
0. INTRO
- 하나의 모델을 최적화하기 위해서는 수십, 수백번의 Trial&Error 과정이 필요합니다. 이러한 조정 과정에서 각 테스트별로 쓰인 하이퍼파라미터나 기타 파라미터, 학습 시간, 모델별 성능 비교 등에 대한 내용을 일일히 기록하는 것은 상당히 번거롭고 힘든 일입니다.
- 하지만 이러한 기록 작업은 모델을 최적화하는데 있어서 굉장히 중요한 요소로 작용합니다.
- MLflow를 활용하면 아래의 반복적이 작업들에 대해 일정 부분 자동화가 가능하여 모델 학습 이력 추적 및 개발 모델 관리를 아주 편리하게 할 수 있습니다.
- 학습별 하이퍼파라미터에 대한 기록
- 모델 학습 시간 기록
- 정확도, 손실, F1 스코어 등의 모델 메트릭 기록
- 모델 파일, 학습 데이터, 시각화 자료 등 개발 관련 자료들을 아티팩트로 저장하여 관리
- 개발된 모델 객체를 버전별로 레지스트리에 저장하고 관리
- 각 실험에 대한 결과를 한눈에 비교할 수 있는 UI 제공
- 사용자 지정 지표, 함수, 그래프 등을 로그하여 다양한 정보 기록 가능
1. 분류 모델 개발
- sklearn의
load_digitsdataset을 활용하여 다중 분류 모델을 먼저 간단하게 만들어본다.
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
from sklearn.ensemble import RandomForestClassifier
## 1. 데이터 로드
digit = load_digits()
X = digit.data
y = digit.target
## 2. 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 20)
## 3. 모델 객체 생성
rf = RandomForestClassifier(
n_estimators = 10,
max_depth=4,
criterion = 'entropy',
random_state = 0
)
## 4. 학습 및 score 확인
rf.fit(X_train, y_train)
print(rf.score(X_train, y_train))
print(rf.score(X_test, y_test))
## 5. classification report 생성
y_pred = rf.predict(X_test)
report = classification_report(y_test, y_pred, output_dict=True)
pd.DataFrame(report)
---
0.9807692307692307
0.8867924528301887
1 2 3 accuracy macro avg weighted avg
precision 0.714286 1.000000 0.882353 0.886792 0.865546 0.895354
recall 0.833333 0.956522 0.833333 0.886792 0.874396 0.886792
f1-score 0.769231 0.977778 0.857143 0.886792 0.868050 0.889589
support 12.000000 23.000000 18.000000 0.886792 53.000000 53.0000002. MLflow 적용
- 위에서 만든 분류 모델에 대하여 MLflow를 적용하여 모델 관련 내용들을 기록하고 웹에서 확인해본다.
- 기록의 용이성을 위해 모델 관련 하이퍼파라미터나 classification report 관련 내용들에 대하여 추가적인 가공을 통해 dict 형식으로 보여질 수 있도록 한다.
1) mlflow 라이브러리 설치
pip install mlflow
2) mlflow 베이스 코드 작성(sklearn)
- 아래 코드와
train_test_split적용된 데이터에 대하여RandomForestClassifier를 적용하여 score 및 report를 생성한 후 관련 내용들을 MLflow에 기록할 수 있도록 하는 기본 코드를 작성해보았다. - 이후 모델 Load시 편의성을 위해 코드 하단부
모델 저장파트에서log_model()의 인자 중artifact_path = "model"로 통일한다.(이외 설정시 이후 모델 load시 코드가 까다로워질 수 있음)
import mlflow
# 실험에 대한 제목 (대제목)
experiment_name = "digit_classification"
# 실험 모델 관련 하이퍼파라미터 정보(dict)
params = {
"n_estimators" : 50,
"max_depth" : 5,
"criterion" : 'gini',
"random_state" : 20
}
# 실험명 설정하여 MLflow 실험 시작
mlflow.set_experiment(experiment_name)
with mlflow.start_run(
run_name="RandomForest_model", # 실험에 대한 세부 제목(중제목)
tags={"type" : "classification", "dataset" : "digit"}, # 실험 관련 태그 설정
description="digit data classification" # 실험 관련 설명
):
# 모델 초기화 및 학습
model = RandomForestClassifier(**params)
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, output_dict=True)
# 기록의 편의성을 위해 report 내용 중 필요한 값들만 dict 형식으로 재생성
report_dict = {
"accuracy" : report['accuracy'],
**{f"macro_{i}":j for i,j in report['macro avg'].items()},
**{f"weighted_{i}":j for i,j in report['weighted avg'].items()},
}
# MLflow에 파라미터와 메트릭 기록
mlflow.log_metrics(report_dict)
mlflow.log_params(params)
# 모델 저장
mlflow.sklearn.log_model(
sk_model = model,
artifact_path = "model"
)- 실행을 시키면 아래와 같은 로그가 나오고 해당 코드가 있는 파일과 동일 위치에
mlruns라는 폴더가 자동으로 생성된다.2024/11/04 14:34:10 INFO mlflow.tracking.fluent: Experiment with name 'digit_classification' does not exist. Creating a new experiment. 2024/11/04 14:34:18 WARNING mlflow.models.model: Model logged without a signature and input example. Please set `input_example` parameter when logging the model to auto infer the model signature.
3) mlflow UI 확인
-
개발하는 위치에서 터미널을 연 후
mlflow ui명령어를 치면localhost:5000주소로 mlflow UI를 확인할 수 있다.mlflow ui
-
localhost:5000에 접속해보면 우측 Experiment 섹션에 우리가 지정한experiment_name이 들어가 있는 것이 보이고, Run Name에는 우리가mlflow.start_run시 지정한run_name이 들어간 것을 확인할 수 있다.

-
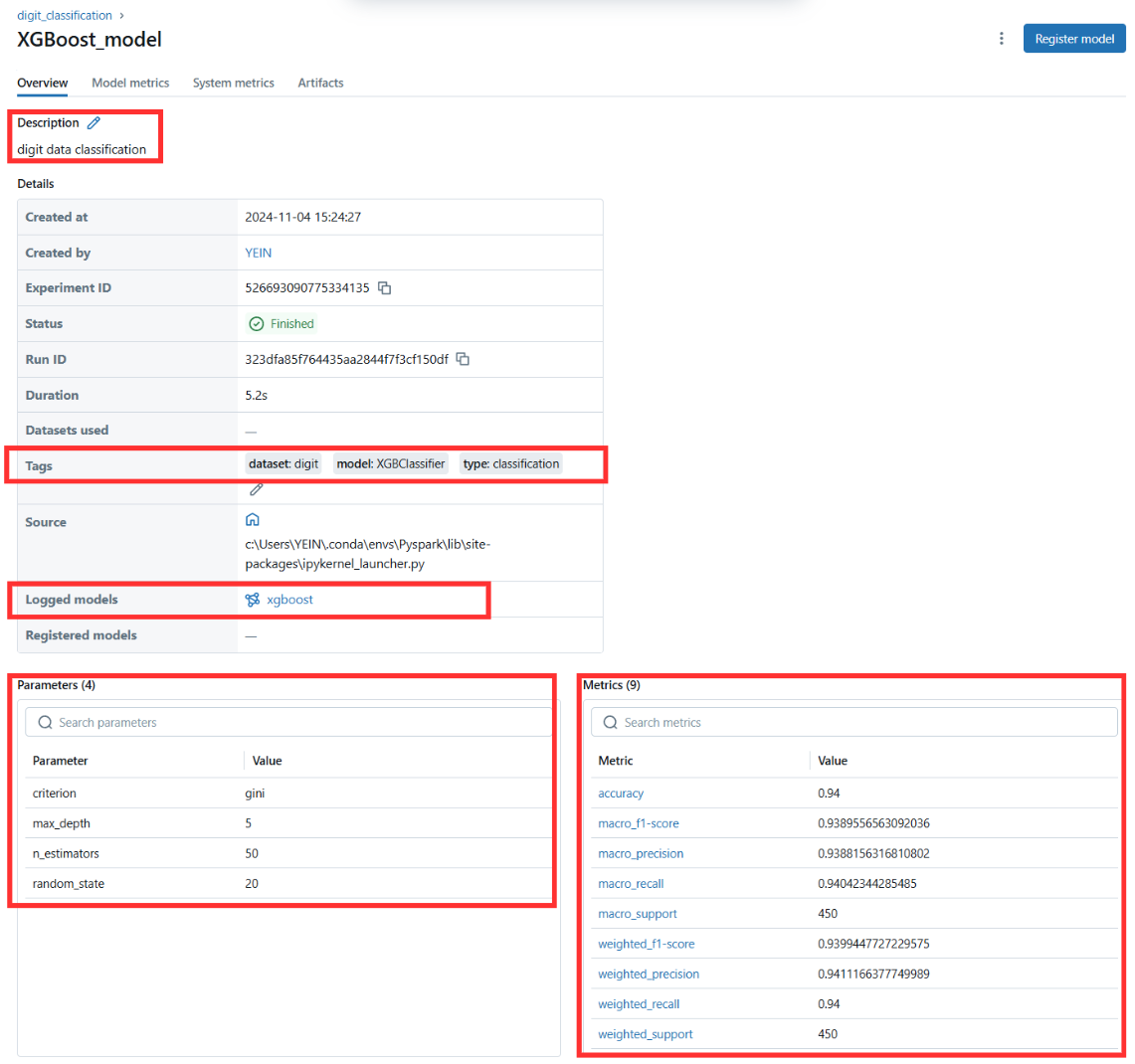
RandomForest_model을 클릭하여 들어가보면 해당 모델에 대한 파라미터, 태그, 설명 등 세부적인 정보들을 추가적으로 확인해볼 수 있다.

4) xgboost 모델 추가
- 위에서는 sklearn에서 지원하는
RandomForestClassifier모델을 사용하였는데, 이 경우에는mlflow.sklearn패키지 아래에 있는 함수를 사용하여 모델에 대한 저장 및 로깅 작업을 수행하였다. - xgboost 관련 모델에 대한 로깅 및 저장을 위해서는
mlflow.xgboost패키지를 활용하여야 하는데, 아래는XGBClassifier를 활용한 모델 실험 코드이다.
import mlflow
from xgboost import XGBClassifier
# 실험에 대한 제목 (대제목)
experiment_name = "digit_classification"
# xgboost 실험 모델 관련 하이퍼파라미터 정보(dict)
xgb_params = {
"n_estimators" : 10,
"max_depth" : 3,
"learning_rate" : 0.4,
"random_state" : 20
}
# 실험명 설정하여 MLflow 실험 시작
mlflow.set_experiment(experiment_name)
with mlflow.start_run(
run_name="XGBoost_model", # 실험에 대한 세부 제목(중제목)
tags={"type" : "classification", "dataset" : "digit", "model" : "XGBClassifier"}, # 실험 관련 태그 설정
description="digit data classification" # 실험 관련 설명
):
# 모델 초기화 및 학습
model = XGBClassifier(**xgb_params)
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, output_dict=True)
# 기록의 편의성을 위해 report 내용 중 필요한 값들만 dict 형식으로 재생성
report_dict = {
"accuracy" : report['accuracy'],
**{f"macro_{i}":j for i,j in report['macro avg'].items()},
**{f"weighted_{i}":j for i,j in report['weighted avg'].items()},
}
# MLflow에 파라미터와 메트릭 기록
mlflow.log_metrics(report_dict)
mlflow.log_params(xgb_params)
# 모델 저장
mlflow.xgboost.log_model(
xgb_model = model,
artifact_path = "model"
)
3. 실험 모델 저장
- MLflow의 Registry에 개발한 모델을 이름붙여 따로 저장할 수 있다.
1) 해당 실험의 run 이력 검색
- 하나의 실험 아래에 여러개의 run이 있을 수 있기 때문에 모델 저장을 위해서는 어떤 run에서 생성된 모델이라는 것을 특정해주어야 한다.
- 여기서
experiment_name은 위에서 지정해준 변수의 값과 동일하다.
experiment_info = mlflow.set_experiment(experiment_name)
## 특정 실험에 대한 정보를 dataframe 형태로 반환
runs_df = mlflow.search_runs(
experiment_ids=experiment_info.experiment_id
)2-1) sklearn 모델을 registry에 저장
- run_id가 특정된 모델을 mlflow의 registry에 저장합니다.
- run_id는 실험(experiment) 내의 학습(run)중에서 가장 최근의 학습을 사용하도록 설정합니다.
## 조건에 맞는 run_id를 찾아 변수에 저장
run_id = runs_df[runs_df['tags.mlflow.runName'] == 'RandomForest_model'].sort_values("start_time")['run_id'].values[0]
model_uri = f'runs:/{run_id}/model'
model_name = "RandomForest_normal"
## sklearn의 RandomForest 모델을 registry에 저장
with mlflow.start_run(run_id=run_id):
mlflow.register_model(
model_uri=model_uri,
name=model_name,
tags={"model_type": "sklearn", "type" : "classification"} # 모델에 대한 태그 설정
)2-2) xgboost 모델을 registry에 저장
## 조건에 맞는 run_id를 찾아 변수에 저장
run_id = runs_df[runs_df['tags.mlflow.runName'] == 'XGBoost_model'].sort_values("start_time")['run_id'].values[0]
model_uri = f'runs:/{run_id}/model'
model_name = "XGBClassifier_normal"
## xgboost의 XGBoostClassifier 모델을 registry에 저장
with mlflow.start_run(run_id=run_id):
mlflow.register_model(
model_uri=model_uri,
name=model_name,
tags={"model_type": "xgboost", "type" : "classification"} # 모델에 대한 태그 설정
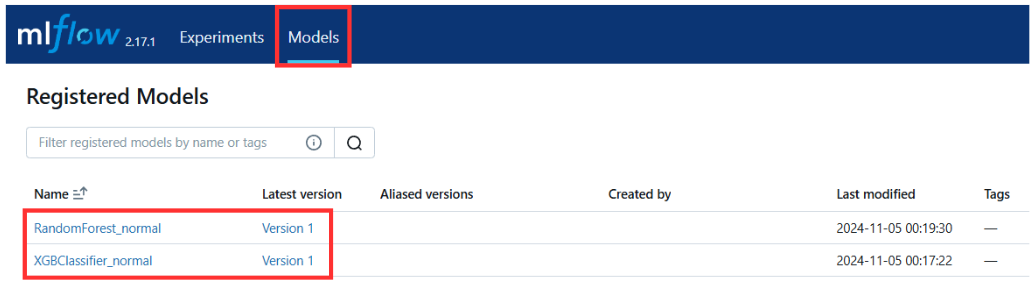
)3) 저장된 모델 확인
- MLflow UI 상단의
models탭에 들어가면 저장된 모델을 확인활 수 있다. - 같은 이름으로 여러번 저장하게되면 자동으로 version이 올라간다.
4. 저장한 모델 불러오기
- Registry에 저장된 모델을 불러오기 위해서는 아래의 두 가지 정보가 필요하다.
- 실험에 대한 ID (experiment id)
- 학습에 대한 ID (run id)
1) 저장된 모델 확인
model_name = "RandomForest_normal"
saved_models = mlflow.search_registered_models(
filter_string=f"name = '{model_name}'",
)
dict(saved_models[0])
---
{'aliases': {},
'creation_timestamp': 1730733570407,
'description': None,
'last_updated_timestamp': 1730733570466,
'latest_versions': [<ModelVersion: aliases=[], creation_timestamp=1730733570417, current_stage='None', description=None, last_updated_timestamp=1730733570417, name='RandomForest_normal', run_id='b372d9cd245444bda727c0847f3927f5', run_link=None, source='file:///d:/%EC%BD%94%EB%93%9C%EC%9E%87/dev/ML_Lecture/11.MLflow/mlruns/595006786249354016/b372d9cd245444bda727c0847f3927f5/artifacts/model', status='READY', status_message=None, tags={'model_type': 'sklearn', 'type': 'classification'}, user_id=None, version=1>],
'name': 'RandomForest_normal',
'tags': {}}2) 저장된 모델 불러오기
sklearn라이브러리의 모델이냐,xgboost라이브러리의 모델이냐에 따라서 코드가 약간 다르다.
model_uri = f"models:/{model_name}/latest
## 1) sklearn 모델
loaded_model = mlflow.sklearn.load_model(model_uri)
## 2) xgboost 모델
loaded_model = mlflow.xgboost.load_model(model_uri)- 불러온 모델은 아래 코드 형태로 사용하여 데이터셋에 대한 예측을 수행할 수 있다.
y_pred = loaded_model.predict(X_test)
classification_report(y_test, y_pred, output_dict=True)5. 참고 자료

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD