
ALU
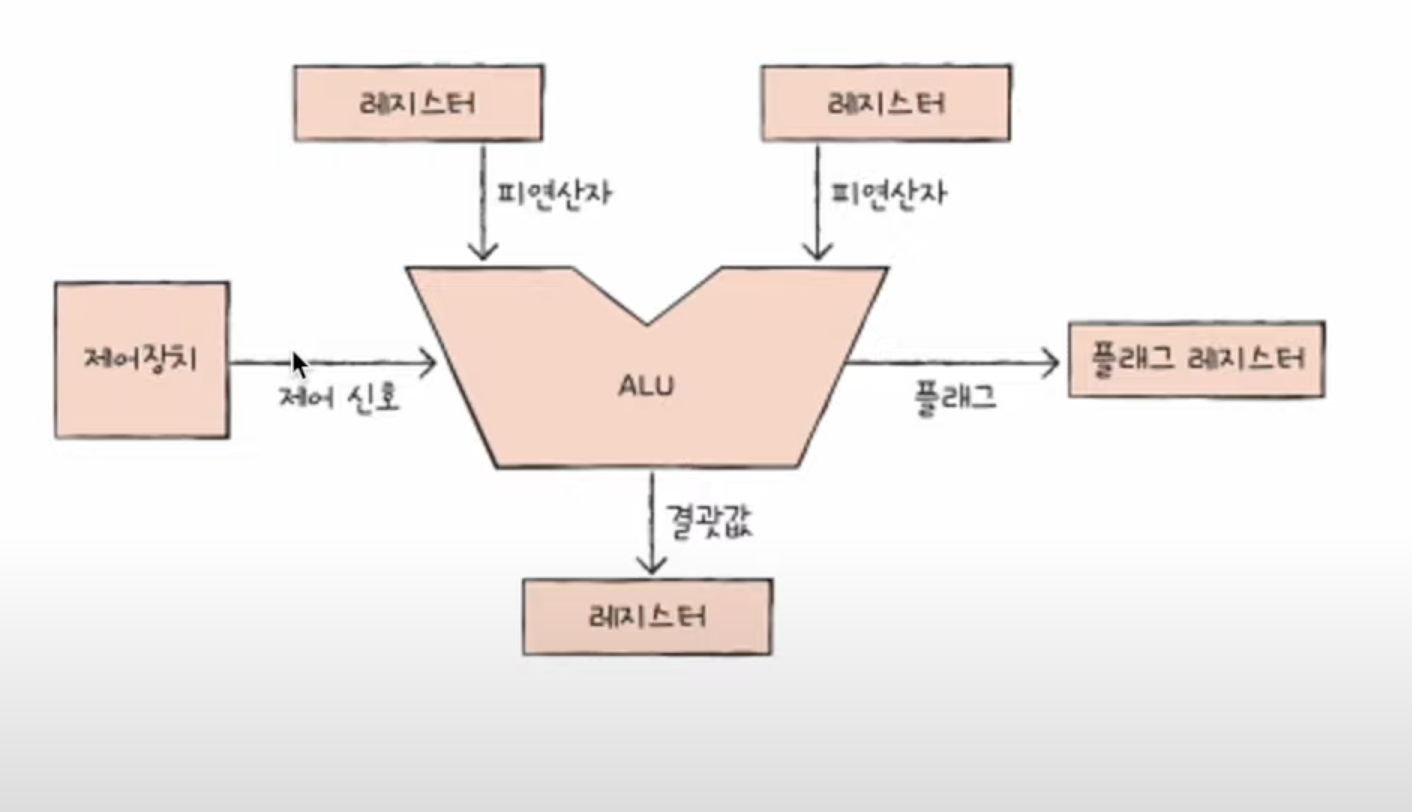
- CPU -> ALU, 레지스터, 제어장치로 구성됨
- ALU는 CPU내부에서 계산을 위한 회로
- ALU는 레지스터로부터 피연산자를 받아들이고, 제어장치로부터 제어 신호를 받아들임
- ALU는 받아들인 정보를 바탕으로 연산을 수행하고, 결과값을 레지스터에 담게 됨
- 레지스터에 저장하는 결과값은 숫자, 문자, 주소 등이 될 수 있음
플래그

- 플래그는 ALU 연산 결과에 대한 부가 정보를 나타냄
- 플래그 값은 플래그 레지스터 내부에 저장되게 되며, 이를 CPU가 해석하게 됨
제어장치
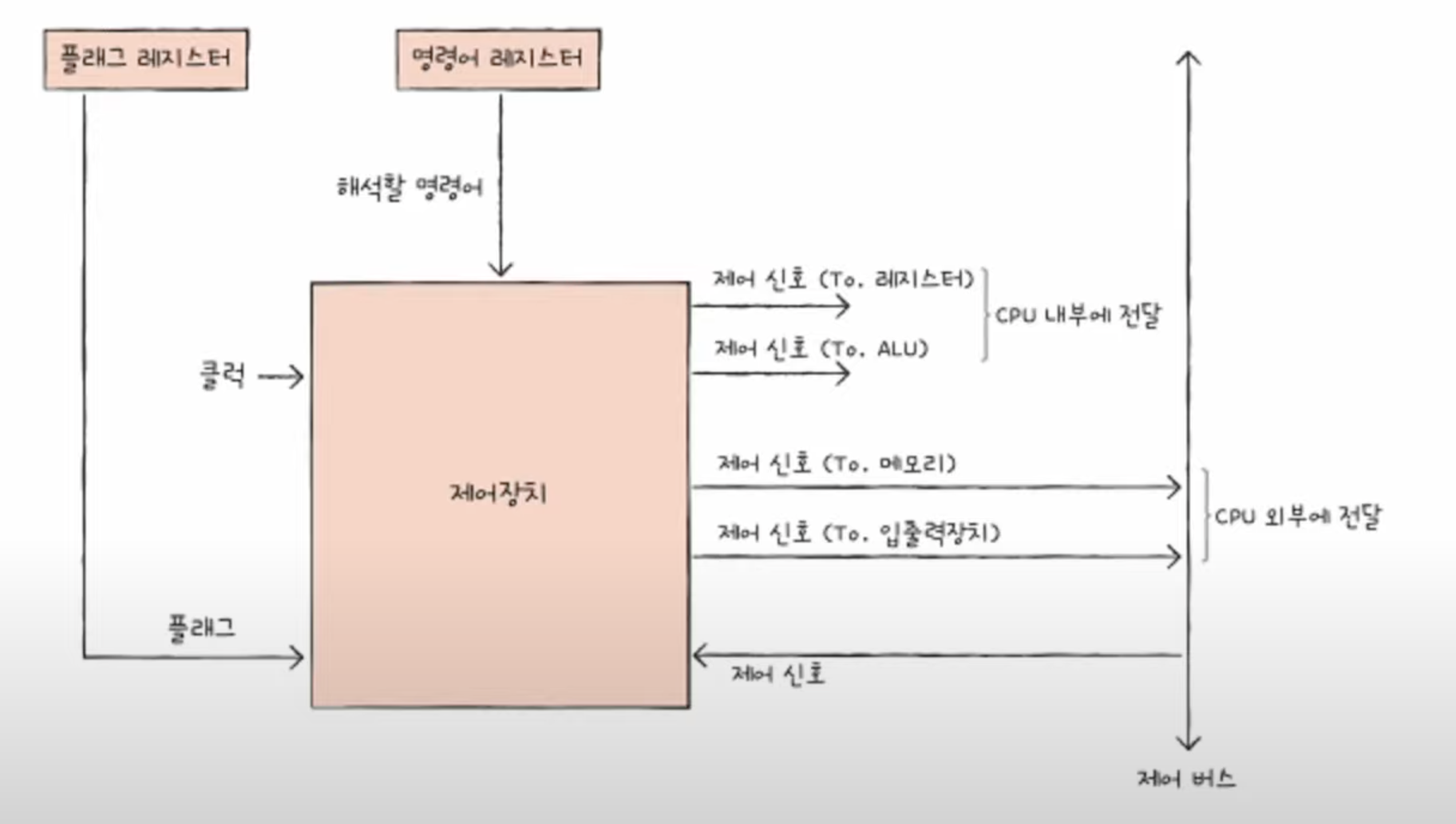
- 클럭을 통해 컴퓨터내의 회로가 동기화 되어 부품들이 일정하게 움직일 수 있게 됨
- 명령어 레지스터에 있는 명령어와 플래그 값을 제어장치가 받아들이고 해석함
- 제어장치가 명령어와 플래그 값을 받아 해석하고 제어 신호를 내보냄
- 레지스터, ALU에 내보내는 제어신호와 메모리, 입출력장치에 내보내는 제어신호로 구분할 수 있음
- 외부 장치들도 제어장치에 제어 신호를 보낼 수 있음
레지스터
- 레지스터는 CPU 내부의 작은 저장장치
- 프로그램 속 명령어나 데이터는 실행 전후로 레지스터에 저장됨
- 레지스터는 CPU 내에 여러가지가 있고, 레지스터마다 각각 역할이 다름
레지스터의 종류
- 프로그램 카운터: 메모리에서 가져올 명령어의 주소, 즉 메모리에서 읽어올 명령어 주소를 저장함
일반적으로 순차적으로 메모리 주소를 읽어오지만, 인터럽트, 메모리 주소 이동 명령어 등에 의해 실행 흐름이 바뀔 수 있음 - 명령어 레지스터: CPU로 읽어들인 명령어를 저장하는 레지스터
- 메모리 주소 레지스터: CPU가 읽고자 하는 주소를 주소 버스로 보낼 때 거치는 레지스터
- 메모리 버퍼 레지스터: CPU가 데이터 버스로 정보를 주고받을 때 거치는 레지스터
- 플래그 레지스터: 플래그 값을 기록한느 레지스터
- 범용 레지스터: 여러개 존재하며, 여러가지 상황에서 사용 가능
- 스택 포인터: 스택 주소 지정 방식에서 스택의 가장 끝부분을 가리키는 레지스터
스택 주소 지정 방식: 스택과 스택 포인터를 사용한 주소 지정 방식
스택이 어디까지 차있는지를 확인 가능 - 베이스 레지스터: 변위 주소 지정 방식에서 사용되는 레지스터
변위 주소 지정 방식: 오퍼랜드 필드의 값과 특정 레지스터의 값을 더해 유효 주소를 얻는 주소 지정 방식
상대 주소 지정 방식: 레지스터 값으로 프로그램 카운터 값을 사용하는 변위 주소 지정 방식
베이스 레지스터 주소 지정 방식: 레지스터 값으로 베이스 레지스터 값을 사용하는 변위 주소 지정 방식
명령어 사이클
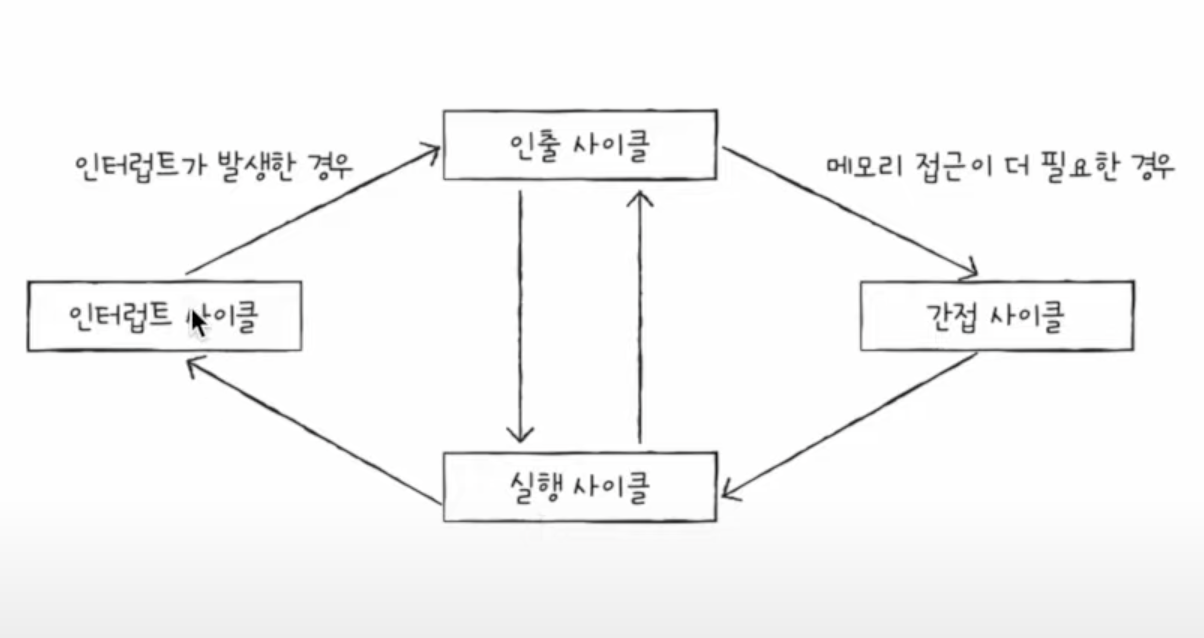
- 프로그램 속 명령어들은 일정한 주기를 가지고 실행되며, 이 과정을 명령어 사이클이라고 함
- 인출 사이클은 메모리에 데이터를 우선 CPU로 가져오는 과정을 의미함
- 실행 사이클은 메모리에서 가져온 데이터를 실행하는 과정을 의미함
- 보통 인출 사이클과 실행 사이클이 반복되며 명령어 사이클을 이루는데, CPU로 명령어를 가지고 와도 실행이 바로 불가능한 경우가 생길 수 있음. 이런 경우 추가적인 메모리 접근을 위한 간접 사이클이 실행됨
- 인터럽트가 발생
할 경우 실행사이클 이후 인터럽트 사이클이 실행됨
인터럽트
- CPU의 명령어 사이클을 끊는 신호
- 중요한 작업을 실행할 때 인터럽트가 발생하게 됨
동기 인터럽트
- CPU가 예상치 못한 상황을 접할 때 발생하는 인터럽트
- 동기 인터럽트에 종류로는 폴트, 트랩, 중단, 소프트웨어 인터럽트가 있음
비동기 인터럽트(하드웨어 인터럽트)
- CPU에 비동기적 작업의 발생을 알리는 인터럽트
- 주로 입출력 장치에 의해 발생하는 인터럽트로 하드웨어 인터럽트라고도 부름
- CPU의 효율적인 명령어 처리를 위해 하드웨어 인터럽트 사용 (입출력장치가 CPU에 비해 느림)
하드웨어 인터럽트의 처리 순서
※ 인터럽트 종류를 막론하고 인터럽트 처리 순서는 비슷함
- 입출력장치가 CPU에 인터럽트 요청 신호를 보냄
인터럽트 요청 신호: 하드웨어 장치 등에서 CPU에 인터럽트를 요청하는 신호
- 입출력장치가 CPU에 인터럽트 요청 신호를 보냄
- CPU가 실행 사이클이 끝나고 명령어를 인출하기 전 항상 인터럽트 여부를 확인함
- 이 때 인터럽트 요청이 확인되면 인터럽트 플래그를 통해 현재 인터럽트를 받아들일 수 있는지 확인
인터럽트 플래그로도 막을 수 없는 인터럽트가 있으며, 이러한 인터럽트는 non maskable interrupt, 플래그로 막을 수 있는 인터럽트는 maskable interrupt로 부름
- 이 때 인터럽트 요청이 확인되면 인터럽트 플래그를 통해 현재 인터럽트를 받아들일 수 있는지 확인
- 인터럽트를 받아들일 수 있으면 CPU는 지금까지의 작업을 스택 영역에 백업
- CPU는 인터럽트 백터를 참조해 인터럽트 서비스 루틴을 실행
인터럽트 서비스 루틴은 인터럽트가 발생했을 시 인터럽트를 처리하기 위한 프로그램이며, 메모리에 저장됨
인터럽트마다 고유한 인터럽트 서비스 루틴을 가지며, 각각의 인터럽트를 구분하기 위한 정보로 인터럽트 백터가 필요함
- CPU는 인터럽트 백터를 참조해 인터럽트 서비스 루틴을 실행
- 인터럽트 서비스 루틴 실행이 끝나면 백업한 작업을 복구해 실행 재개
CPU와 속도
- 클럭이 빠를수록 일반적으로 컴퓨터의 작동 속도가 증가하지만, 발열이 증가하게 됨
- 발열을 줄이면서 컴퓨터의 작동속도를 증가시키기 위해 코어, 스레드 수를 증가시키게 됨
코어
- 전통적으로 CPU에서 명령어를 실행하는 부분은 하나만 존재했지만, 오늘날에는 여러개 존재하게 됨
- 명령어를 실행하는 부품들의 집합을 코어로 부름
- 여러개의 코어를 가진 CPU를 멀티 코어 CPU로 부름
- 코어수가 많아진다고 해도 반드시 속도가 코어 수에 비례하여 증가하지는 않음
스레드
- 스레드는 실행 흐름의 단위이며, 하드웨어적 스레드와 소프트웨어적 스레드로 나뉘어짐
- 하드웨어 스레드는 하나의 코어가 동시에 처리하는 명령어 단위를 의미함
하나의 코어가 여러개의 스레드를 처리 가능한 CPU를 멀티스레드 CPU라고 함 - 소프트웨어적 스레드는 하나의 프로그램에서 독립적으로 실행되는 단위를 의미함
하나의 스레드만을 가지고 실행되면 하나의 흐름만을 가지고 실행되고, 멀티스레드로 실행하면 여러개의 흐름을 가진 프로그램이 됨 - 멀티스레드 프로세서에서 가장 큰 핵심은 레지스터로, 하나의 명령어를 실행하기 위해 필요한 레지스터 세트가 여러개 있으면 한번에 여러 작업을 실행 가능함
- 하드웨어 스레드는 논리 프로세서라고도 부름
명령어 파이프라인
- 명령어 처리는 명령어 인출 -> 명령어 해석 -> 명령어 실행 -> 결과 저장 순으로 진행되며, 각 과정의 처리 시간은 비슷함
- 같은 단계가 겹치지 않는 이상 CPU는 각 단계를 동시에 실행할 수 있음
- 명령어 파이프라이닝은 동시에 여러개의 명령어를 겹쳐 실행하는 기법
- 이상적인 경우 성능 향상에 도움이 되지만, 성능 향상에 실패하는 파이프라인 위험이 존재함
- 파이프라인 위험은 데이터 위험, 제어 위험, 구조적 위험으로 나뉨
데이터 위험
- 명령어 간의 의존성에 의해 발생하는 파이프라인 위험
다음과 같은 의사코드가 있다 가정해보면, 다음 코드는 첫줄의 결과가 저장전에 두번째 줄의 코드를 실행해서는 안된다.
R1 <- R2 + R3
R4 <- R1 + R5제어 위험
- 프로그램 카운터가 갑작스럽게 변화될 때 발생되는 파이프라인 위험
- 도중에 프로그램 카운터가 변경되면 파이프라인에서 실행하던 명령어는 무효가 되버림
- 이를 방지하기 위해 프로그램 카운터의 변경 주소를 예측하는 분기 예측이라는 기술을 사용함
구조 위험
- 서로 다른 명령어가 같은 CPU부품(ALU, 레지스터)를 사용하려 할 때 발생하는 파이프라인 위험
슈퍼스칼라
- CPU 내부에 여러개의 명령어 파이프라인을 포함한 구조
- 이론적으로는 파이프라인 개수에 비례해 처리속도가 증가해야 하지만, 파이프라인 위험의 증가로 인해 파이프라인 개수에 비례해 처리 속도가 증가하지는 않음
- 오늘날의 멀티스레드 프로세스에서 사용되는 기술임
비순차적 명령어 처리
- 비순차적 명령어 처리 기법은 파이프라인의 중단을 방지하기 위해 명령어를 순차적으로 처리하지 않는 명령어 처리 기법을 의미함
- 프로그램 실행 흐름에 지장이 없는 의존성이 없는 명령어의 순서를 변경하여 성능 향상을 도모할 수 있음
명령어 집합
- 명령어 집합(Instruction Set Architecture)은 CPU가 이해할 수 있는 명령어들의 모음을 의미함
CPU의 언어이자 하드웨어가 소프트웨어를 어떻게 이해할지에 대한 약속이기도 함 - 명령어가 달라지면 명령어 해석 방식, 레지스터의 종류나 개수, 파이프라이닝의 용이성 등의 많은 것들이 달라지게 됨
CISC(Complex Instruction Set Computer)
- 복잡한 명령어 집합을 활용하는 CPU를 의미함
- 명령어의 형태와 크기가 다양한 가변 길이 명령어를 활용하며 상대적으로 적은 수의 명령어로도 프로그램을 실행할 수 있음
- 명령어의 크기와 실행시간이 일정하지 않고, 명령어가 복잡해 명령어 하나를 실행하는데 여러 클럭 주기가 필요함 -> 명령어 파이프라이닝이 불리하다는 치명적 단점을 가짐
- 대다수의 복잡한 명령어는 사용 빈도가 낮음
- x86, x86-64가 CISC기반의 ISA를 사용
RISC(Reduced Instruction Set Computer)
- RISC는 단순하고 적은 수의 고정길이 명령어 집합을 사용하는 CPU를 의미함
- 메모리 접근을 최소화하고, 레지스터를 적극적으로 활용함
- 명령어 규격을 일정하게 하고, 1클럭 내외로 명령어를 수행하기 때문에 명령어 파이프라인에 유리함
- CISC에 비해 같은 명령을 실행하는데 더 많은 명령어가 필요함
출처:
https://www.youtube.com/watch?v=lehWiAsIDrQ&list=PLVsNizTWUw7FCS83JhC1vflK8OcLRG0Hl&index=11&t=5s
혼자 공부하는 컴퓨터 구조+운영체제, 강민철, 한빛미디어

냐아아아아아아아아앙