
🔹 0. INTRO
- 작년에 실무에서 자주 쓰는 Pyspark 명령어 정리 라는 제목으로 pyspark의 기능들에 대하여 정리를 한 글을 쓴 적이 있습니다. 지금 와서 보니 전체적인 흐름은 괜찮았지만, 내용이 일관성 있게 정리되지 않아 조금 산만하다는 느낌이 많이 들어 이를 보완하기 위해 일부 내용을 추가하고, 전체적으로 통일된 포맷으로 내용을 정리해 보았습니다. 수정 후에는 전체적인 흐름과 구조가 좀 더 자연스럽고 명확하게 전개될 수 있도록 다듬었습니다.
- 실무에서 pyspark를 사용해본 경험상 데이터 분석 기초에 필요한 코드들은 아래 내용들로 대부분 커버가 될 것이라 생각합니다.
- 해당 글에서 다루지 않는 pyspark 코드 관련 추가적인 내용들은 sparkbyexamples 사이트를 참고하시면 자세히 설명되어 있습니다.
- 로컬 환경의 경우 따로
SPARK_HOME및JAVA_HOME관련 환경 변수 세팅이 필요하기 때문에 Google Colab에서 실습하는 것을 추천드립니다.
🔹 1. Spark 설치 및 세션 연결
▪ 1-1) 설치
pip install pyspark
▪ 1-2) 세션 연결
- Spark는 기본적으로 여러대의 서버가 묶여서 하나의 컴퓨터처럼 동작하는 클러스터 환경에서 사용되기 때문에 본격적인 분석 코드 개발 전에 먼저 클러스터와의 연결 정보를 설정하는
SparkSession을 먼저 생성해주어야 한다.
from pyspark.sql import SparkSession
from pyspark.sql import types as T
from pyspark.sql import functions as F
spark = SparkSession.builder \
.master("local") \
.appName("velog") \
.getOrCreate()🔹 2. 데이터 읽어오기
▪ 2-1) CSV 파일 읽기
df = spark.read.option('header', 'true').csv([CSV 파일 경로])
df = spark.read.csv([CSV 파일 경로], header=True)▪ 2-2) PARQUET 파일 읽기
df = spark.read.parquet([PARQUET 파일 경로])▪ 2-3) Dataframe 출력
df.show(Row 수) # Row 수가 주어지지 않았을 경우 기본 20개의 row를 출력
df.show(truncate=False) # dataframe의 데이터가 길더라도 전체를 다 보여준다. Default는 True
df.show(vertical=True) # row에 대해 컬럼을 세로로 피벗해서 보여준다. Default는 False▪ 2-4) Dataframe 스키마 출력
df.printSchema()▪ 2-5) Dataframe 컬럼 타입 출력
df.dtypes▪ 2-6) Dataframe 컬럼 출력
df.columns▪ 2-7) 무작위 샘플 추출
# 0-1 사이로 사용자가 정한 fraction 비율을 바탕으로 샘플 데이터를 추출해서 보여준다.
df.sample(
withReplacement=False, # 복원 추출 여부
fraction=0.1, # 추출할 데이터의 비율
seed=42 # 랜덤 시드
).show()▪ 2-8) 기타 Dataframe 출력 방법들
df.first() # 첫번째 Row 만 Row 형식으로 출력
df.collect() # 컬럼의 Row들을 list 형식으로 출력
df.limit(n).show() # 컬럼의 첫 n개의 Row들을 list 형식으로 출력- 위의 방식으로 테이블 내용 출력시, row 하나하나마다 접근이 가능하다.
first_row = df.first()
first_row.Name, first_row.age, first_row.Experience🔹 3. 컬럼 다루기 & Dataframe 생성
▪ 3-1) 특정 컬럼만 선택
df.select('Name', 'age').show()
df.select(['Name', 'age']).show()▪ 3-2) 특정 컬럼 삭제
df_drop = df.drop('Experience')▪ 3-3) 컬럼 추가
# withColumn('컬럼 이름', 조건)
df.withColumn('add_col', F.lit("")) # 데이터가 없는 'add_col' 컬럼을 추가한다.▪ 3-4) 컬럼 이름 변경
# 컬럼 이름을 age -> new_age 로 변경
df.withColumnRenamed('age', 'new_age')
# 컬럼 이름 여러개 변환
df.withColumnRenamed('col1','colA').withColumnRenamed('col2','colB')....▪ 3-5) 컬럼 타입 변경
# age 컬럼을 INT -> STRING 으로 타입 변경
type_ = T.StringType()
df.withColumn('age', F.col('age').cast(type_))▪ 3-6) 새로운 Dateframe 생성
# 컬럼들의 스키마 결정
schema = T.StructType(
[
T.StructField('col_a', T.StringType(), True),
T.StructField('col_b', T.StringType(), True),
T.StructField('col_c', T.StringType(), True),
]
)
data = [
('apple', 'banana', 'tomato'),
('apple3', 'banana3', 'tomato3'),
('apple4', 'banana4', 'tomato4')
]
df_new = spark.createDataFrame(data, schema)
---
+------+-------+-------+
| col_a| col_b| col_c|
+------+-------+-------+
| apple| banana| tomato|
|apple3|banana3|tomato3|
|apple4|banana4|tomato4|
+------+-------+-------+🔹 4. Dataframe 읽기 및 쓰기 옵션들
▪ 4-1) READ의 옵션
- PERMISSIVE (default) : 읽어오는 테이블 데이터에 타입 이상이 있으면 null로 처리
- DROPMALFORMED : 타입 이상 있는 Row는 Drop
- FAILFAST : 타입 이상 있는 Row 발견시 읽기 작업 실행 실패
# 1
spark.read.option('mode', 'DROPMALFORMED').csv("파일 경로", header=True, inferSchema=True)
# PERMISSIVE
# FAILFAST
# 2
option_dict = {
"header" : "true",
"inferSchema" : "true",
"mode" : "DROPMALFORMED", # PERMISSIVE, FAILFAST
}
spark.read.options(**option_dict).csv("파일 경로")▪ 4-2) WRITE의 옵션
- error(default) : 동일한 이름의 파일 있으면 실행 실패
- ignore : 동일한 이름의 파일이 있으면 작업하지 않음
- overwrite : 기존 파일 덮어쓰기
- append : 기존 파일에 추가
# 일반적인 저장 방법
df.write.mode('overwrite').parquet("경로/파일명.parquet")
# error
# ignore
# append
# 하나의 파일로 저장
df.coalesce(1).write.mode('overwrite').parquet("경로/파일명.parquet")🔹 5. 결측치 다루기
▪ 5-1) 결측치 drop 하기 - dropna()
# 모든 컬럼을 대상으로 결측치 있는 row 삭제
df.dropna()
# thresh : row의 값들을 보았을 때, 정상값이 thresh개 보다 적게 있는 row를 drop
df.dropna(thresh=2).show()▪ 5-2) 결측치 drop 하기 - na.drop()
# 1
df.na.drop(how='all').show()
# any : null값이 하나라도 있으면 제거
# all : 모든 row가 null인 row만 제거
# 2 - 특정 컬럼에 대해서
df.na.drop(how='all', subset = ['age', 'Experience']).show()▪ 5-3) 결측치 채우기
# 1 - fillna()
df.fillna(value='컴퓨터', subset=['age', 'Experience'])
# 2 - na.fill()
df.na.drop(how='노트북', subset = ['Name', 'Salary'])🔹 6. 컬럼 데이터 필터링
- 컬럼 데이터 필터링에 사용할 테이블(df)은 아래와 같은 형상을 가지고 있다.
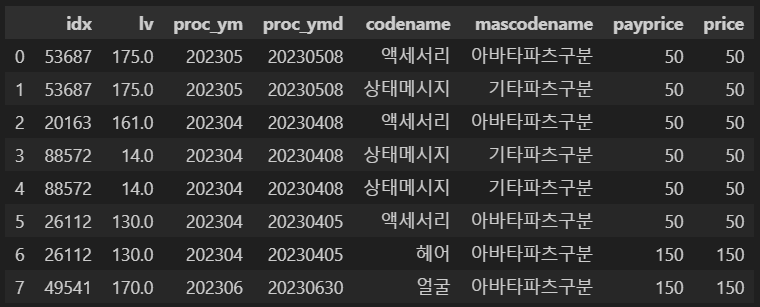
▪ 6-1) Filter 함수
# 1 - 단일 필터
df.filter(F.col('codename') == '액세서리')
# 2 - 다중 필터1
df.filter(F.col('codename') == '액세서리').filter(F.col('payprice') < 50)
# 3 - 다중 필터2
# df.filter((조건1) & (조건2) | (조건3) .....)
df.filter((F.col('codename') == '액세서리') | (F.col('payprice') < 50))
# 4 - 필터 반대 조건(~)
df.filter(~(F.col('codename') != '액세서리'))▪ 6-2) 중복 제거
# 1 - distinct() : 모든 컬럼에 대해 중복 제거. 추가 옵션 X
df.distinct()
# 2 - dropDuplicates()/drop_duplicates() : 이름만 약간 다르지만 동일한 메소드
df.dropDuplicates(subset = ['codename', 'price']) # 중복 제거시 고려할 컬럼▪ 6-3) 특정 값 포함 여부 확인 - isin
# 1 - codename에 '헤어', '얼굴' 포함된 Row
df.filter(F.col('codename').isin(['헤어', '얼굴']))
# 2 - codename에 '헤어', '얼굴' 포함되지 않은 Row
df.filter(~F.col('codename').isin(['헤어', '얼굴']))▪ 6-4) null 값 확인
# isNull() -> Null값인 row 출력
df.filter(F.col('codename').isNull()).show()
# isNotNull() -> Null값이 아닌 row 출력
df.filter(F.col('codename').isNotNull()).show()▪ 6-5) 비슷한 형태 확인 - like
# '아바타'로 시작되는 데이터가 있는 Row 출력
df.filter(F.col('mascodename').like('아바타%'))▪ 6-6) 사이 값 출력 - between
# payprice 컬럼의 데이터가 100이상, 200이하인 Row 출력
df.filter(F.col('payprice').between(100,200))▪ 6-7) when 조건문
# codename 컬럼의 데이터 null이면 '-'로 치환하고, 아니라면 그대로
condition = F.when(F.col('codename').isNull(), '-').otherwise(F.col('codename'))
df.withColumn('new_codename', condition)🔹 7. GROUP BY + AGGREGATION
- 데이터를 그룹핑하여 계산하고 그 결과에 해당하는 새로운 컬럼을 생성할 수 있다.
▪ 7-1) 기본 GROUP BY
df.groupby(컬럼).agg(집계수식(컬럼).alias(별칭))이러한 형식으로 작성이 가능하다.
df_groupby = \
df.groupby('col_a') \
.agg(
F.sum(F.col('col_a')).alias('sum'), # 총 합
F.count(F.col('col_a')).alias('cnt'), # 전체 Row 개수
F.countDistinct(F.col('col_a')).alias('dcnt'), # 컬럼의 distinct한 값 개수
F.mean(F.col('col_a')).alias('mean'), # 평균값
F.avg(F.col('col_a')).alias('average'), # 평균값
F.stddev(F.col('col_a')).alias('setd'), # 표준편차
F.min(F.col('')).alias('min'), # 최솟값
F.max(F.col('')).alias('max'), # 최댓값
F.round(F.avg('col_a'), 2).alias('round2'), # 반올림
F.collect_list(F.col('col_b')).alias('cl'), # group by 후 특정 컬럼의 값들을 list로 묶어준다.(중복 포함)
F.collect_set(F.col('col_b')).alias('cs') # group by 후 특정 컬럼의 값들을 list로 묶어준다.(중복 제거)
)▪ 7-2) GROUP BY + 조건(when-otherwise)
- 집계 함수 내에 조건문을 적용하여 특정 조건에 대해 집계가 적용될 수 있도록 설정 가능
df_groupby = \
df.groupby('col_a') \
.agg(
F.count(F.when('조건', '대상컬럼').otherwise('조건 불만족시 대상컬럼'))
)🔹 8. ORDER BY
▪ 8-1) 하나의 컬럼 대상 정렬
# 1 - 기본 오름차순 정렬
df.orderBy('Salary')
df.orderBy(F.col('Salary').asc())
# 2 - 내림차순 정렬
df.orderBy('Salary', ascending=False)
df.orderBy(F.col('Salary').desc())▪ 8-2) 여러개의 컬럼 대상 정렬
# 1 - 여러 컬럼 대상 정렬
df.orderBy('age', 'Salary')
# 2 - 여러 컬럼 + 정렬 순서 설정
df.orderBy(F.col('age'), F.col('Salary').desc())🔹 9. JOIN & UNION
▪ 9-1). Join
df1.join(df2, join할 컬럼, join 종류) 의 형태로 코드가 구성된다.
# 1 - 이름이 다른 컬럼들 끼리의 Join
df_1.join(df_2, df_1.col_a == df_2.col_b, 'left')
# 2 - 이름이 동일한 컬럼들 끼리의 join
df_1.join(df_2, ['col_a'], 'left')
# 3 - 여러 컬럼들 끼리 join
df_1.join(df_2, (df_1.Name == df_2.Name) & (df_1.Salary == df_2.Salary))
# 4 - 이름이 동일한 여러 컬럼들 끼리 join
df_1.join(df_2, ['Name', 'Salary'], 'left')▪ 9-2) Union
# 1 - Union (테이블들의 컬럼이 반드시 동일)
df_1.union(df_2)
# 2 - UnionByName (테이블의 컬럼이 동일하지 않아도 됨)
df_1.unionByName(df_2, allowMissingColumns = True)🔹 10. 데이터 Cleansing
# 1 - zfill : 0으로 채운다.
df.select(
F.lpad(F.col('col_a'), 5, '0').alias('lpad_col_a'), # 5자리까지 0으로 채운다.
'col_b',
'col_c'
)
# 2 - trim : 좌우 공백 제거
df.withColumn(F.col('col_a'), F.trim(F.col('col_a')))
# 3 - regexp_replace : 값 변경
df.withColumn(F.col('col_a'), F.regexp_replace('col_a', 'Before', 'After'))
# 4 - 컬럼 순서 재정렬
df.select([원하는 컬럼 순서 나열])
# 6 - 컬럼 내용 합치기
df.withColumn('concat_ab', F.concat(F.col('col_a'), F.col('col_b')))
# 7 - datetime 컬럼으로 변환
df.withColumn(
'max_date',
F.to_date(F.max('proc_ymd'), "yyyyMMdd")
)
# 8 - 날짜 차이 계산
df.withColumn(
'date_diff',
F.datediff(
F.to_date(F.max('proc_ymd'), "yyyyMMdd"),
F.to_date(F.min('proc_ymd'), "yyyyMMdd")
)
)
# 9 - datetime 출력 형식 변환
df.withColumn('col_ymd', F.date_format(F.col('col_a'), 'yyyy-MM-dd'))
# 10 - Row에 대한 증가하는 고유 번호 부여
df.withColumn('id', F.monotonically_increasing_id())🔹 11. Window
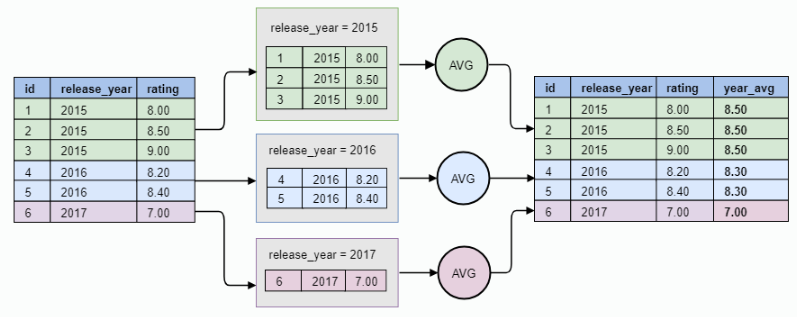
https://sparkbyexamples.com/pyspark/pyspark-window-functions/
- Window는 기본적으로 DataFrame의 특정 행들을 그룹핑하여 그룹핑된 행들의 집합을 대상으로 특정 작업을 수행한 후 하나의 값을 반환해준다.
- 특정 컬럼을 대상으로 그룹핑이 선행된 후 함수가 작동하기 때문에 함수들을 사용하기 위해서는 기준을 먼저 설정해주어야 한다.
- df가 특정 user들이 착용한 장비들의 가격을 나타내는 테이블이라고 가정할 때, user들의 착용 장비 가격에 대해서 순위가 매겨진 컬럼을 새로 생성하려 한다면 아래와 같은 순서에 따른다.
- user로 그룹핑되고, 장비 가격으로 정렬(order by)된 window 변수를 하나 생성한다.
- window 변수를 기준으로 Window의 row_number() 함수를 사용하여 가격 순위를 매기는 컬럼을 생성한다.
from pyspark.sql import window as W
# 1) window 변수 생성
w = \
W.Window \
.partitionBy("user") \ # 사용자들을 기준으로 그룹핑
.orderBy("price") # 그룹 내에서 정렬기준
# 2) 새로운 컬럼 생성
df = df.withColumn('price_rank', F.row_number().over(w))- window 집계시 사용할 수 있는 대표적인 함수들은 아래와 같다.
- row_number(), rank(), percent_rank(), dense_rank(), ntile(), cume_dist(), lag(), lead()
🔹 12. UDF(User Define Function)
- 사용자가 함수를 정의하고 그 함수의 기능대로 특정 컬럼의 값들을 가공할 수 있는 기능으로, pandas의
apply()와 비슷하다. returnType의 기본값은StringType()으로, UDF의 결과물이 문자형이면 명시해주지 않아도 되지만, 문자형 이외의 타입으로 최종 결과물이 return 된다면 반드시returnType을 명시해주어야 한다.
▪ 12-1) udf 변수 생성을 통한 정의
def double_string(val):
val = val * 2
return val
udf_a = F.udf(double_string, returnType = T.StringType())
df_udf = df.withColumn('double_col', udf_a(F.col('col_a')))▪ 12-2) Decorator 방식을 통한 정의
- 변수 선언이 필요 없고 기존 함수명 그대로 사용 가능
@F.udf(returnType = T.StringType())
def double_string(val):
val = val * 2
return val
df_udf = df.withColumn('double_col', double_string(F.col('col_a')))🔹 13. 기타 및 심화 기능
▪ 13-1) 컬럼 이름 일괄 변환
change_cols = ['col_a', 'col_b', 'col_c', ...]
df.toDF(*change_cols)▪ 13-2) pyspark DF와 Pandas DF 변환
# pyspark DataFrame --> Pandas DataFrame : toPandas()
pdf = df3.toPandas()
# pyspark DataFrame <-- Pandas DataFrame : spark.createDataFrame()
sdf = spark.createDataFrame(pdf)▪ 13-3) SUMMARY & DESCRIBE
- Dataframe 데이터에 대한 산술적인 통계치를 보여주는 함수이다.(count, mean, stddev, min, max 등)
describe(): 숫자형 컬럼에 대한 기본적인 요약 통계량을 계산summary(): 숫자형 컬럼에 대한 더 넓은 범위의 통계량을 계산
# descirbe
df.describe().show()
df.describe("num1").show()
# summary
df.summary().show()
df.summary("count", "33%", "50%", "66%").show()
df.select("num1").summary("count", "33%", "50%", "66%").show()
데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD
오! 기본 개념 잡기가 좋네요. spark 이제 조금씩 하고 있는데 참고하겠습니다!