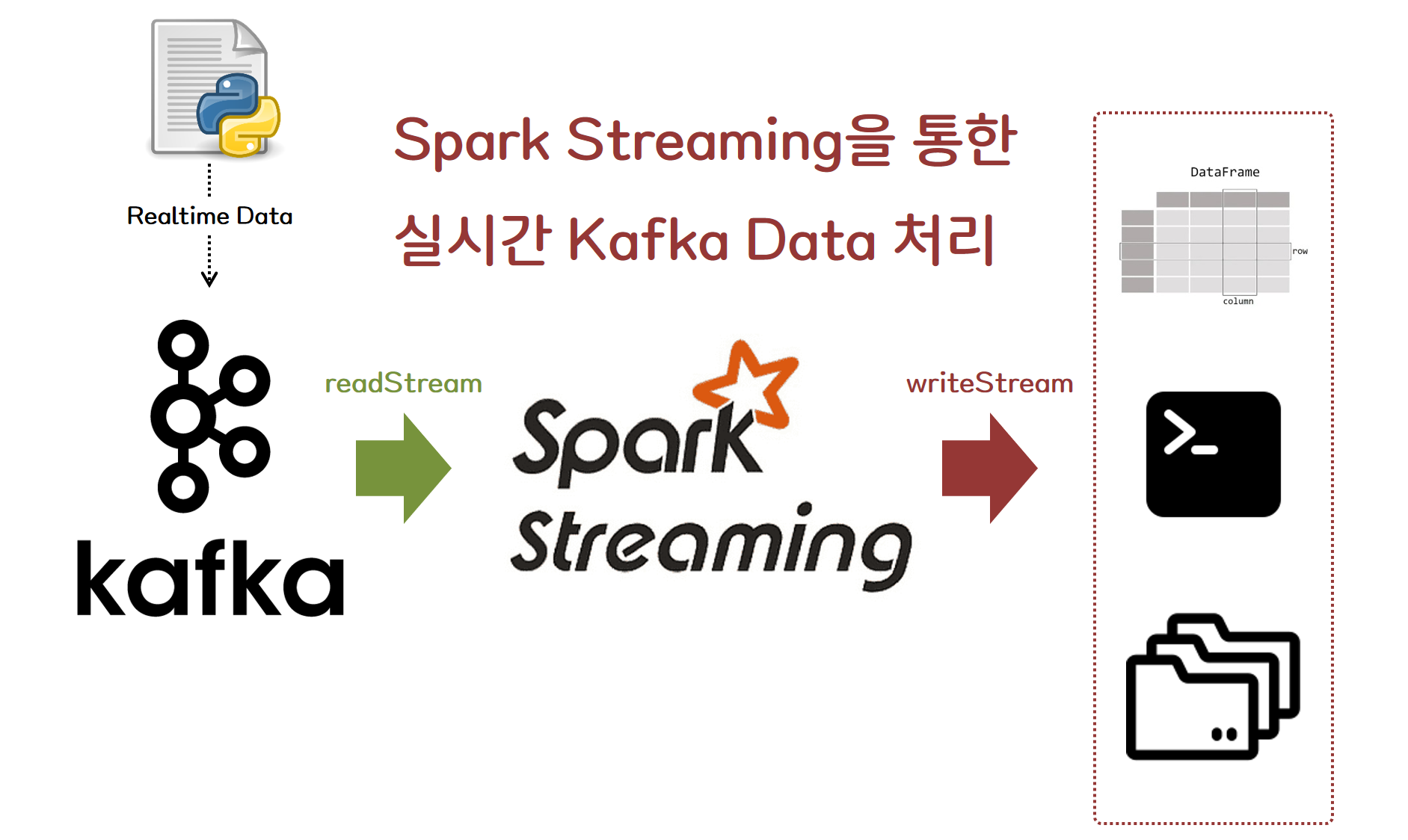
- 실습 환경이 Spark Streaming을 통한 실시간 파일 처리 글과 이어지므로 Spark Cluster 구성을 위해 해당 글을 참고해주세요.
- 이전 글에서는 실시간으로 들어오는 파일 데이터를 원천으로 하여 Spark Streaming으로 데이터 처리하는 내용을 다뤄보았습니다.
- 이번 글에서는 아마도 가장 흔히 사용되는 사례인 Kafka Cluster를 통해 들어오는 실시간 데이터를 받아와 Spark Streaming을 통해 실시간으로 처리하는 내용에 대해 학습하고 정리해보았습니다. 즉, Spark Streaming을 Kafka Consumer로 활용하는 것입니다.
1. Docker Compose를 통한 Kafka Cluster 생성
- 하나의 Kafka Container만 올려서 실습해도 되지만 Cluster 환경에서 실습을 위해 Docker Compose를 활용하여 Kafka Cluster를 구성해준다.
- Docker Compose에는 아래와 같이 zookeeper 1개, kafka node 3개, Kafka Cluster에 대한 관리를 할 수 있는 UI 1개 이렇게 총 5개의 컨테이너로 구성된다.
- zookeeper - 1개
- kafka node - 3개
- kafkadrop UI - 1개
- 앞서 구성하였던 Spark Cluster와 동일한 Network 환경에 배치될 수 있도록 각 컨테이별로 네트워크도 명시해준다.
docker-compose.yaml
version: '3'
services:
zookeeper:
image: zookeeper:3.7
hostname: zookeeper
user: '0:0'
ports:
- "2181:2181"
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
volumes:
- /mnt/d/kafka/data/zookeeper/data:/data
- /mnt/d/kafka/data/zookeeper/datalog:/datalog
restart: always
networks:
- dockercompose_dataops
kafka1:
image: confluentinc/cp-kafka:7.0.0
hostname: kafka1
user: '0:0'
ports:
- "9091:9091"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka1:19091,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9091
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- /mnt/d/kafka/data/broker1:/var/lib/kafka
restart: always
depends_on:
- zookeeper
networks:
- dockercompose_dataops
kafka2:
image: confluentinc/cp-kafka:7.0.0
hostname: kafka2
user: '0:0'
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka2:19092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- /mnt/d/kafka/data/broker2:/var/lib/kafka
restart: always
depends_on:
- zookeeper
networks:
- dockercompose_dataops
kafka3:
image: confluentinc/cp-kafka:7.0.0
hostname: kafka3
user: '0:0'
ports:
- "9093:9093"
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka3:19093,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- /mnt/d/kafka/data/broker3:/var/lib/kafka
restart: always
depends_on:
- zookeeper
networks:
- dockercompose_dataops
kafdrop:
image: obsidiandynamics/kafdrop
ports:
- "9000:9000"
environment:
KAFKA_BROKER_CONNECT: "kafka1:19091"
restart: always
depends_on:
- kafka1
- kafka2
- kafka3
networks:
- dockercompose_dataops
networks:
dockercompose_dataops:
external: true2. kafdrop 을 통한 Kafka Topic 생성
-
Port 간섭 없이 정상적으로 docker compose 파일이 설치가 되었다면 kafka 클러스터 관련 5개의 컨테이너가 Up 상태가 되었을 것이다.
-
9000번 포트로 접속을 하게되면 kafdrop UI를 볼 수 있다.
-
아래 부분 Topic 섹션에서
+new탭을 누르면 새로운 토픽을 손쉽게 생성할 수 있다. "demo" 라는 토픽을 생성하여 실습을 진행하도록 할 것이다.
3. Kafka Producer를 통해 토픽으로 데이터 전송
1) Fake data 생성
- Faker 라이브러리를 사용하여 아래 형상과 같은 가상의 인적사항 데이터가 생성되도록 코드를 짜준다. (Faker와 shortuuid 라이브러리 설치 필요)
fakedata.py
from faker import Faker
import shortuuid
from datetime import datetime
fake = Faker()
fake.profile()
def create_fakeuser() -> dict:
fake = Faker()
fake_profile = fake.profile()
key_list = ["name", "ssn", "job", "residence", "blood_group", "sex", "birthdate"]
fake_dict = dict()
for key in key_list:
fake_dict[key] = fake_profile[key]
fake_dict["uuid"] = shortuuid.uuid()
fake_dict['birthdate'] = fake_dict['birthdate'].strftime("%Y%m%d")
fake_dict['timestamp'] = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
return fake_dict형상
{'name': 'Donald Smith',
'ssn': '571-96-7625',
'job': 'Clinical embryologist',
'residence': '39473 Bailey Islands Apt. 406\nLake Jamesmouth, WV 65741',
'blood_group': 'B+',
'sex': 'M',
'birthdate': '19560708',
'uuid': 'by7vqUMcNpZQBqaScCEuYN',
'timestamp': '2024-05-23 01:27:12'}2) Kafka Producer 코드 작성
- 위에서 생성된 가상 데이터를 kafka의
demo토픽으로 전송한다. - 전송시 2초의 간격을 두고 for loop를 돌면서 가상 데이터를 하나씩 전송하게 된다.
import time, json
from kafka import KafkaProducer
from fakedata import create_fakeuser
topic_name = "demo"
producer = KafkaProducer(
bootstrap_servers=["kafka1:19091", "kafka2:19092", "kafka3:19093"]
)
ORDER_LIMIT = 100
for i in range(1, ORDER_LIMIT+1):
data = create_fakeuser()
producer.send(topic_name, json.dumps(data).encode("utf-8"))
print("=="*30)
print(data)
print(f">>>>>>>>>>> {i} MESSAGE SENT <<<<<<<<<<<<")
time.sleep(2)4. Spark 코드 작성
- 위에서
demo토픽으로 전송된 데이터를 Spark Streaming이 Consumer 역할을 하면서 받아와 처리를 해주어야 한다. demo토픽에 저장된 내용을 단순히 가져와서 읽기 위해서는spark.read함수를 사용하면 되지만 실시간으로 streaming하여 읽으려고 하는 경우에는spark.readStream함수를 사용해주어야 한다.
1) Spark config 설정을 통한 Kafka 연동
- Spark에서 Kafka 클러스터 연동을 위해서는 spark session 생성시 추가적인 설정이 필요하다.
- spark kafka maven 주소에 접속하여 해당 spark 버전에 맞는 repo로 들어가
spark.jars.packages설정에 들어갈 내용을 추가해주어야 한다.
from pyspark.sql import SparkSession
spark = (
SparkSession
.builder
.appName("kafka_streaming")
.config('spark.jars.packages', 'org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.0')
.master("local[*]")
.getOrCreate()
)2) Spark로 Kafka 토픽에 저장된 메세지 읽어오기
- 우선
spark.read함수를 사용하여 토픽에 저장되어 있는 데이터를 일회성으로 읽어와 처리하는 코드를 작성한다.
topic_name = "demo"
bootstrap_servers = "kafka1:19091,kafka2:19092,kafka3:19093"
kafka_df = spark.read \
.format("kafka") \
.option("kafka.bootstrap.servers", bootstrap_servers) \
.option("subscribe", topic_name) \
.option("startingOffsets", "earliest") \
.load()
kafka_df.show()
+----+--------------------+-----+---------+------+--------------------+-------------+
| key| value|topic|partition|offset| timestamp|timestampType|
+----+--------------------+-----+---------+------+--------------------+-------------+
|null|[7B 22 6E 61 6D 6...| demo| 2| 0|2024-05-20 01:22:...| 0|
|null|[7B 22 6E 61 6D 6...| demo| 0| 0|2024-05-20 01:22:...| 0|
|null|[7B 22 6E 61 6D 6...| demo| 2| 1|2024-05-20 01:22:...| 0|
|null|[7B 22 6E 61 6D 6...| demo| 2| 2|2024-05-20 01:53:...| 0|
|null|[7B 22 6E 61 6D 6...| demo| 1| 0|2024-05-20 01:53:...| 0|
+----+--------------------+-----+---------+------+--------------------+-------------+3) 읽어온 메세지 처리하기
- Kafka 토픽에 저장된 내용을 바로 읽어왔기 때문에 value 컬럼내에 byte로 변환되어 데이터가 들어가있다. 이 부분을 읽을 수 있는 내용을 변환해주어야 한다.
##데이터에 대한 Schema 선언
schema = T.StructType([
T.StructField("birthdate", T.StringType()),
T.StructField("blood_group", T.StringType()),
T.StructField("job", T.StringType()),
T.StructField("name", T.StringType()),
T.StructField("residence", T.StringType()),
T.StructField("sex", T.StringType()),
T.StructField("ssn", T.StringType()),
T.StructField("uuid", T.StringType()),
T.StructField("timestamp", T.TimestampType()),
])
## value 컬럼 내용 변환 후 table 형태로 가공
value_df = kafka_df.select(F.from_json(F.col("value").cast("string"), schema).alias("value"))
processed_df = value_df.selectExpr(
"value.birthdate",
"value.blood_group",
"value.job",
"value.name",
"value.residence",
"value.sex",
"value.ssn",
"value.uuid",
"value.timestamp"
)
processed_df.show()
+---------+-----------+--------------------+-----------------+--------------------+---+-----------+--------------------+-------------------+
|birthdate|blood_group| job| name| residence|sex| ssn| uuid| timestamp|
+---------+-----------+--------------------+-----------------+--------------------+---+-----------+--------------------+-------------------+
| 20200724| B+|Medical sales rep...| Rachel Moore|166 Peters Valley...| F|066-83-1189|9qA2gsGoA2mm9Ka9x...|2024-05-20 01:22:53|
| 19690318| A+| Arboriculturist| Jeffery Thompson|999 Simmons River...| M|247-66-1932|PPtpVZVJvzm6TCByK...|2024-05-20 01:54:00|
| 19360621| A+|Lecturer, further...| Richard Trevino|USCGC Burnett\nFP...| M|354-23-9711|LyF7YaaZhU3PZzHoP...|2024-05-20 01:54:06|
| 20240305| A+|Accountant, chart...|Taylor Washington|2495 Nelson Field...| M|796-40-1135|VSAhzdQLTcnkK6YsA...|2024-05-20 01:54:08|
| 19590717| B-|Maintenance engineer| Barbara Johnson|483 Selena Locks ...| F|877-04-5763|X4myut2ntC8WpH4gf...|2024-05-20 01:54:10|
+---------+-----------+--------------------+-----------------+--------------------+---+-----------+--------------------+-------------------+4) 읽어온 메세지 저장하기
- 처리된 데이터에 대해 console, memory, file 등 다양한 형식으로 저장이 가능하지만 이번 실습에서는 console에 바로 보여질 수 있도록 코드를 작성할 것이다. 그 외 형식으로의 저장에 대해서는 이전 글에서 다루고 있다.
df_console = processed_df.writeStream \
.format("console") \
.outputMode("append") \
.option("checkpointLocation", "checkpoint_dir/kafka_streaming") \
.trigger(processingTime="5 seconds") \
.start()
df_console.awaitTermination().outputMode("append"): 마지막 트리거 이후 새롭게 처리된 행들에 대해서만 처리option("checkpointLocation", "checkpoint_dir/kafka_streaming"): 중복처리 방지를 위해 데이터 처리 기록을 남기기 위한 디렉토리trigger(processingTime="5 seconds"): write 되는 빈도awaitTermination(): writeStream 코드가 종료될때까지 코드를 계속 실행하며 기다린다.
5. 전체 코드 작동
- 이제
spark.readStream함수를 통해 데이터를 실시간으로 읽어와 처리하고 콘솔에 print 하는 통합 코드(kafka_streaming.py)를 구성해본다.
kafka_streaming.py
from pyspark.sql import SparkSession
topic_name = "demo"
bootstrap_servers = "kafka1:19091,kafka2:19092,kafka3:19093"
spark = (
SparkSession
.builder
.appName("kafka_streaming")
.config('spark.jars.packages', 'org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.0')
.master("local[*]")
.getOrCreate()
)
kafka_df = (
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrap_servers)
.option("subscribe", topic_name)
.option("startingOffsets", "earliest")
.load()
)
schema = T.StructType([
T.StructField("birthdate", T.StringType()),
T.StructField("blood_group", T.StringType()),
T.StructField("job", T.StringType()),
T.StructField("name", T.StringType()),
T.StructField("residence", T.StringType()),
T.StructField("sex", T.StringType()),
T.StructField("ssn", T.StringType()),
T.StructField("uuid", T.StringType()),
T.StructField("timestamp", T.TimestampType()),
])
value_df = kafka_df.select(F.from_json(F.col("value").cast("string"), schema).alias("value"))
processed_df = value_df.selectExpr(
"value.birthdate",
"value.blood_group",
"value.job",
"value.name",
"value.residence",
"value.sex",
"value.ssn",
"value.uuid",
"value.timestamp"
)
df_console = processed_df.writeStream \
.format("console") \
.outputMode("append") \
.option("checkpointLocation", "checkpoint_dir/kafka_streaming") \
.trigger(processingTime="5 seconds") \
.start()
df_console.awaitTermination()- 위의
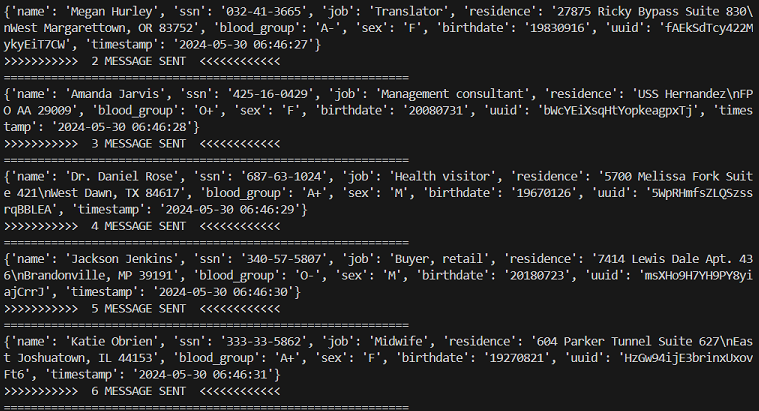
kafka_streaming.py파일을 실행하여 대기를 시켜주고fakedata.py파일 실행을 통해 kafka cluster에 fake data를 보내준다. - kafka cluster로 실시간으로 들어가는 데이터
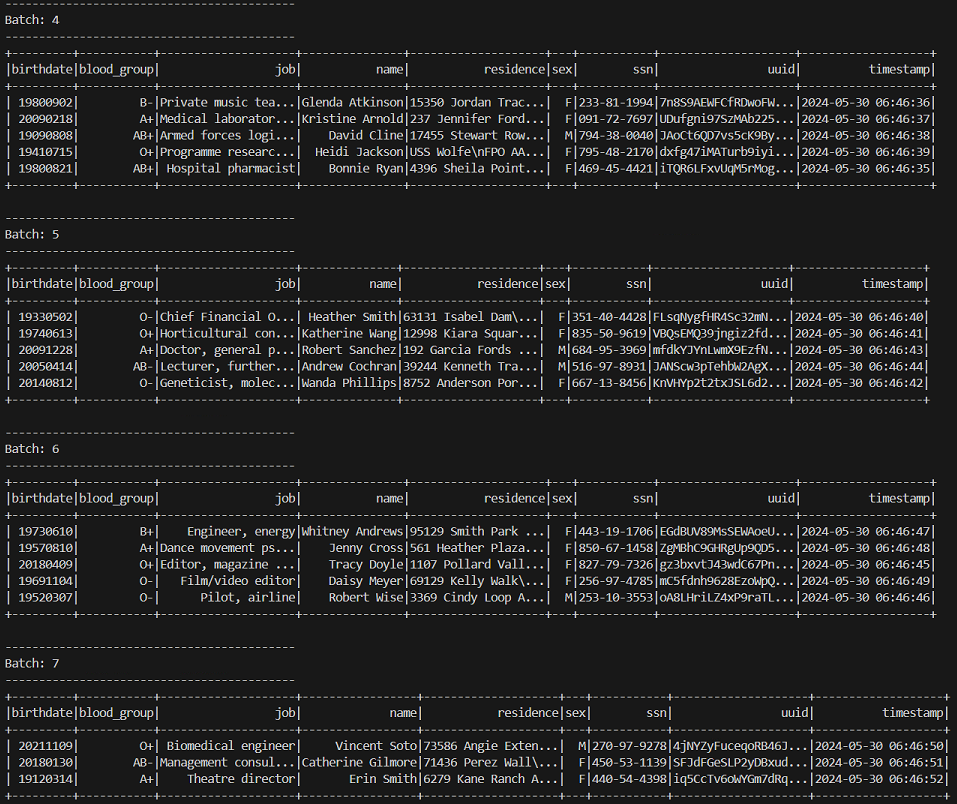
- Spark Streaming을 통해 콘솔에 찍히는 실시간 처리 결과
6. OUTRO
- Kafka Cluster의 특정 Topic으로 들어오는 실시간 데이터를 Spark Streaming으로 읽어 처리하는 내용을 다뤄보았습니다.
- 앞서 다룬 파일 데이터에 대한 실시간 처리 아키텍처에 비해 이번 글에서 다룬 Kafka와 연계된 상황이 실제로는 더 많이 사용될 것이라 생각됩니다. 또한 클러스터에서 클러스터로 데이터가 흘러가는 상황이므로 대용량의 데이터에 대해서도 유연한 처리가 가능할 것입니다.
- 다음 글에서는 이렇게 처리되는 실시간 데이터를 Spark를 통해 처리하고 MYSQL이나 PostgreSQL 데이터베이스에 실시간으로 저장해보는 내용을 다뤄볼까합니다.

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD