
Nested Loop Join
What is Nest Loop Join
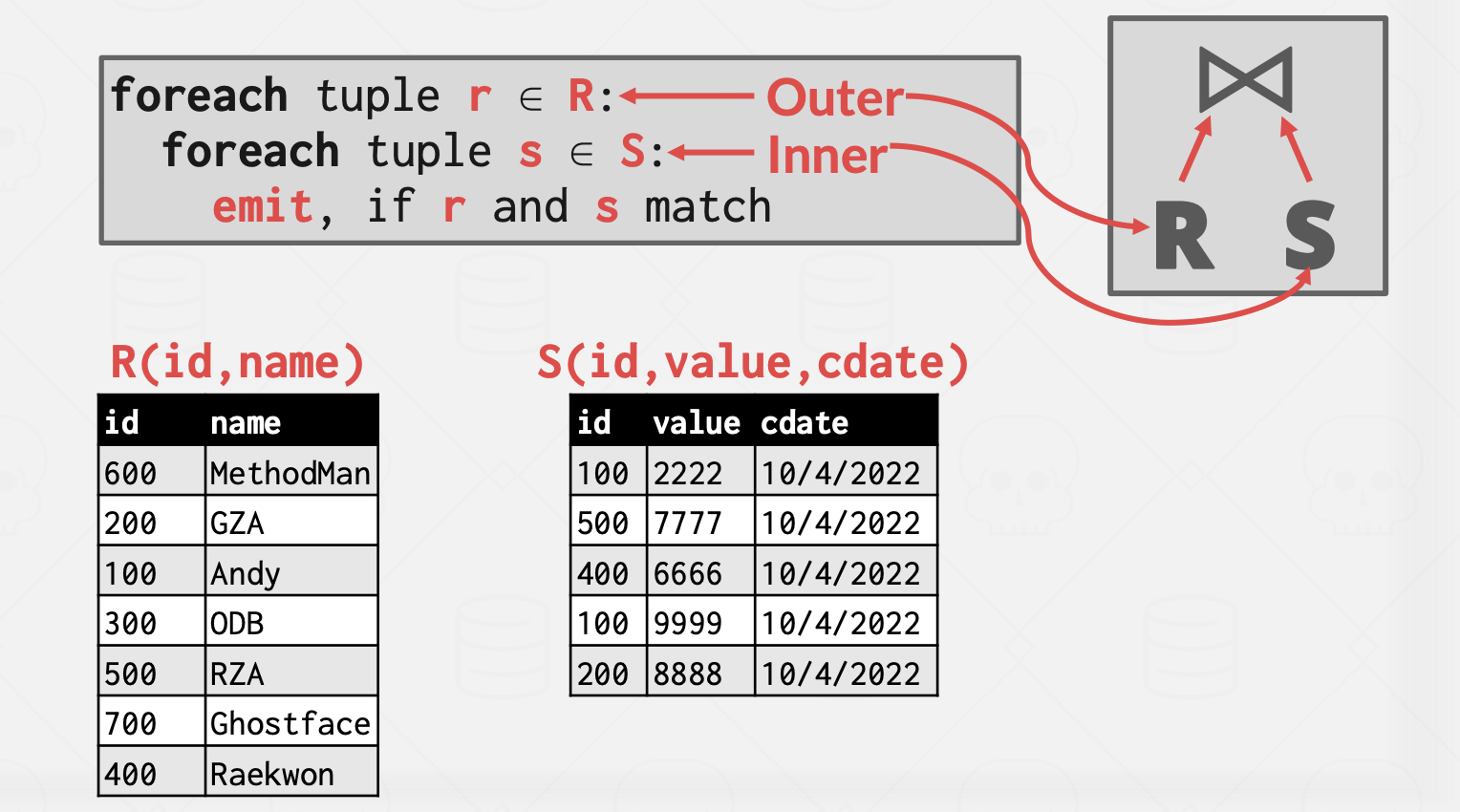
줄여서 NL JOIN이라고도 불리는 NESTED LOOP JOIN은 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결합하여 원하는 결과를 조합하는 조인 방식입니다. 조인해야 할 데이터가 많지 않은 경우에 유용하게 사용됩니다. NESTED LOOP JOIN은 드라이빙 테이블로 한 테이블을 선정하고 이 테이블로부터 where절에 정의된 검색 조건을 만족하는 데이터들을 걸러낸 후, 이 값을 가지고 조인 대상 테이블을 반복적으로 검색하면서 조인 조건을 만족하는 최종 결과값을 얻어냅니다.
Cost Analysis
이 Nested Loop Join은 멍청하다. 아래 그림에서 볼 수 있듯이 drving table의 튜플마다 Driven table을 full scan하기 때문이다. 참고로 Cost: M + (m*N)에서 M은 table R을 page 단위로 가져오기 때문에 그 비용이다. 뭔가 더 최적화할 수 있을 것이라 생각한다면 당신은 짱! 하지만 일단 차근차근 보자.

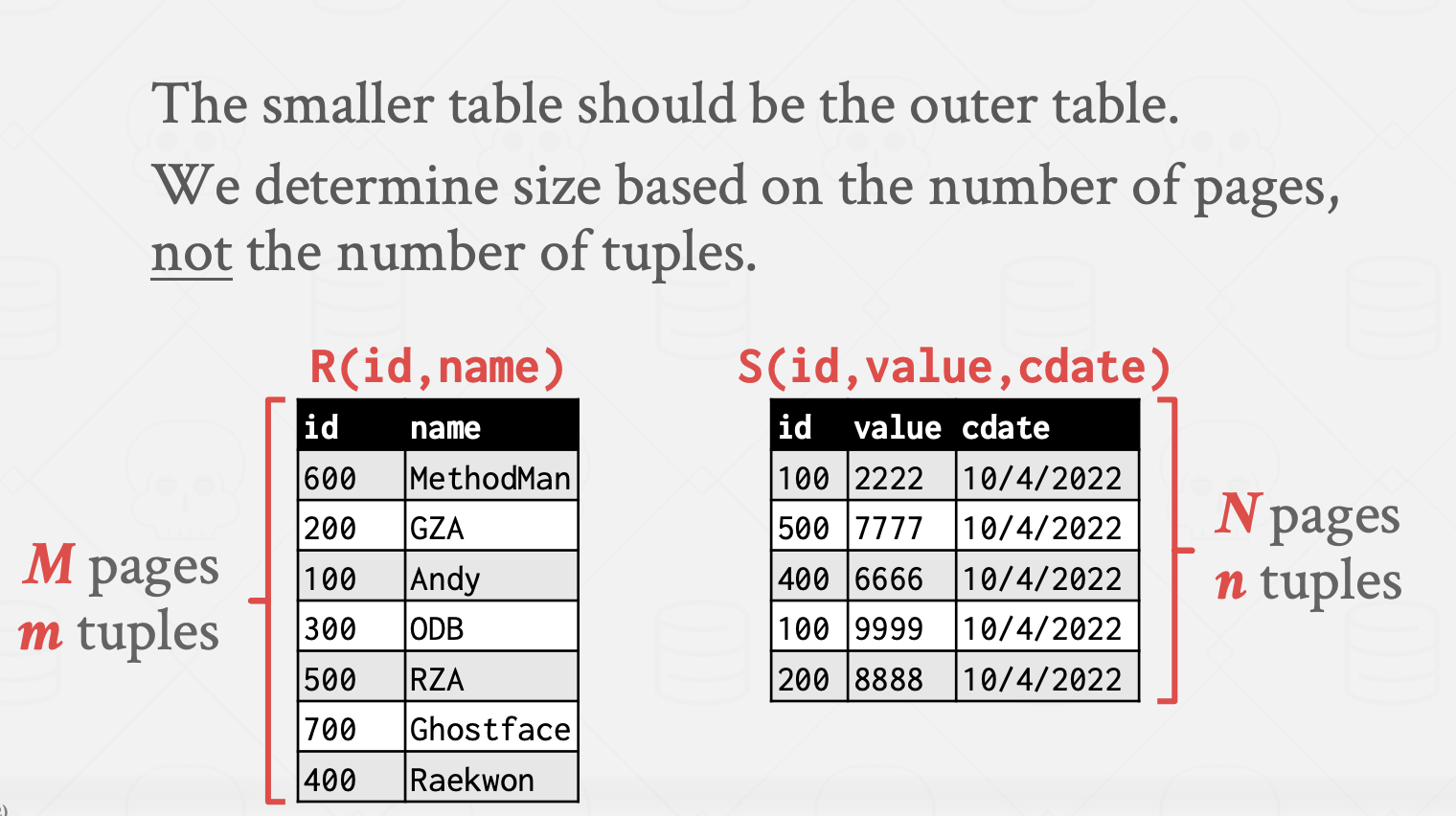
수식을 보면 알아차릴 수 있듯이 어떤 테이블이 Driving, Driven table인지에 따라서 Cost가 달라진다. 작은 테이블이 Driving하면 이득.

Block Nested Loop Join
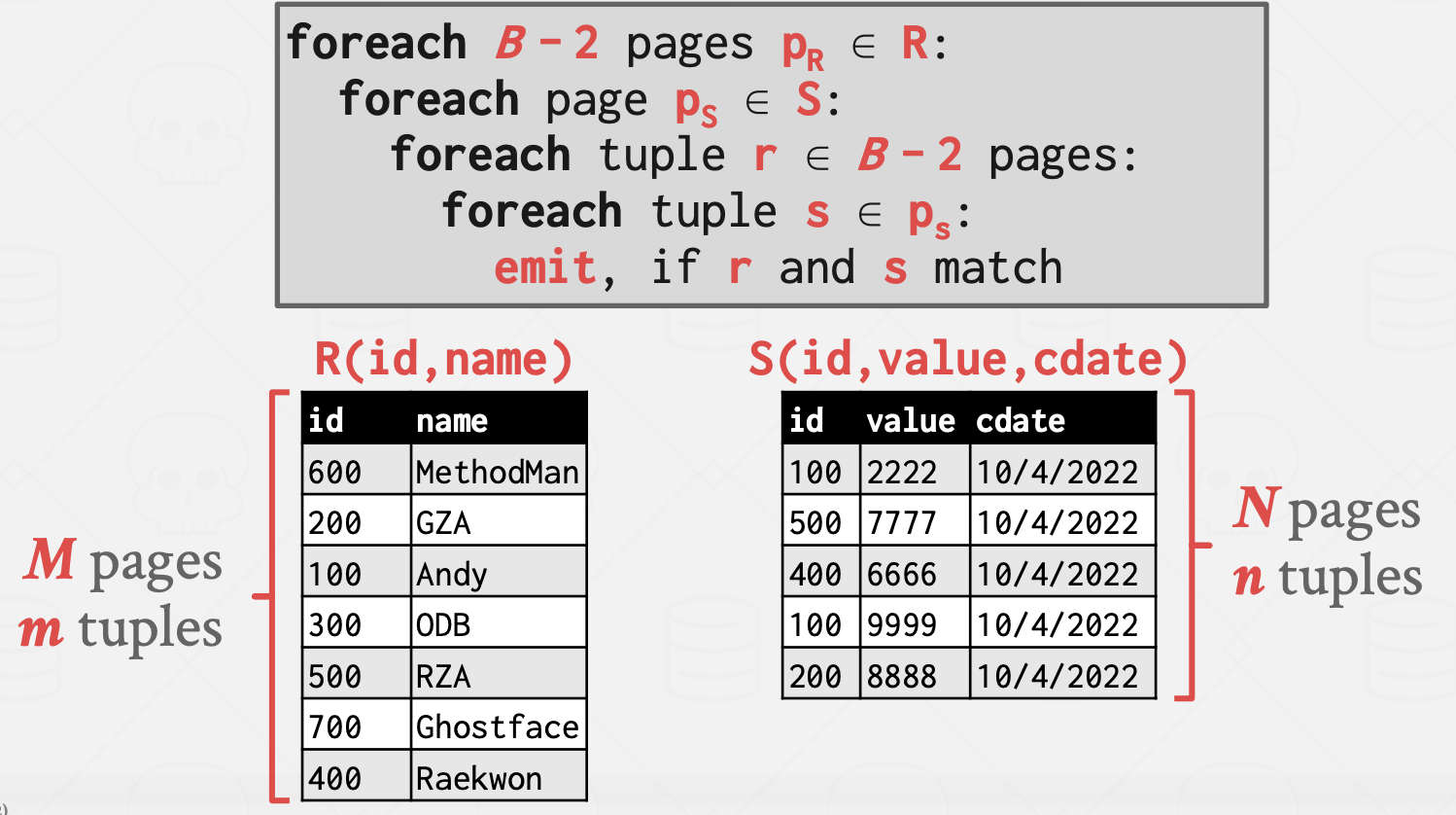
Disk Access에 관해 조금 더 최적화된 버전의 Nested Loop Join이 있다. 그게 바로 Block Nested Loop Join이다. 아래 Pseudo 코드를 보자.

Cost Analysis

마찬가지로 작은 테이블이 Driving table일 때 더 이득이다.

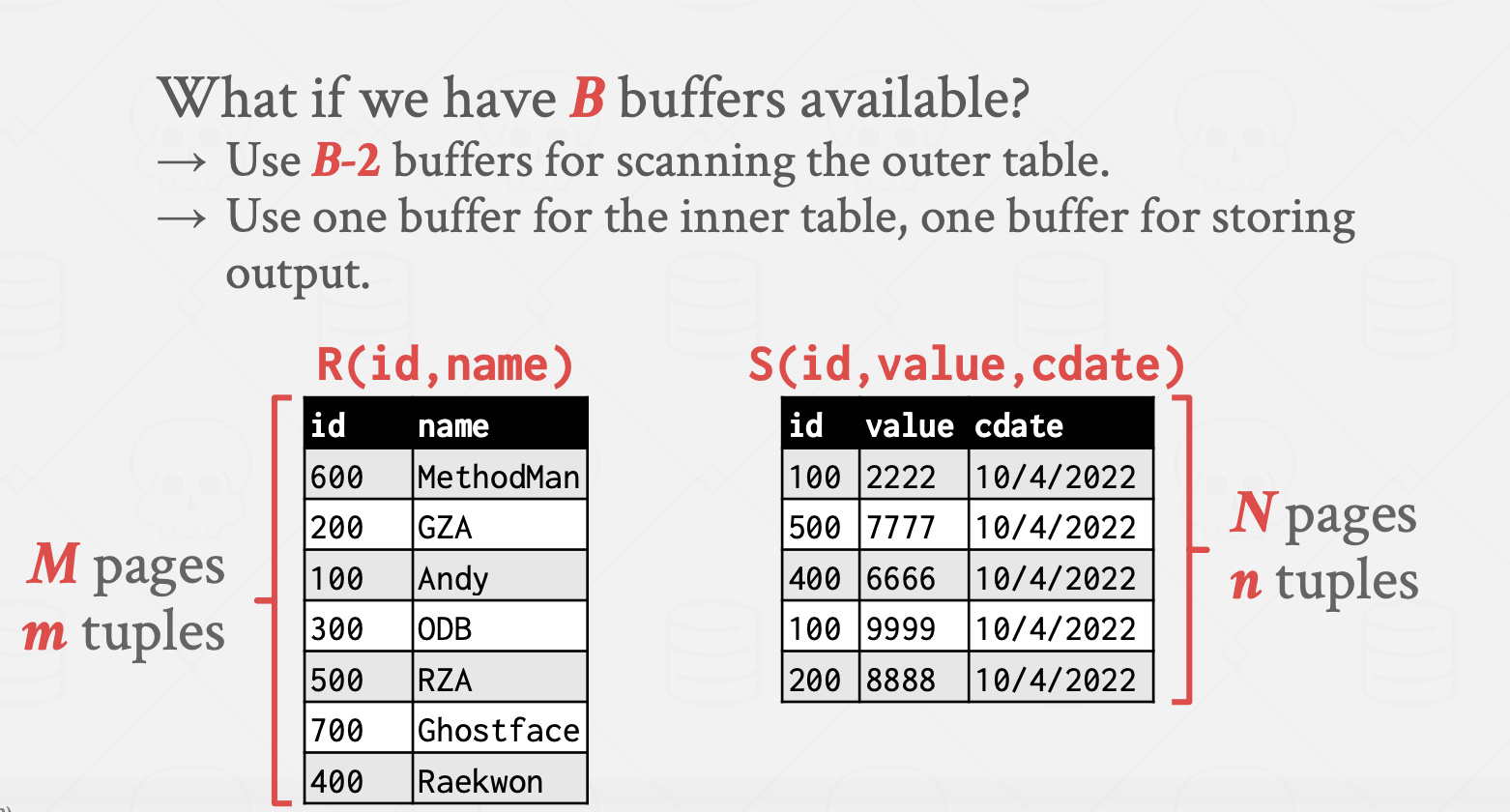
근데 위에서 본 Block Nested Loop Join은 2개 block 크기의 메모리를 사용한다. 근데 만약 B개의 block을 사용한다면?

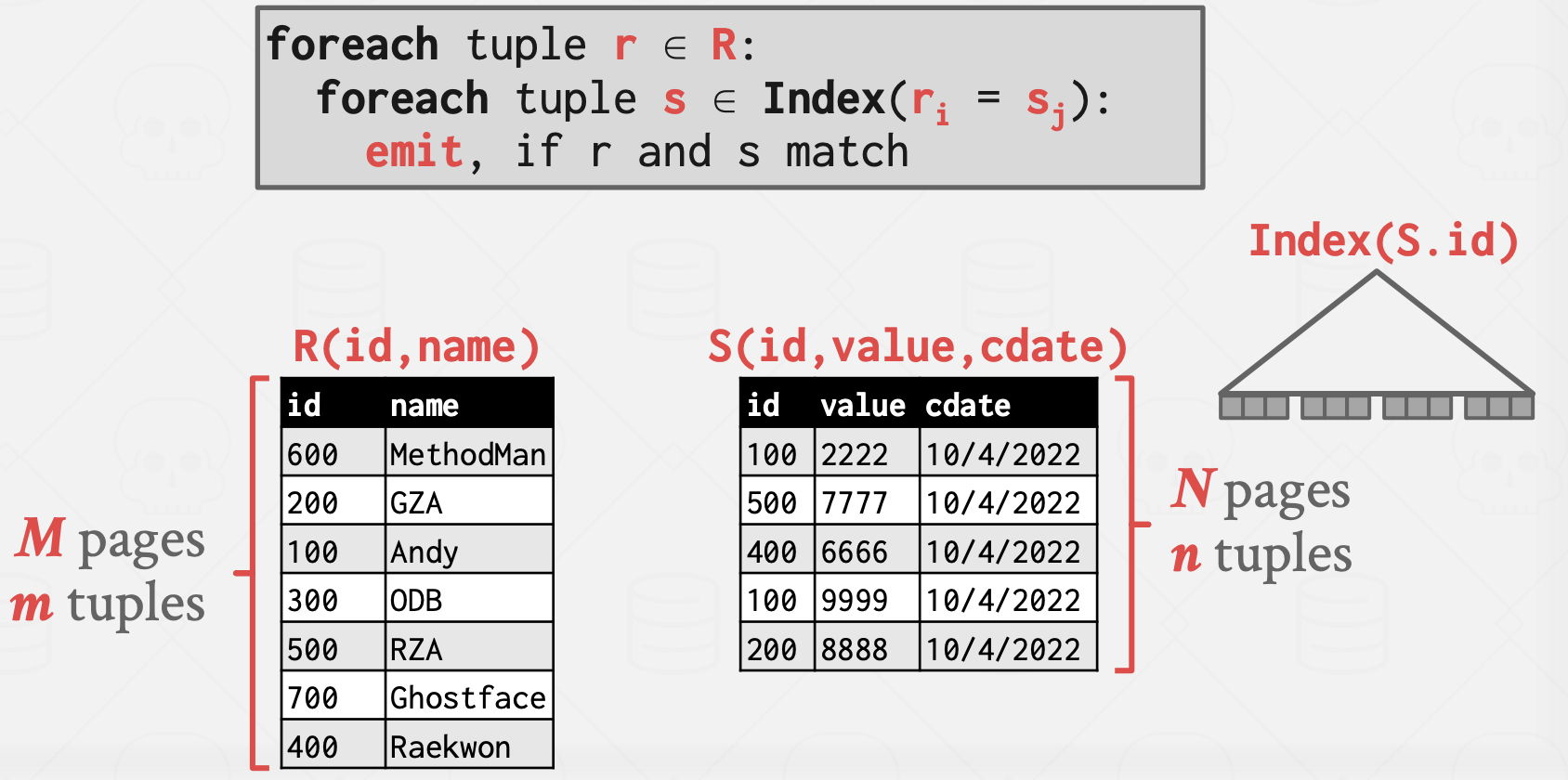
지금까지는 index가 설정되어 있지 않다는 가정이 있었다. 이번엔 Index와 연관지어 생각해보자.
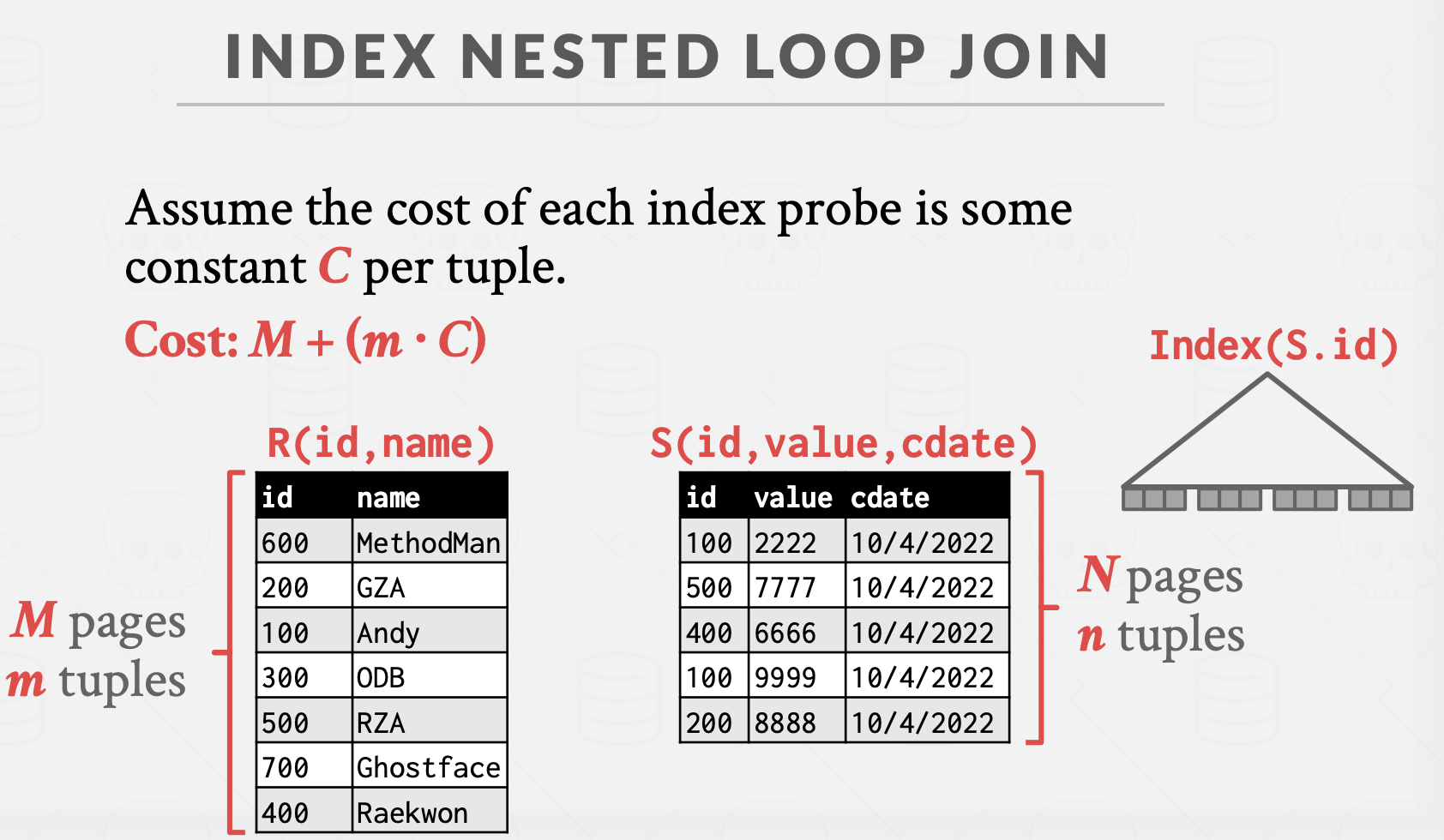
Index Nested Loop Join
먼저 Index에 대해 복습 !
https://velog.io/@nice-one-roy/Database-Index
- Key Takeaways
→ Pick the smaller table as the outer table.
→ Buffer as much of the outer table in memory as possible.
→ Loop over the inner table (or use an index).- Algorithms
→ Simple / Stupid
→ Block
→ Index
참고자료 CMU database lecture note
https://15445.courses.cs.cmu.edu/fall2022/slides/11-joins.pdf
