
주제
- 차량 파손 여부 분류하기
목표
- Data Preprocessing(1일차)
- CNN 모델링(2일차)
- Data Augmentation & Transfer Learning
개인 목표
- 모델링 수행 과정 체계적으로 작성하기
- 결과 파일 및 폴더 일관성있게 정리하기
- VGG, ResNet 등 3개 이상 모델 사용해보기
0. X, y
X
1) 이미지 파일 목록 가져오기
img_list = os.listdir(이미지가 담긴 폴더 위치)2) 이미지 배열로 만들기
방법 1
- Tensorflow의 이미지 전처리 및 조작에 사용되는 모듈 활용
from tensorflow.keras.preprocessing.image import img_to_array, load_img
img = load_img('이미지파일의 경로', target_size=(이미지의 대상 크기), color_mode='컬러 모드')
img_array = img_to_array(img)- 'load_img' 함수는 이미지 파일을 로드하고 PIL(Python Imaging Library) 이미지 객체를 반환
- 'img_to_array' 함수는 PIL 이미지 객체를 Numpy 배열로 변환
def img_transfer(img_list, img_path):
arr = []
for f in img_list:
img = load_img(img_path + f, target_size = (img_size, img_size), color_mode = 'rgb')
arr.append(img_to_array(img))
return arr방법 2
- PIL: 이미지 처리와 조작을 위한 라이브러리
- Image: PIL 라이브러리의 모듈 중 하나
from PIL import Image
img = Image.open('이미지파일의 경로')
img.save('새로운이미지파일의 경로')
new_img = img.resize((width, height))
cropped_img = img.crop((left, upper, right, lower)) # 이미지 일부 영역 잘라내기
rotated_img = img.rotate(45)
converted_img = img.convert('L')- 'open()' 을 통해 이미지를 불러오고 resize 적용 후 'img_to_array'를 통해 배열로 변환
def img_transfer(img_list, img_path):
arr = []
for f in img_list:
img = Image.open(img_path + f)
img_resized = img.resize((img_size, img_size))
arr.append(img_to_array(img_resized))
return arr3) 배열(list) -> numpy 배열
x_train = np.array(x_train)y
- 파일 이름이 'ab'로 시작 -> 1
- 그 외 -> 0
def make_label(img_list):
arr = []
for val in img_list:
if val.startswith('ab_'):
arr.append(1)
else:
arr.append(0)
return arr- X와 마찬가지로 numpy 배열로 변환해주어야 함
1. 모델링
모델 1
- Functional API
- 레이어를 묶어서 각각 하나의 함수로 구현
keras.backend.clear_session()
il = Input(shape=(img_size, img_size, 3))
def conv1_layer(x):
x = ZeroPadding2D(padding=(3, 3))(x)
x = Conv2D(64, (7, 7), strides=(2, 2))(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = ZeroPadding2D(padding=(1,1))(x)
return x
# 중략 #
x = conv1_layer(il)
x = conv2_layer(x)
x = conv3_layer(x)
x = conv4_layer(x)
x = conv5_layer(x)
x = Flatten()(x)
x = Dense(256, activation = 'relu')(x)
x = Dropout(0.5)(x)
x = Dense(128, activation = 'relu')(x)
x = Dense(18,activation = 'relu')(x)
ol = Dense(1, activation='sigmoid')(x)
model1 = Model(il, ol)
model1.compile(loss = 'binary_crossentropy',
metrics = ['accuracy'] ,
optimizer = keras.optimizers.Adam(learning_rate = 0.0001))
학습 과정
- Early Stopping, ReduceLROnPlateau 적용
- ModelCheckpoint로 가장 좋은 모델 저장
history1 = model1.fit(x_train, y_train,
validation_data=(x_valid, y_valid),
callbacks=[es, mcp, lr],
epochs=10000,
verbose=1)학습 결과
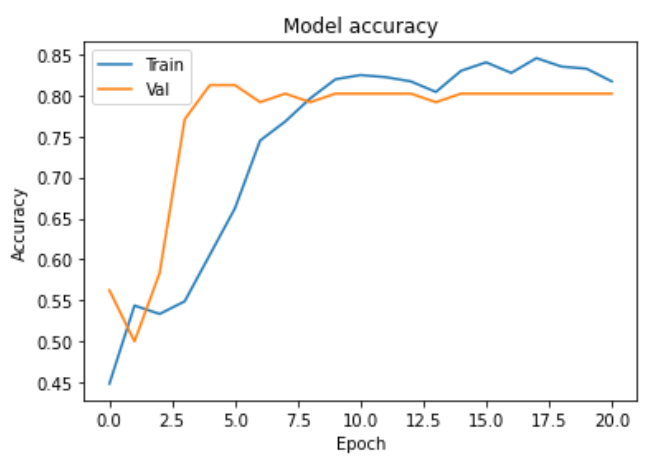
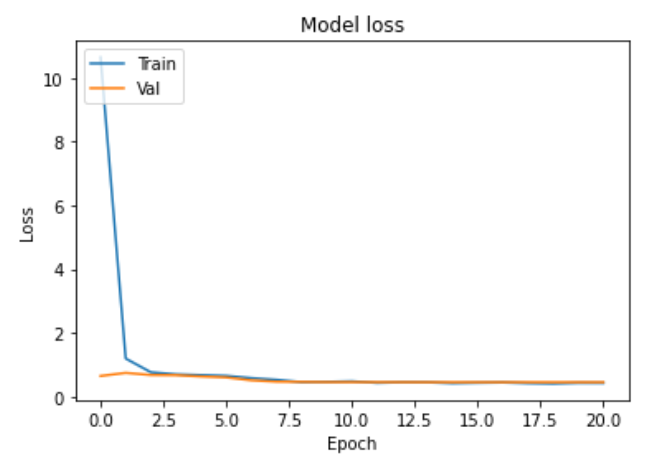
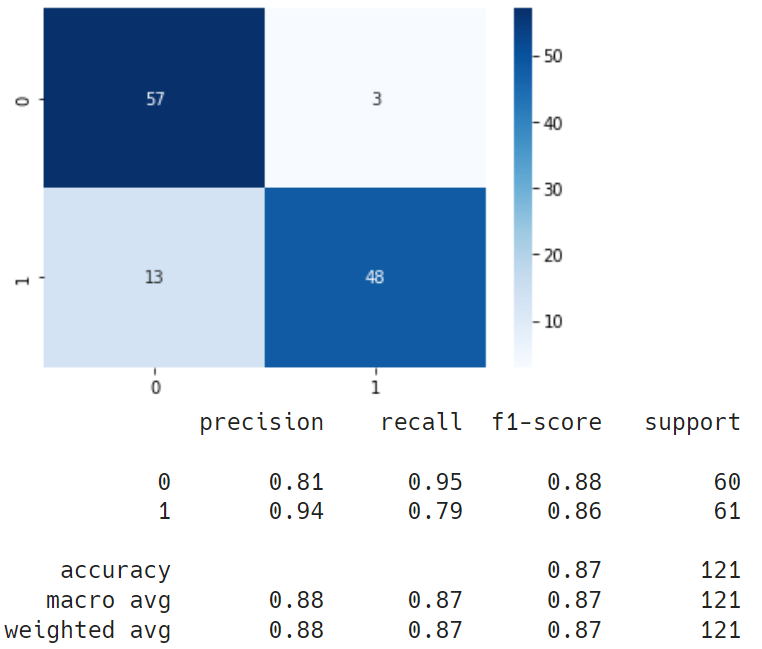
특이사항

- 학습 도중 val_accuracy가 고정되는 문제 발생 -> 오버피팅 예상
- BatchNormalization()을 사용하면 더 낮은 val_accuracy에서 고정됨 -> BatchNorm이 부정적 영향
모델 2
- Sequential API
- add 대신 레이어를 리스트에 넣어 Sequential에 넣어줌
keras.backend.clear_session()
model3 = keras.models.Sequential([
Input(shape=(img_size, img_size, 3)),
Conv2D(filters = 64, kernel_size = (5,5),padding = 'same', activation= 'relu'),
MaxPooling2D(pool_size = (2,2), strides = (2,2)),
Conv2D(128, (5,5), padding = 'same', activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Conv2D(256,(5,5), padding = 'same', activation = 'relu'),
MaxPooling2D(pool_size = (2,2), strides=(2,2)),
Flatten(),
Dense(256,activation = 'relu'),
Dropout(0.5),
Dense(128,activation = 'relu'),
Dense(1,activation = 'sigmoid')])
model3.compile(loss='binary_crossentropy',
optimizer = keras.optimizers.Adam(learning_rate = 1e-4),
metrics=['accuracy'])
학습 과정
- Early Stopping, ReduceLROnPlateau 적용
- ModelCheckpoint로 가장 좋은 모델 저장
history1 = model1.fit(x_train, y_train,
validation_data=(x_valid, y_valid),
callbacks=[es, mcp, lr],
epochs=10000,
verbose=1)학습 결과
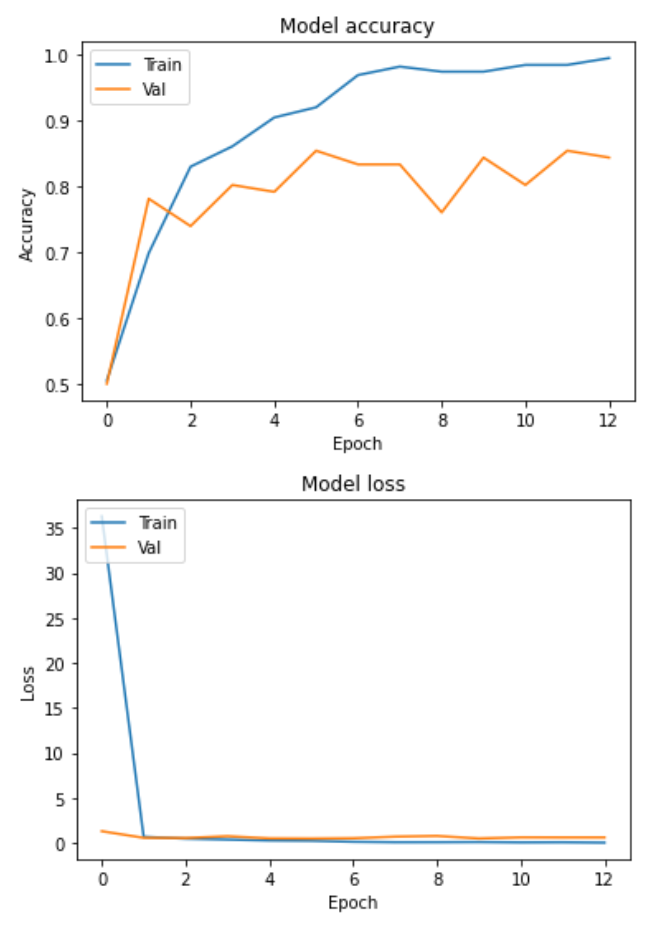
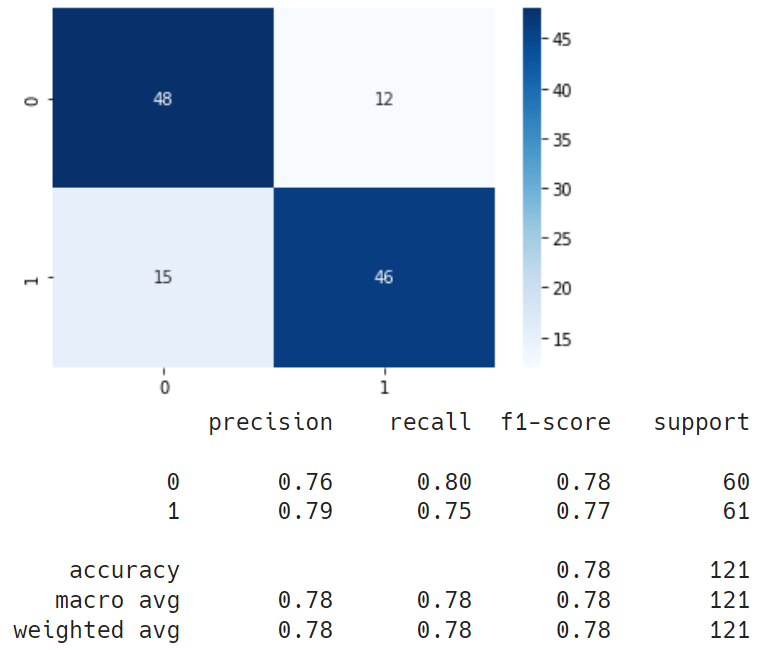
어려웠던 부분
- val_accuracy가 0.5 등 하나의 값에서 달라지지 않는 현상
- 오버피팅 또는 언더피팅의 가능성
- 하이퍼파라미터 조정 필요
- batchNormalization의 영향
- Learning_rage 조절을 통해 해결하였음
- 더불어, ReduceLROnPlateau의 'monitor' 대상에 'val_accuracy'를 넣어 learning_rate를 유동적으로 바꿀 수 있도록 하였음
마무리
- 이미지의 수가 605장이기 때문에 모델의 복잡도와 상관없이 일정 성능을 넘기지 못하는 것으로 보임
- Augmentation을 통해 이미지 증강을 시도하여 학습한 결과, 성능이 개선됨을 확인할 수 있었음
- ResNet, VGG, EfficientNet 등을 시도해보았고, 내일 더 확인해볼 예정

A smooth sea never made a skilled sailor