
주제
- 차량 파손 여부 분류하기
목표
- Data Preprocessing(1일차)
- CNN 모델링(2일차)
- Data Augmentation & Transfer Learning(3일차)
개인 목표
- 모델링 수행 과정 체계적으로 작성하기
- 결과 파일 및 폴더 일관성있게 정리하기
- VGG, ResNet 등 3개 이상 모델 사용해보기
1. Data Augmentation
ImageDataGenerator
객체 생성하기
train_datagen = ImageDataGenerator(
rescale=1./255, # 이미지 픽셀값 0~255를 0~1로 정규화
rotation_range=10, # 이미지 회전 각도 범위
zoom_range=0.3, # 이미지 확대/축소 범위
brightness_range=[0.5, 1.5], # 이미지 명도 범위
channel_shift_range=50, # 이미지 채도 범위
horizontal_flip=True, # 수평 방향으로 이미지 뒤집기
vertical_flip=True, # 수직 방향으로 이미지 뒤집기
fill_mode='nearest' # 이미지 변환 후 빈 영역을 채우는 방법
)
valid_datagen = ImageDataGenerator(
rescale=1./255,
)
test_datagen = ImageDataGenerator(
rescale=1./255,
)- 목표: train_datagen의 파라미터를 조정해보면서 가장 좋은 성능을 보이는 조합 찾기
- validation dataset에 증강을 적용하는 경우, 현실의 실제 데이터에 적용시킬때 성능이 떨어질 수 있음
- validation과 test에는 rescale만 적용
데이터 생성기 만들기
flow_from_directory
- 폴더 구조를 기반으로 이미지 데이터를 생성
- 디렉토리에서 데이터를 읽고 전처리를 수행한 뒤 배치 단위로 반환
- 따라서 normal/abnormal 데이터가 폴더별로 저장되어 있어야 함
train_generator = train_datagen.flow_from_directory(
train_path,
target_size=(img_size, img_size),
class_mode='binary',
shuffle = True,
)
valid_generator = train_datagen.flow_from_directory(
valid_path,
target_size=(img_size, img_size),
class_mode='binary',
shuffle = True,
)
test_generator = test_datagen.flow_from_directory(
test_path,
target_size=(img_size, img_size),
class_mode='binary',
shuffle = False,
)- test_generator는 예측 데이터 생성을 대비해 'shuffle = False'를 반드시 넣어주어야 함
flow
- numpy배열 형태의 이미지 데이터를 가져와 데이터를 생성할 때 사용
train_generator = datagen.flow(
x_train, y_train, # 입력 데이터 및 레이블
batch_size=32 # 배치 크기
)- 2일차에 진행한 X, y를 변환한 데이터에 적용
적용 결과
-
팀원과 실험한 결과, 파라미터를 많이 주고 변형을 많이 했을 때보다 변형이 적었을 때 성능이 더 좋았음
-
증강 없음 적은 변형 극단 변형 명도, 채도 변형 성능(Accurarcy) 0.85 0.89 0.84 0.79 -
이유
- 이미지에서 차량 파손 여부가 명확
- 이미지를 변형(확대, 축소) 과정에서 파손 여부를 확인하기 어렵게 바뀔 수 있음
2. Transfer Learning
일반적인 CNN의 구성
Convolutional base
- 합성곱층과 풀링층이 쌓여있는 부분
- 목표: 이미지로부터 특징을 효과적으로 추출하는 것
(feature extraction)
ㅤ
Classifier
- 주로 완전 연결 계층 (fully connected layer)로 구성
- 목표: 추출된 특징을 잘 학습해서 이미지를 분류하는 것 (image classification)
Four types of fine-tuning
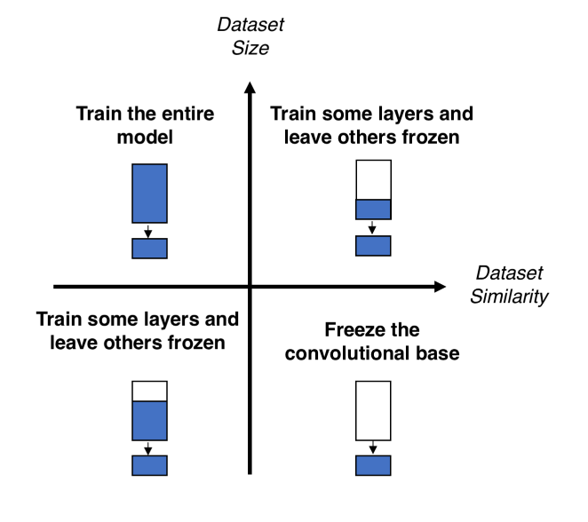
제 1사분면
- 타겟데이터가 학습데이터와 유사, 양이 많을 경우
- Pre-trained feature를 어느 정도 재사용 가능
- Pre-trained 모델의 Feature extractor 후반부와 Classifier 부분을 학습
제 2사분면
- 타겟데이터가 학습데이터와 유사하지 않고, 양이 많은 경우
- Pre-trained feature를 대폭 수정 필요
- 데이터가 많으므로 Pre-trained 모델 전체를 추가학습
제 3사분면
- 타겟데이터가 학습데이터와 유사하지 않고, 양도 적을 경우
- Pre-trained feature를 대폭 수정 필요
- 모델의 대부분을 추가학습
- 데이터가 많지 않으므로, 초반 일부분은 그대로 둠
- 이유: 초반 레이어들은 edge와 같은 specific한 정보를 담당
-> domain-independent한 정보를 갖는 경우가 많음
제 4사분면
- 타겟데이터가 학습데이터와 유사하지만, 양이 적을 경우
- Pre-trained feature를 그대로 사용 가능
- 데이터가 적으므로, Pre-trained model의 분류기 부분만 추가학습
이번 프로젝트는?
- 타겟 데이터와 학습 데이터가 매우 유사하지만, 데이터의 양이 많지 않음
- 'include_top = False', '.trainable = False'를 적용하는 것이 더 좋을 것으로 예상
callbacks
lr = ReduceLROnPlateau(monitor = 'val_accuracy',
factor = 0.1,
patience = 3,
verbose = 1,
mode = 'auto',
min_delta = 0.01,
min_lr = 0)
es = EarlyStopping(monitor = 'val_loss',
min_delta = 0.001,
patience = 7,
restore_best_weights = True,
verbose = 1)설정
-
Transfer Learning에서는 'include_top = False'로 설정하면 마지막 fully connected layer가 제거되고, 분류 레이어를 사용자가 직접 만들어 사용 가능(base_model의 layer를 Freeze한다고 표현)
-
base_model.trainable=False를 통해 pre-trained weights를 고정
-
설정 include_top .trainable True 분류 레이어를 포함 Fine-Tuning에 대해 업데이트 O False 분류 레이어를 제외 Fine-Tuning에 대해 업데이트 X
ResNet50
- 이미지 분류 작업에 주로 사용되는 CNN 모델
- 기존 ResNet에 비해 ResNet50은 복잡한 표현을 학습 가능하고, 정확도 또한 높음
base_model = ResNet50V2(weights='imagenet', include_top=False, input_shape=(img_size, img_size,3))
base_model.trainable = False
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(128, activation='relu')(x)
x = Dropout(0.2)(x)
predictions = Dense(1, activation='sigmoid')(x)
resnet50 = Model(inputs=base_model.input , outputs=predictions)
resnet50.compile(loss=keras.losses.binary_crossentropy,
metrics=['accuracy'],
optimizer= keras.optimizers.Adam(learning_rate = 0.0001))- Fine Tuning은 미적용(.trainable = False)
- Total params: 23,566,849
- Trainable params: 2,049
- Non-trainable params: 23,564,800
학습 과정
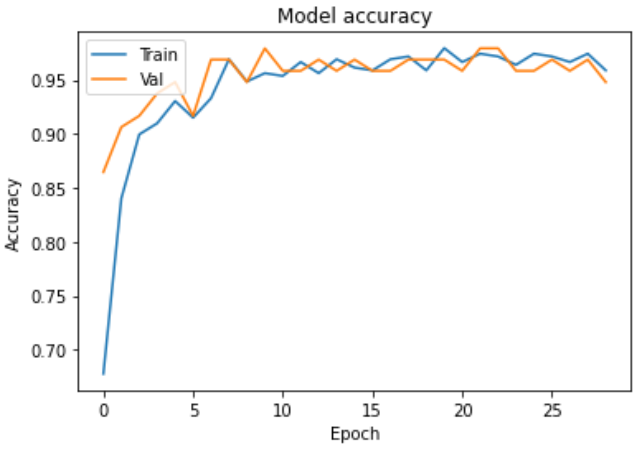
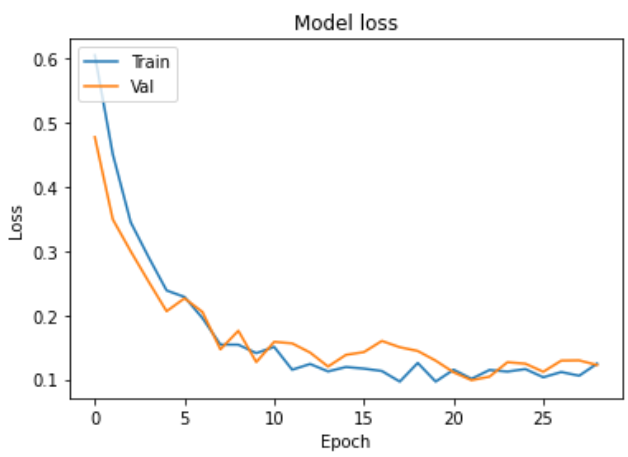
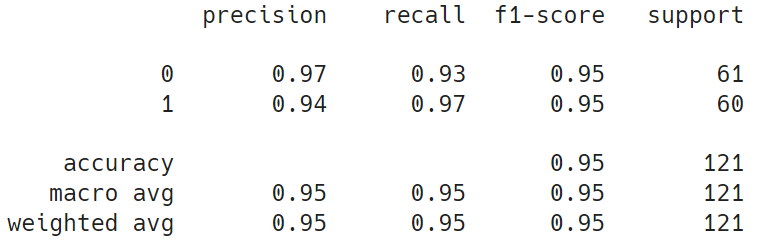
학습 결과
- Test loss: 0.1404
- Test accuracy: 0.9504
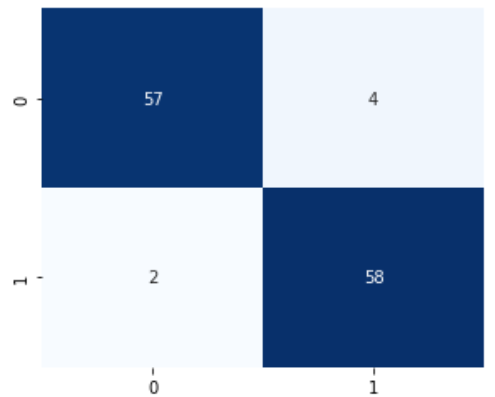
EfficientNetV2B0
- 이미지 분류 및 객체 감지에서 좋은 성능을 보이는 모델
- 적은 데이터에서도 좋은 성능을 발휘할 수 있음
keras.backend.clear_session()
base_model = EfficientNetV2B0(weights='imagenet', include_top=False, input_shape=(img_size, img_size,3))
base_model.trainable = True/False-
Fine Tuning은 적용/미적용 비교
-
Trainable Trainable Params Non-Trainable Params Total True 5.8M 0.06M 5.9M False 1281 5.9M 5.9M
학습 과정
Trainable = True
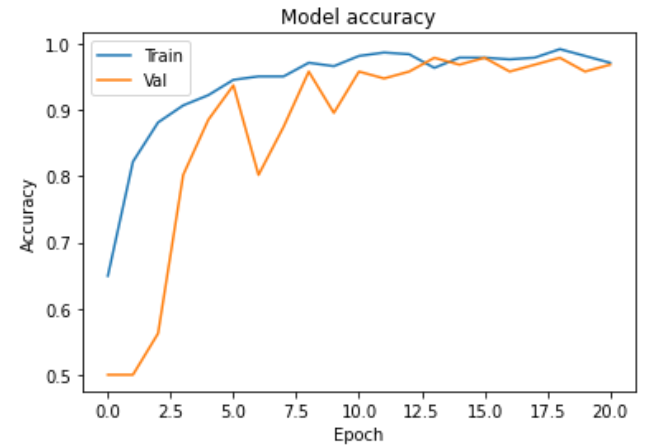
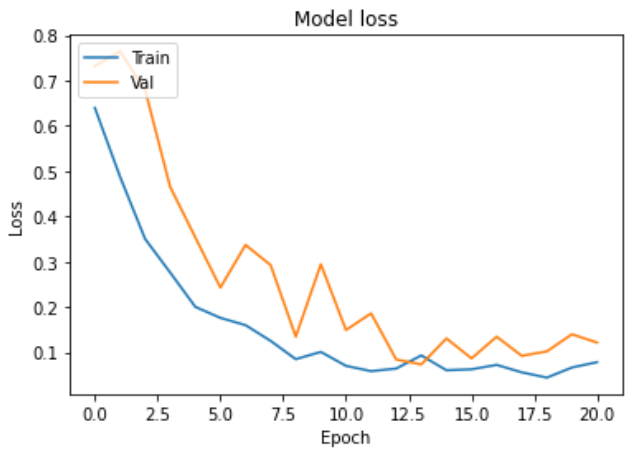
Trainable = False
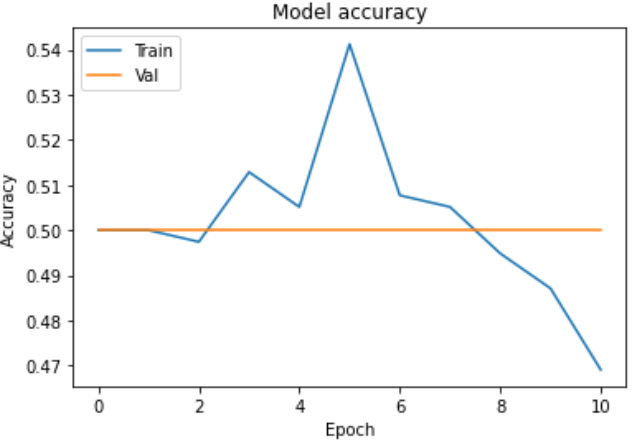
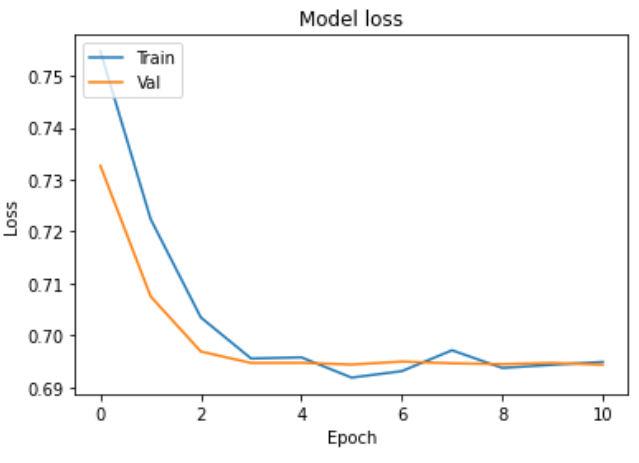 - val_accuracy가 0.5로 고정되는 문제 발생
- val_accuracy가 0.5로 고정되는 문제 발생
학습 결과
Trainable = True
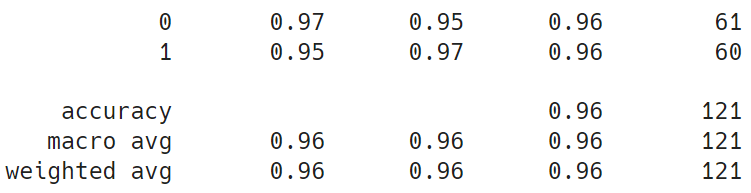
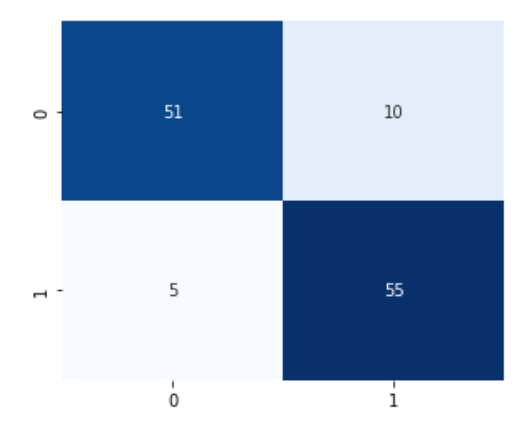
- Test loss: 0.1130
- Test accuracy: 0.9587
Trainable = False
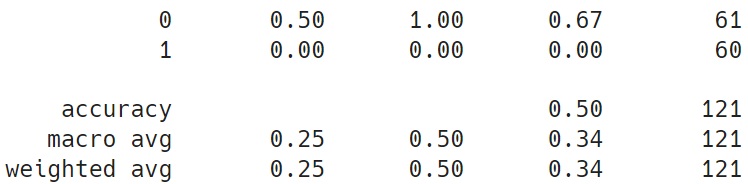
- Test loss: 0.6949
- Test accuracy: 0.5041
VGG16
- 작은 필터 크기와 깊은 신경망을 가지고 있는 모델
- 16개의 층 = 13개의 합성곱층 + 3개의 완전 연결층
- 일반적인 이미지 분류 문제에 대해서 성능이 높음
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(img_size, img_size,3))
base_model.trainable = False
x = base_model.output
x = Flatten()(x)
x = Dense(1024, activation = 'relu')(x)
x = Dropout(0.25)(x)
predictions = Dense(1 , activation='sigmoid')(x)- Fine Tuning은 미적용
- Total params: 67.1M
- Trainable params: 52.4M
- Non-trainable params: 14.7M
학습 과정
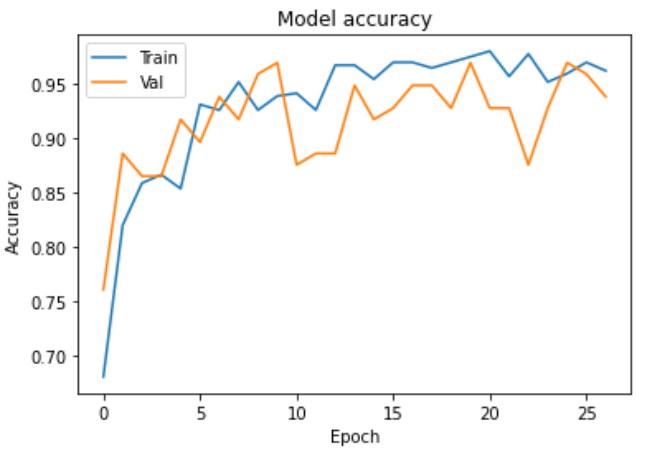
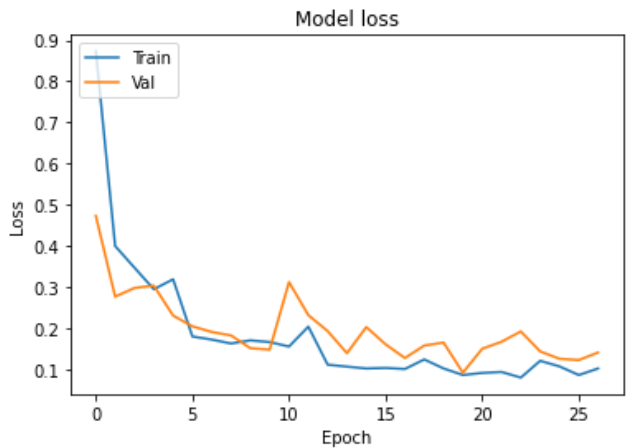
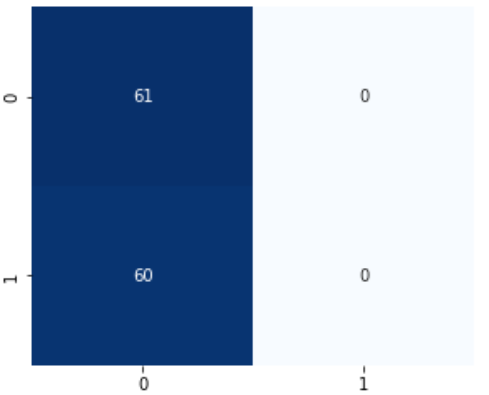
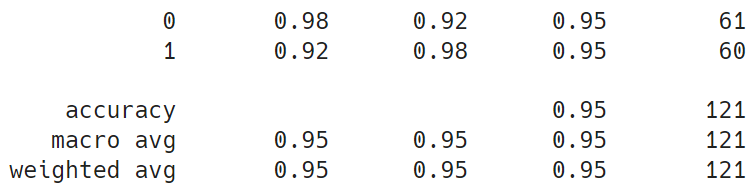
학습 결과
- Test loss: 0.1970
- Test accuracy: 0.9504
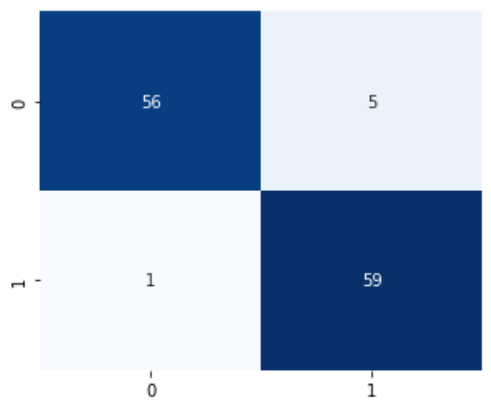
어려웠던 부분
- colab의 gpu 컴퓨팅 단위가 없어 학습 과정이 너무 오래 걸림
- 분류기를 설계하는 과정
- Flatten이나 GAP를 사용하지 않으면 성능이 나빠졌음
-Dropout을 적용했을 때 성능이 좋아짐
- Flatten이나 GAP를 사용하지 않으면 성능이 나빠졌음
- 데이터셋 크기가 작아 학습 과정이 조금만 틀어져도 오버피팅 발생
- 오버피팅을 방지하기 위한 방법들을 확인
마무리
- '.trainable = False'가 대체적으로 성능이 더 잘나오는 경향은 있으나, 다른 요인들에 의해 성능이 바뀔 수 있음
- 다양한 모델과 fine tuning의 조합을 시도해보는 것이 중요

A smooth sea never made a skilled sailor