RAG
RAG(Retrieval Augmented Generation)는 미리 학습된 LLM(대규모 언어 모델) 및 자체 데이터를 사용하여 응답을 생성하는 패턴이다.
왜 필요한가
현재 널리 쓰이고 있는 Chatgpt와 같은 LLM은 수많은 범용적인 데이터로 그리고 특정 시점 데이터로(과거 어떤 시점) 학습되었습니다. 그러나 때로는 범용적이지 않고 자신만이 갖고 있는 데이터나 최신 데이터로 작업해야 하는 경우도 있습니다.
해당 경우에 LLM을 활용할 수 있는 두 가지 방식이 있다.
- 새로운 데이터로 모델을 Fine tuning한다.
- RAG를 활용한다.
Fine tuning은 좋은 해결책이 될 수 있지만 값이 비싸다는 단점이 있어서 RAG가 효율적인 방법이 될 수 있다.
추가적으로 RAG를 잘 사용하면 LLM의 고질적인 문제인 Hallucination도 어느 정도 줄일 수 있다는 장점도 있다.
그래서 어떻게 동작하는건데
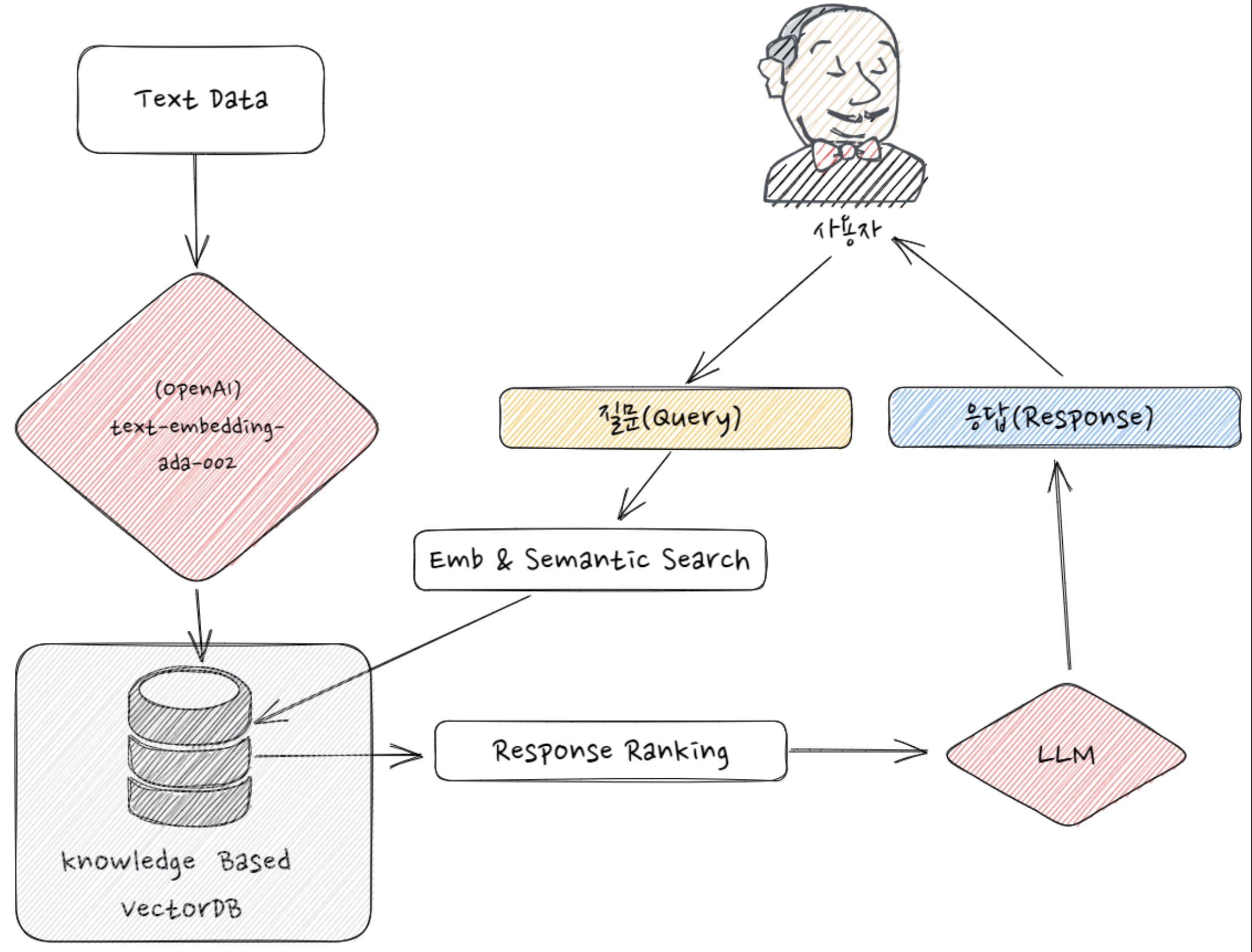
Flow는 다음과 같다.
- Data를 chunk로 쪼갠다.
- 쪼갠 chunk를 embedding model로 vector화한다.
- Vector들을 Vector DB에 저장한다. 다음 글에서 Vector DB에 대해 다룰거라서 간단하게만 이야기하자면, 아래 그림의 파란색 부분처럼 Vector Space에 벡터들을 두고 벡터들간의 유사도를 계산할 수 있는 상태.
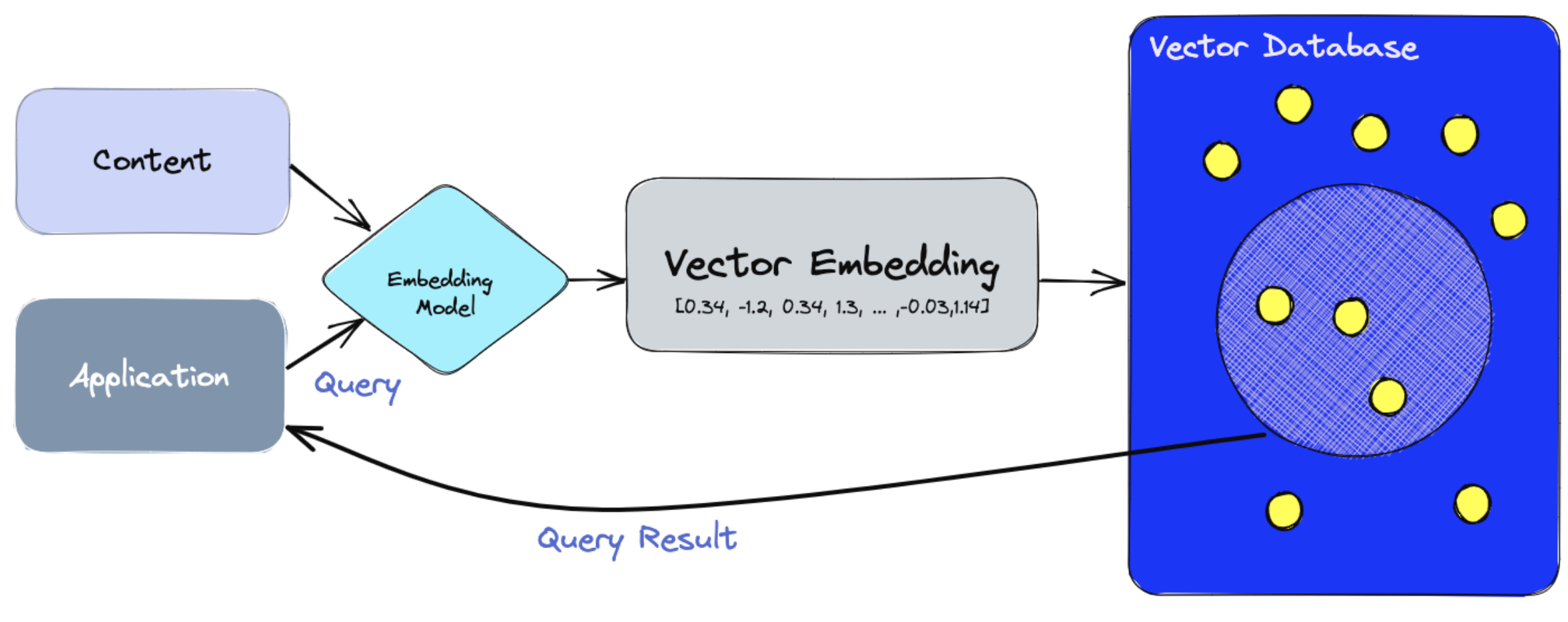
- 유저가 질문한다.(Query)
- 유저의 query도 embedding model로 vector화한다.
- 유저의 query와 가장 유사도가 높은 N개의 vector를 retrieval한다.
- 벡터들에 해당하는 원본 데이터들을 가져온다.
- 그 데이터들(A)을 Prompt(B)와 조합해 LLM에게 "A라는 정보에서 B라는 질문 대답해줘"라는 식의 명령을 내리고 결과를 유저에게 전달한다.
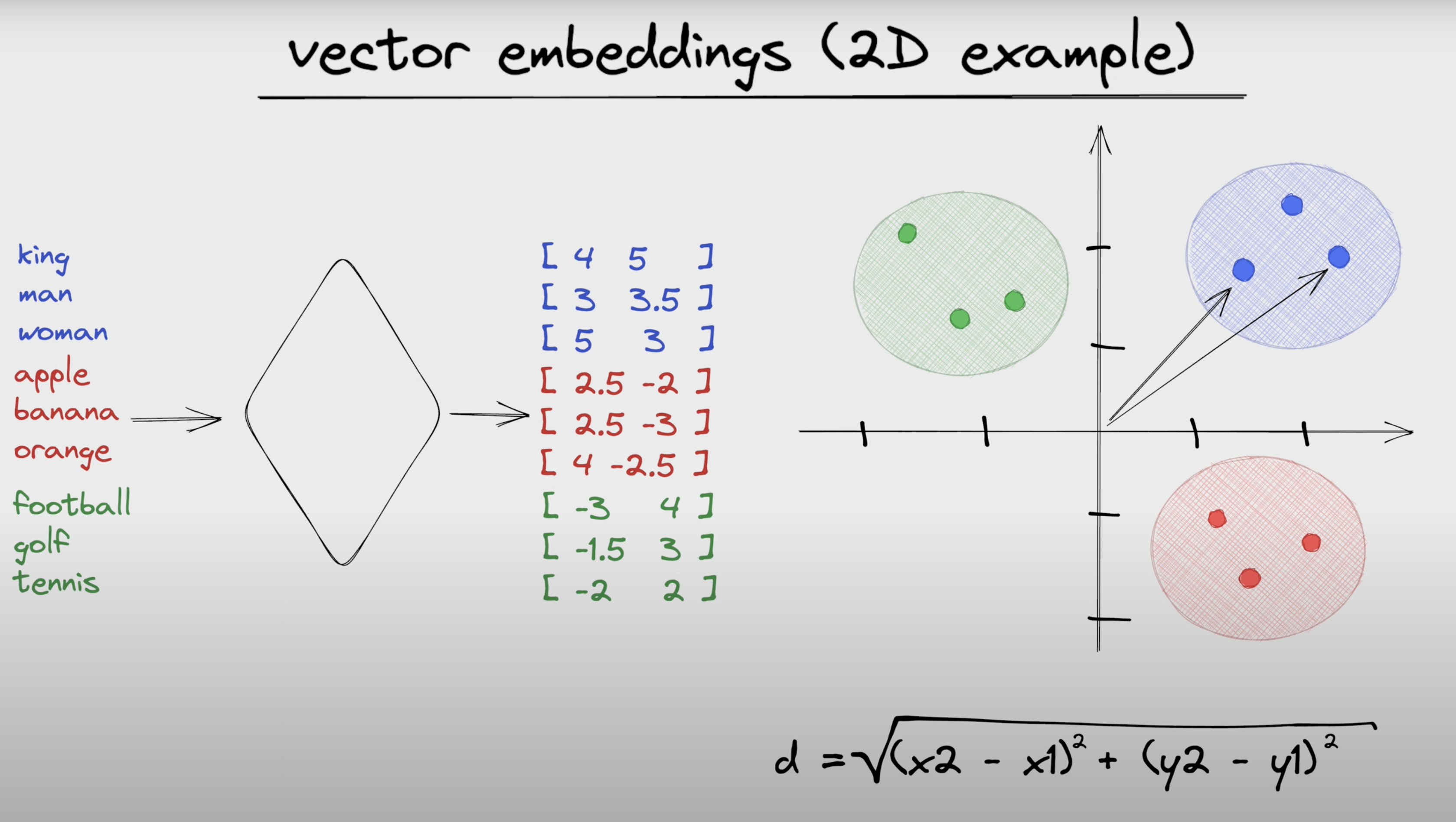
Vector Embedding(참고)
Memo
최근 엄청난 성능을 보이는 LLM들을 보면서 신기함을 느꼈지만 활용에 있어서, 특히 비지니스적으로 애매한 부분이 있었다고 생각하는데 RAG가 좋은 Use case? Framework?이 될 수 있을 것 같당.

내가 보려고 쓰는 글