[논문리뷰] Patch core _Towards Total Recall in Industrial Anomaly Detection
Back Ground
- AD의 Cold Start
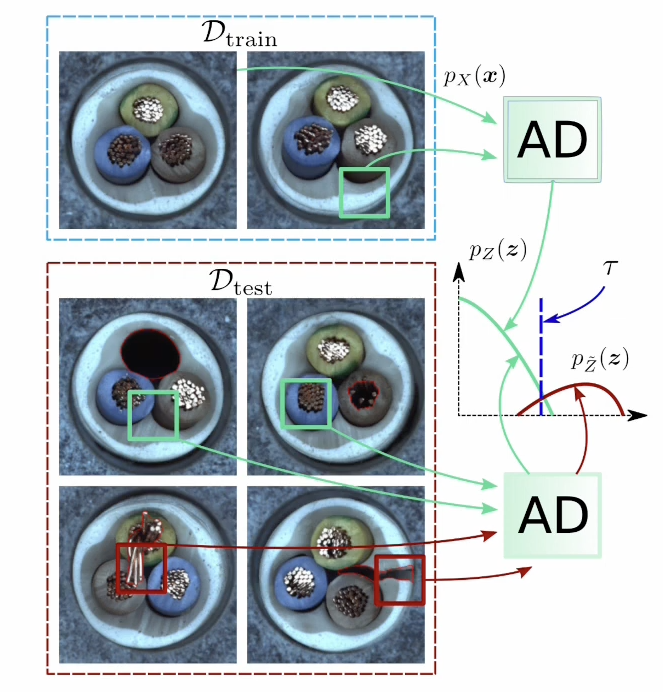
산업 환경에서의 Cold Start 이상 탐지는 다음과 같은 특징을 가진다
1. 정상 샘플만을 이용한 학습, 이상 데이터가 부족한 경우. (1-Class Classification)
2. 다양한 종류의 결함 탐지 (긁힘, 균열, 구조 변화 등등)
3. 특정 상황에서나 환경에서만 수집된 정상 데이터는 다른 상황에 잘 일반화 되지 않을 수 있음.
- AD의 주요 Approach (비지도)
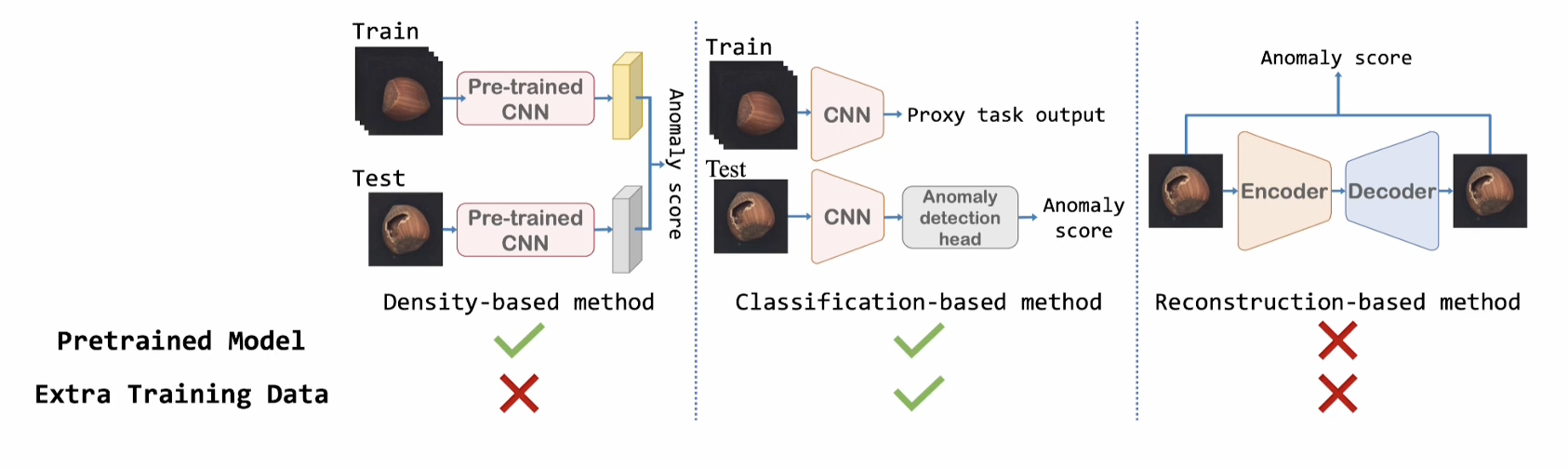
- Density - based method : 정상 데이터의 분포를 통해 비정상 데이터를 탐지
- 사전학습 모델을 통해서 feature맵을 추출하여 이상치 Anomaly Score을 계산
- Classification - based method : proxy task를 정의하여 사전학습 수행 후
1-Class Classification 적용하여 비정상 데이터 탐지
- 사전학습 모델을 사용하고 추가적인 학습 과정(Proxy task)을 적용
- Recontruction - based method: 정상 데이터만을 복원하도록 학습하여 비정상 데이터 추론 시 재구축된 결과와 차이로 비정상 데이터 탐지
- 정상 데이터로 부터 En,De를 통해 Anomaly Score 계산 (생성해낸 데이터와 새로운 데이터가 얼마나 차이가 나는가?)
-> Patch core은 Density - based method 모델이다.
- Related Work
PatchCore은 SPADE 모델과 PaDiM 모델을 기반으로 만들어졌는데, 해당 모델들을 간략하게 소개하면
- SPADE
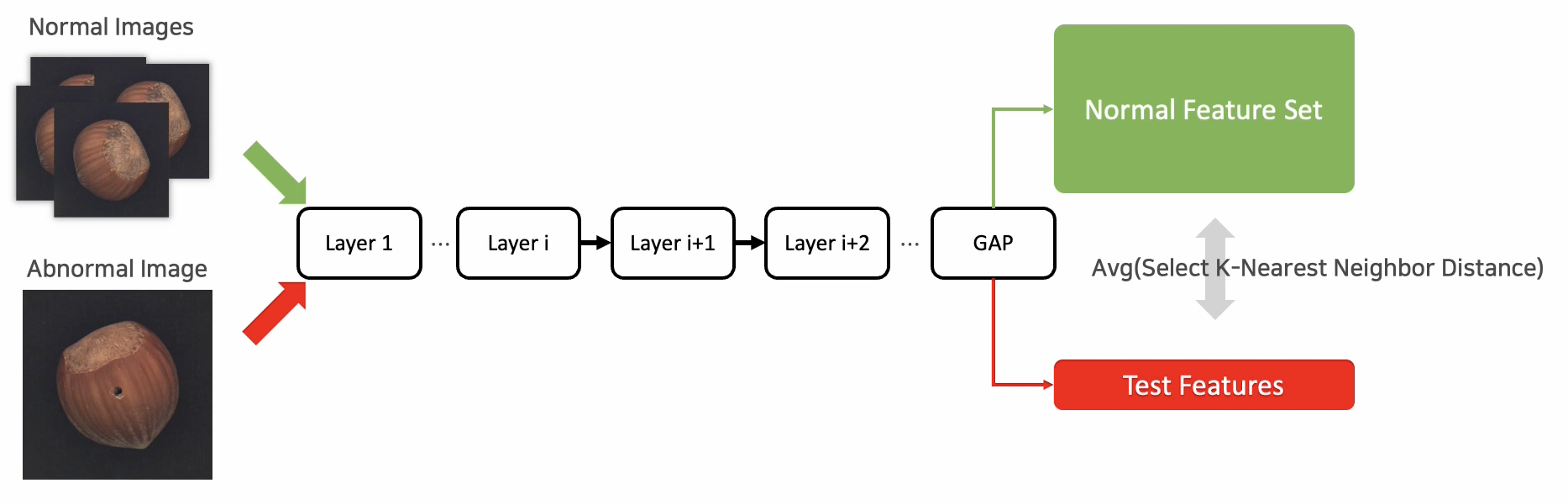
Density 기반 방법으로서 사전학습 모델만을 사용해서 정상데이터로부터 GAP를 거친 feature를 추출하고 이 feature들을 모두 모아서 이를 메모리 뱅크 에 저장하고, 새로운 데이터가 들어왔을때 GAP를 거친 feature(patch)의 Distance의 차이값을 AS로서 계산한다.
하지만 사전학습으로 추출한 feature을 그대로 사용하기 때문에 patch들이 주변정보없이 본인의 정보만 갖고 있다는 문제가 있다. 즉, patch끼리 locally aware하지 않다는 것이다.
- PaDiM
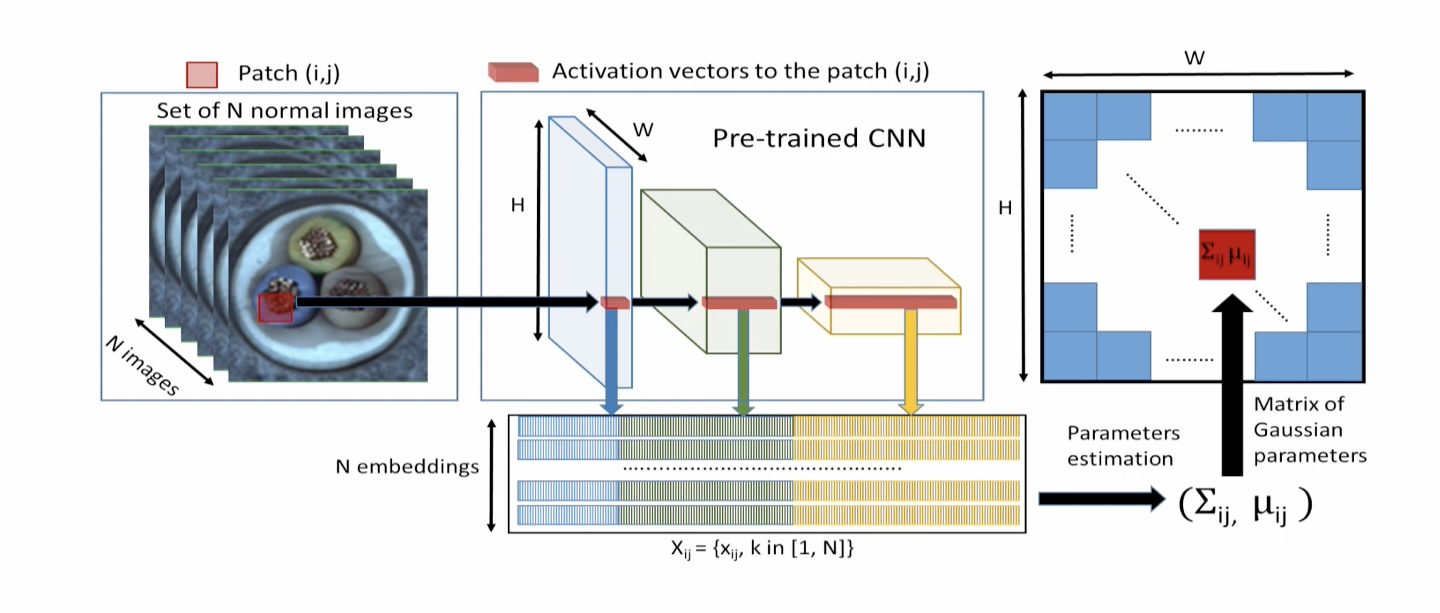
각 사전학습 모델의 Layer Output 을 가져와서 정상 데이터들에 대한 Feature map들을 모으고, 각 위치에 대해서 , , 을 계산하여 새 데이터가 들어왔을때 해당 위치에 대한 Feature map의 , , 에 대한 Mahalanobis distance를 계산하여 Anomaly Score를 계산한다.= -
두 점 사이의 거리를 데이터의 분포를 고려하여 정규화한 유클리드 거리
Padim은 동일 위치의 patch feature들 끼리만 비교하는 모습을 볼 수 있는데, 이때, Patch별로 alignment가 안맞는 데이터가 있을때 이는 치명적인 단점이 될 수 있다.
Method
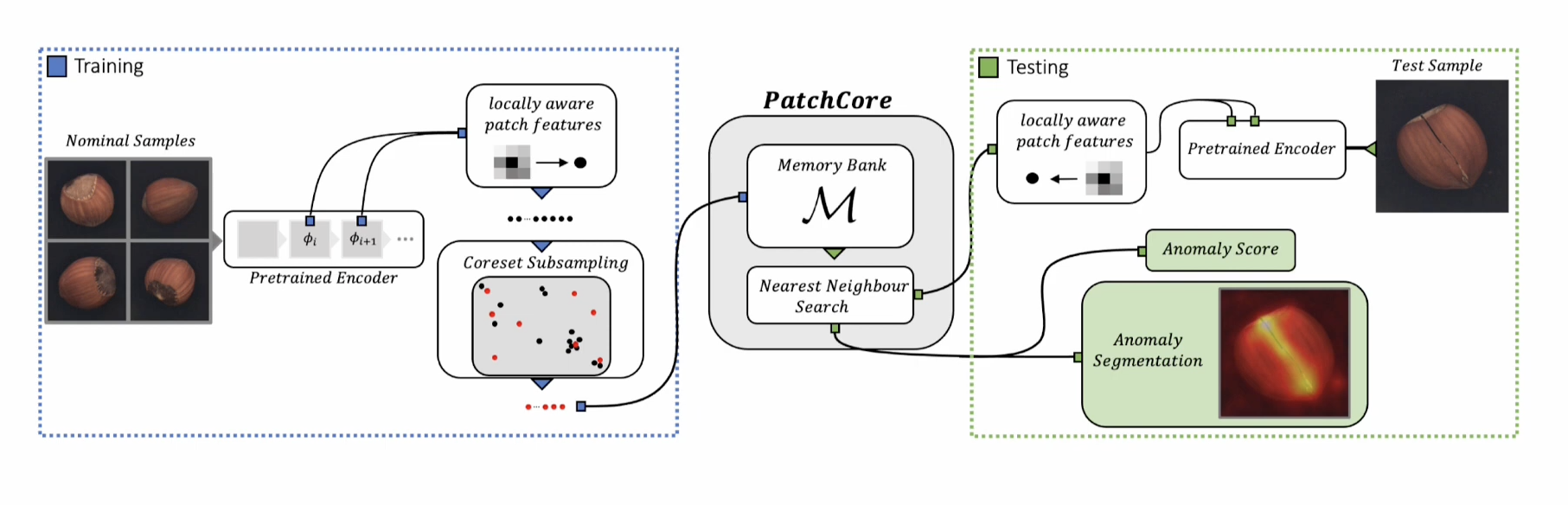
1. Local Patch Features
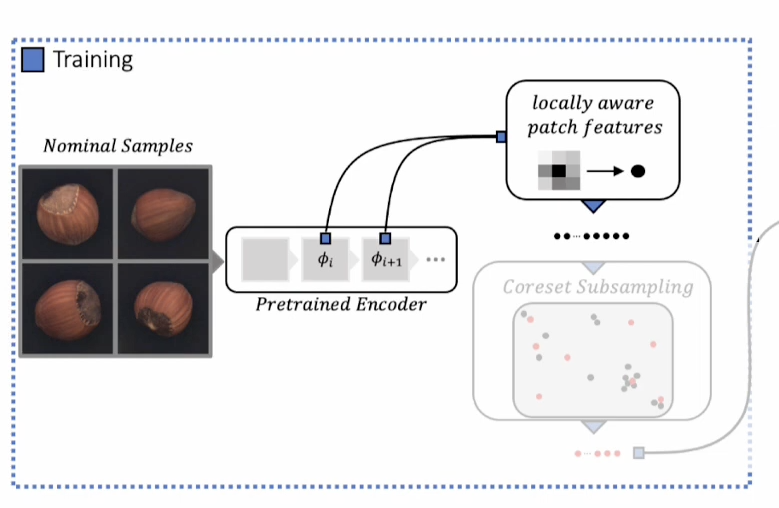
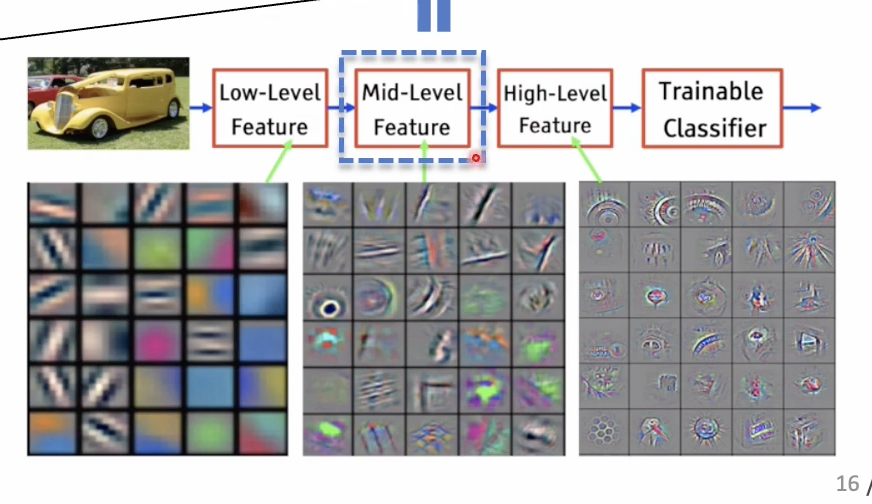
어떤 사전학습 모델로부터 Output Layer를 추출할 때 기존 많은 모델들은 High-level Feature를 추출하여 사용하였다.
그러나 High-level Feature를 사용하게 되었을 때, 해당 Feature은 이미 여러 Layer를 거치면서 Spatial한 정보가 많이 함축된 상태이므로 공간적 정보의 손실이 크고, 주로 Image Net classification을 통해서 사전학습을 하므로 해당 task에 대한 Bias가 매우 크다.
따라서 해당 논문은 중간 Layer의 Mid-level, intermediate level feature를 추출한다. 그 후 다음과 같은 Process를 수행한다
- Patch Aggregation: 이미지를 작은 패치로 나누고, 각 패치의 특징을 주변 패치와 함께 Aggregation하여 지역적 맥락을 고려한다.
즉, Average pooling 을 사용하여 각각 다른 슬라이딩 윈도우의 평균 풀링 방식으로 locally aware하게 만드는 것이다.
해당 Aggregation을 수식으로 표현하면 다음과 같다.
는 (h,w)근처의 패치들을 의미한다.
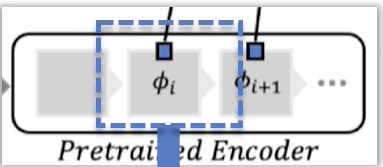
이제 각 단계 에서 추출된 패치들을 GAP를 적용하여 Layer별 local patch feature을 CoreSet으로 구성하고 특정 target 으로 정해놓은 dimension으로 Projection하게 된다.
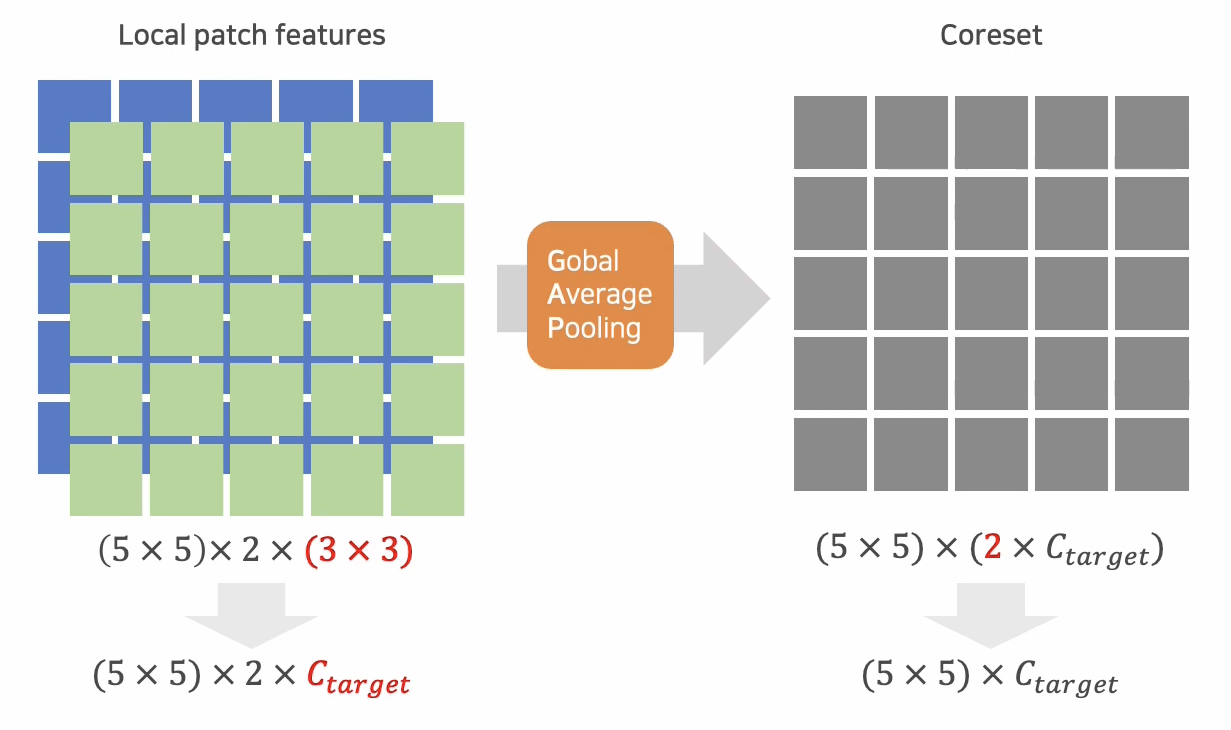
CoreSet SubSampling
정상 데이터가 갖고있는 모든 정보를 갖고있을 필요는 없기 때문에, 중복되거나 유사한 Feature들이 굉장히 많으므로 효율적인 정보량을 가질 수 있도록
Coreset SubSampling을 한다.
그렇다면 왜 굳이 coreset sampling을 해서 memory bank를 만들어야 할까?
본 논문에서는 Greedy SubSampling을 한다.
patchCore의 Sampling -> Memory Bank 알고리즘은 다음과 같다.

해당 알고리즘에서 유심히 봐야할 것은
해당 부분인데, 해당 부분을 해석해보면 Sampling 하기로 선택된 메모리 집단이 인데,새로 추가할 patch feature은 에 있는 어떤 patch feature보다도 가장 멀리 있는 Patch feature을 선택한다는 뜻이다.
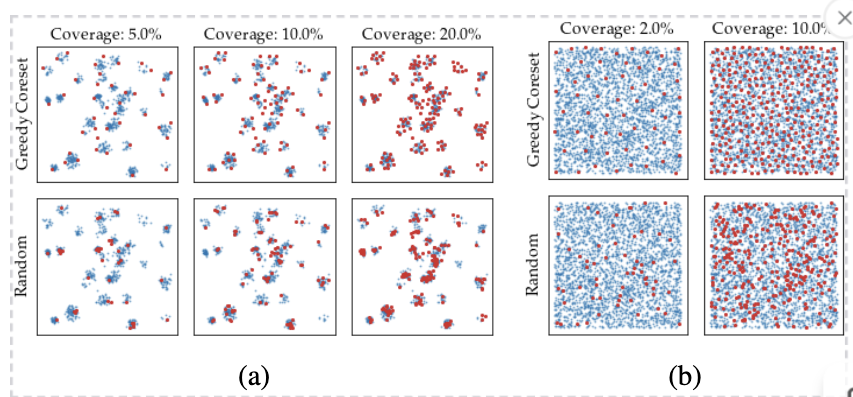
해당 사진을 보면 Random Subsampling 보다 Greedy coreset subsampling이 공간적으로 잘 매핑되는 것을 확인할 수 있다.
AS 측정
Anomaly Score의 측정은 다음과 같은 방법으로 이루어진다.
Test 단계에서 추출된 patch feature은 안의 patch feature들 중 가장 가까운 거리로 해당 patch의 anomaly score을 정해준다.
그러나 해당 AS에서는 feature들 간의 거리 뿐만 아니라, feature들간의 분포도 고려해야한다. 따라서 기본적으로는 해당 AS를 고려하지만 ,
분포를 고려하여 특정 feature가 상의 다른 patch feature들과 멀리 떨어져 있다면, reweighting score을 줘서 더 큰 가중치를 주는 방식이다.
이렇게 측정된 patch별 AS는 pixel level의 ASMap이 되고, 해당 pixel level AS map 중 가장 큰 값이 AS가 된다.
실험
MvTec Data Set
산업용 데이터 셋인 MvTec에 대한 실험결과는 다음과 같다.


해당 table에서 PatchCore가 가장 높은 성능을 내는 것을 볼 수 있다.
low shot AS
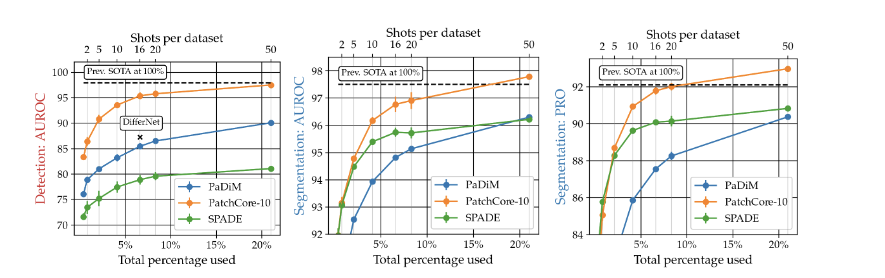
위 그림은 mvTec 학습 데이터의 비율, 개수에 따른 성능을 비교한 표이다.
가장 왼쪽은 PaDiM, PatchCore, SPADE의 detection AUROC 성능에 대한 그래프이다. 가운데는 segmentation AUROC 성능을, 오른쪽은 segmentation PRO 성능을 나타낸 그래프이다.
생각해보면 PatchCore의 coreset sampling은 그 자체가 low shot 세팅이라고 할 수 있다. 학습 데이터 전체 중에서 대표성 있는 일부만 선택해 사용하는 방법이기 때문에...
그 덕분인지 low shot 실험에서도 강한 모습을 보여준다. 거의 모든 항목에서 PaDiM, SPADE보다 좋은 성능을 내는 모습을 볼 수 있다.
