[Spark] Spark와 hadoop-aws 호환 버전에 따른 AWS S3와 통신할 수 있는 Spark Jupyter Lab Docker Image 구성하기
SPARK
🔹 0. INTRO
- AWS S3는 거의 무제한의 저장 용량을 제공하며, 이를 통해 대규모 데이터를 저장하고 관리할 수 있어 Data Lake, Data Warehouse, Data Mart 등 다양한 티어의 데이터들을 저장하는 저장소로 활용하기 적합합니다.
- AWS EMR Notebook이나 Glue Notebook을 사용하면 Spark를 활용하여 S3에 저장된 파일 데이터를 곧바로 조회해올 수 있습니다. 하지만 AWS에서 제공해주는 Notebook 자원이 아닌, 로컬이나 특정 서버에 동일한 환경을 구축하기 위해서는
hadoop-aws,aws-java-sdk-bundle과 같은 Jar 파일들을 추가해주어야 하며 버전 호환성까지도 생각해주어야 합니다. - 이번 글에서는 AWS S3와 통신할 수 있는 Jupyter Lab 환경 구성에 필요한 jar 파일들을 각 Spark 버전별로 찾는 방법과 그에 따라 Dockerfile을 어떻게 구성하면 되는지 정리해보았습니다.
🔹 1. 호환성 버전 찾기
1. spark hadoop 버전 결정
1) Apache Spark archive 접속
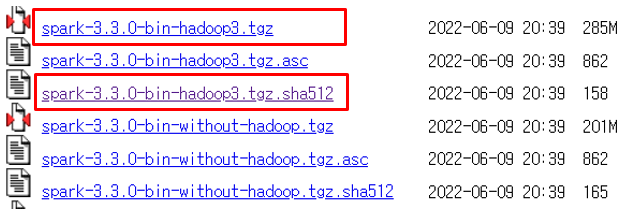
2) 구성하고자 하는 Spark 버전 선택 (spark version -> 3.3.0)

3) pyspark 기준 spark-[버전]-bin-hadoop[버전].tgz 형식으로 된 압축파일에서 hadoop 버전 확인 (hadoop version -> 3)
4) spark-[버전]-bin-hadoop[버전].tgz.sha512 형식으로 된 압축파일 접속 후 해당 버전에 대한 암호값 확인 (암호값 -> 1e8234d0c1d2ab4462d6b0dfe5b54f2851dcd883378e0ed756140e10adfb5be4123961b521140f580e364c239872ea5a9f813a20b73c69cb6d4e95da2575c29c)
2. hadoop-aws 버전 결정
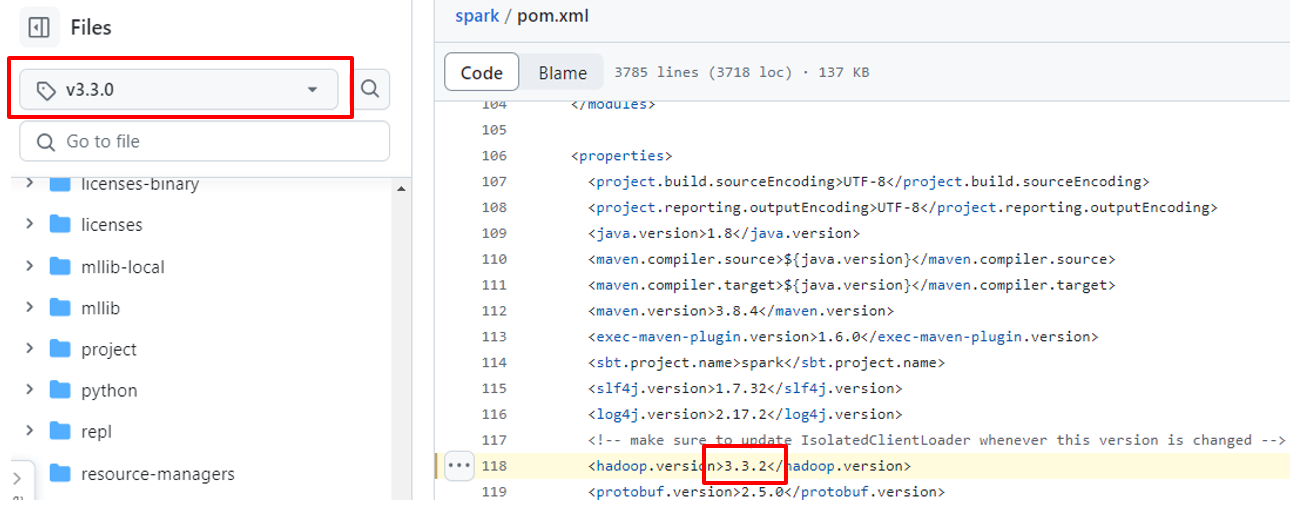
1) Apache Spark 공식 Github 링크로 접속
2) 좌측 상단에서 구성하고자 하는 Spark 버전 선택
3) pom.xml 파일내에서 hadoop.version를 검색
4) 아래와 같이 해당 spark 버전에 대한 hadoop 버전 확인 가능 (spark hadoop version -> 3.3.2)
3. aws-java-sdk-bundle 버전 결정
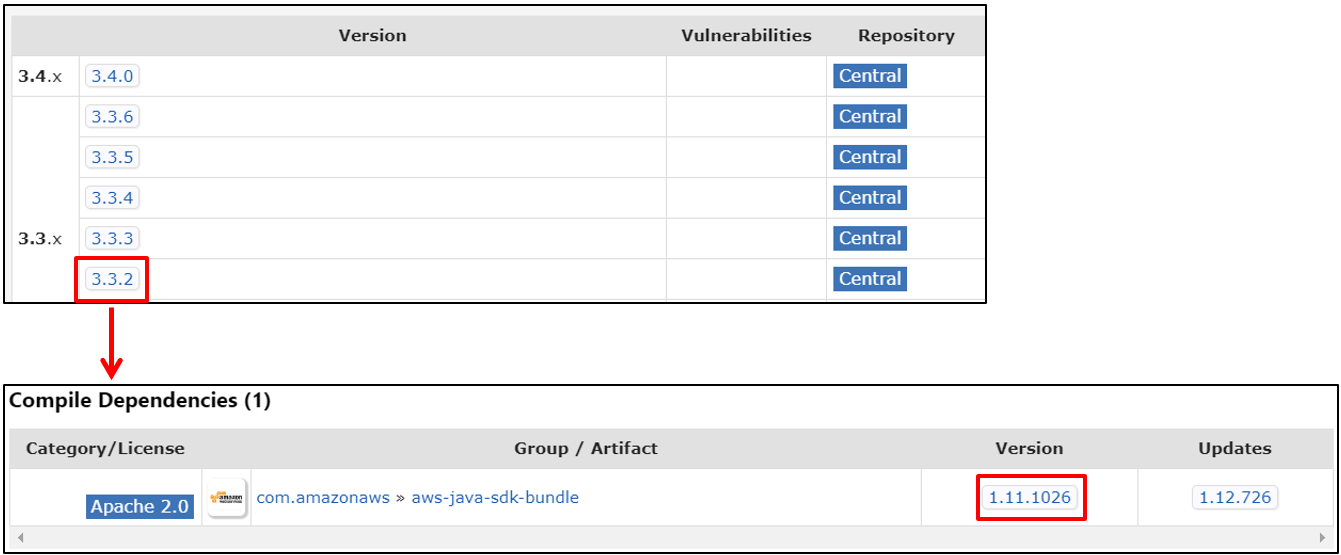
1) hadoop-aws maven 저장소 링크로 접속
2) 위에서 확인한 hadoop 버전 클릭
3) Compile Dependencies (1) 탭에서 아래 사진과 같이 aws-java-sdk-bundle에 대한 버전 확인 가능 (aws-java-sdk-bundle version -> 1.11.1026)
🔹 2. Dockerfile 구성하기
- Ubuntu 기본 이미지를 바탕으로 설치되며 전체적인 설치 순서는 아래와 같다.
1) 포트 개방 개방, 유저 정의
2) spark, hadoop-aws, aws-java-sdk-bundle 등 Spark 환경 구성에 필요한 버전을 변수에 할당
3) Python 및 필요 라이브러리 설치
4) Spark 설치
5) hadoop-aws 및 aws-sdk 관련 내용 설치
6) Jupyter Lab 관련 Initial 설정
7) Docker Image 기본 명령 입력
Dockerfile
# 1-----base image
FROM ubuntu:20.04
WORKDIR /workspace
# Expose port
EXPOSE 8888 4040
# User setting
USER root
# 2-----Spark 환경 구성에 필요한 버전을 변수에 할당
ARG spark_version="3.3.0"
ARG hadoop_version="3"
ARG spark_checksum="1e8234d0c1d2ab4462d6b0dfe5b54f2851dcd883378e0ed756140e10adfb5be4123961b521140f580e364c239872ea5a9f813a20b73c69cb6d4e95da2575c29c"
ARG openjdk_version="11"
ARG aws_hadoop_version="3.3.2"
ARG aws_sdk_version="1.11.1026"
ENV APACHE_SPARK_VERSION="${spark_version}" \
HADOOP_VERSION="${hadoop_version}" \
AWS_SDK_VERSION="${aws_sdk_version}" \
AWS_HADOOP_VERSION="${aws_hadoop_version}"
ENV SPARK_HOME="/spark"
# 3-----Python 및 필요 라이브러리 설치
RUN apt-get update && \
apt-get install -y python3 python3-pip && \
rm -rf /var/lib/apt/lists/*
RUN apt-get update && apt-get install wget -y
RUN apt-get update && apt-get install openjdk-11-jdk -y
ENV JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
# requirements.txt 내 라이브러리들 설치
COPY requirements.txt ./
RUN pip3 install --upgrade pip && pip3 install --no-cache-dir -r requirements.txt
RUN apt-get clean && rm requirements.txt
# 4-----Spark 설치
RUN wget -q "https://archive.apache.org/dist/spark/spark-${APACHE_SPARK_VERSION}/spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" && \
echo "${spark_checksum} *spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" | sha512sum -c - && \
tar xzf "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" -C /workspace --owner root --group root --no-same-owner && \
rm "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz"
RUN mv "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}" spark
RUN mv spark /
RUN cp -p "${SPARK_HOME}/conf/spark-defaults.conf.template" "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo 'spark.driver.extraJavaOptions -Dio.netty.tryReflectionSetAccessible=true' >> "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo 'spark.executor.extraJavaOptions -Dio.netty.tryReflectionSetAccessible=true' >> "${SPARK_HOME}/conf/spark-defaults.conf"
# 5-----hadoop-aws 및 aws-sdk 관련 내용 설치
RUN wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/${AWS_HADOOP_VERSION}/hadoop-aws-${AWS_HADOOP_VERSION}.jar -P "${SPARK_HOME}/jars/" && \
wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/${AWS_SDK_VERSION}/aws-java-sdk-bundle-${AWS_SDK_VERSION}.jar -P "${SPARK_HOME}/jars/"
# Adding JetS3t libary
RUN wget https://repo1.maven.org/maven2/net/java/dev/jets3t/jets3t/0.9.4/jets3t-0.9.4.jar -P "${SPARK_HOME}/jars/"
# 6-----Jupyter Lab 관련 Initial 설정
RUN ipython profile create
RUN echo "c.IPKernelApp.capture_fd_output = False" >> "/root/.ipython/profile_default/ipython_kernel_config.py"
# Jupyter workspace 설정
WORKDIR /workspace/spark
# 7-----Docker Image 기본 명령 입력
CMD ["jupyter", "lab", "--ip=0.0.0.0", "--port=8888", "--no-browser", "--allow-root"]requirements.txt
jupyterlab
pyarrow
s3fs
pandas
boto3
findspark
pyspark==3.3.0🔹 3. Spark를 통한 AWS S3 데이터 조회
- 위의 Dockerfile 빌드 후 해당 이미지를 8888 포트 매핑으로 컨테이너를 생성하면
localhost:8888URL을 통해 Jupyter Lab에 접속할 수 있다. - 아래 Spark 코드를 통해 AWS S3에 저장된 파일을 Spark DataFrame 형태로 읽어올 수 있다. 단, S3 주소의 경우
s3://형식이 아닌s3a://형식으로 넘겨주어야 정상적으로 연동이 된다.
from pyspark.sql import SparkSession
spark = (
SparkSession
.builder
.appName("pyspark_s3")
.master("local[*]")
.getOrCreate()
)
sc = spark.sparkContext
access_key = "AWS ACCESS KEY ID"
secret_key = "AWS SECRET ACCESS KEY"
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", access_key)
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", secret_key)
sc._jsc.hadoopConfiguration().set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
sc._jsc.hadoopConfiguration().set("fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider")
sc._jsc.hadoopConfiguration().set("fs.s3a.connection.ssl.enabled", "false")
spark.read.parquet("s3a://directory/for/s3/bucket/")🔹 4. OUTRO
- Spark와 필요한 jar 파일별 버전 호환성만 맞으면 Spark 버전별로 S3와 통신하고 분석할 수 있는 환경을 손쉽게 만들 수 있기 때문에 상당히 유용하게 사용될 수 있습니다.
- 실제로 사내 Kubernetes 환경에서 데이터 엔지니어링을 할 때 위의 Dockerfile을 spark 3.5.0 버전으로 커스텀한 이미지를 사용하여 데이터를 이행하고 분석해오고 있습니다.
