[논문리뷰] Are Language Models Actually Useful for Time Series Forecasting?
arxiv link
https://arxiv.org/pdf/2406.16964
Github page
https://github.com/BennyTMT/LLMsForTimeSeries?utm_source=catalyzex.com
Introduction
Time series의 분석은 disease propagation forecasting, retail sales analysis, healthcare, finance등 여러 분야에서 사용되고 있다. 최근 time series analysis의 연구는 Pretrained LLM을 적용하여 classify, forecast, anomaly detection 등의 과제에 적용하려는 시도에 집중하고 있다. 이러한 연구들은 LM이 text에서의 순차적인 의존관계를 학습하기 때문에, 이 능력을 일반화하여 time series data에서의 순차적 의존관계의 학습에 사용할 수 있다는 가설을 전제로 한다. 그러나, Language modeling과 time series forecasting간의 연결은 아직 미지의 영역이다. 기존의 time series task와 비교했을 때 Language modeling은 어떤 이점을 지니고 있는가?
이 연구에서는 다음과 같이 답한다 : popular LLM based time series forecaster은 basic LLM (free-abilation)의 이용과 비교했을 때 같거나 더 좋지 않은 성능을 보이고 더 많은 컴퓨팅 자원을 요구한다. 즉 현재의 방법들이 pre-trained된 LM의 추론 능력을 time series task에 효과적으로 활용하지 못하고 있음을 강조한다.
이를 입증하기 위해 저자들은 3개의 LLM과 8개의 benchmark dataset과 MONASH에서 제공한 5개의 dataset에 대해 실험을 진행한다. 우선 기존의 연구들의 결과를 재현한다. 이후 LM을 간단한 Attention layer, basic transformer block, randomly-initialized LM, 심지어는 LM을 제거하는 등의 ablation method들만으로도 좋은 성능을 얻을 수 있다는 것을 확인한다.
다음으로는 ablation method들과 기존 방법의 training, inference time 측면에서 비교한다. 그 결과 간단한 abilation method들이 training, inference time을 줄이면서도 비슷한 성능을 달성한다는 것을 확인한다. 이후 LLM forecaseter의 성능을 조사하기 위해 Time series encoder을 추가로 연구한다. 여기서 simple linear model with encoder (patching, attention으로 이루어짐)이 LLM과 비슷한 정도의 forcasting performance를 달성할 수 있음을 발견하였다. 이어서 LLM의 순차적인 정보를 modeling할 수 있는 능력이 time series로 전이될 수 있는지 연구하기 위해 input time series를 shuffling해 보았지만, 성능의 변화는 거의 없었다. 마지막으로 LLM이 training data의 10%만 사용하는 few shot setting에서는 별 효과가 없었다는 것을 확인하였다.
이 논문의 주요 기여는 다음과 같다.
- Time series data를 LLM에 입력하는 방법 3가지를 제안한다. 13개의 데이터셋에서 3가지 주요 방법을 분석하여 LLM이 abilation method들에 비해 개선된 성능을 재공하지 않으며, training / inference 시간에서 연산 비용이 늘어난다는 것을 밝힌다.
- Pretraining of LLM의 효과를 연구하기 위해 weight를 초기화 한 뒤 forecasting을 진행한다. 그 결과 model weight initialize는 forecasting에는 영향을 끼치지 않는 다는 것을 발견했다. 또한 input time series shuffling의 결과 LLM에서 transfer sequence modeling ability from text to time series 가 일어났다는 증거를 찾을 수 없었다고 하며, few shot setting에도 영향을 주지 못했다.
- Patching과 attention을 encoder로 하는 간단한 모델이 LLM과 유사한 성능을 달성할 수 있음을 시사한다.
Experimental Setup
이 연구에서는 Time series forecasting을 위해 3가지의 SOTA method를 사용하고, LLM에 대해 3가지의 ablation methods를 제안한다 : without LLM, LLM2Attn, LLM2Trsf이 그것이다. 이 방법들을 8개의 dataset에 대해 평가한다.
Reference Methods for Language Models and Time Series
3개의 LLM 기반 Time series forecasting 방법을 실험한다. 이 모델들은 GPT-2나 LLaMA를 base model로 사용하며 서로 다른 alignment와 fine tuning 전략을 사용한다.
-
OneFitsAll : GPT4TS라고도 불린다. 이 연구에서는 input time series에 대해 instance norm과 patching을 적용하고, 이를 LM의 linear layer에 전달하여 LM의 input representation을 얻는다. multi head attention과 feed forward layer은 학습되지 않고 (frozen), layer norm과 positional embedding이 optimized된다. final linear layer은 model’s final hidden state를 prediction으로 변환한다.
-
Time-LLM : input time series는 patching을 통해 tokenize되며 multi head attention을 통해 low dimension representation으로 align된다. 이는 statistical feature disctiption의 임베딩과 결합되어 frozen pre-trained language model로 전달된다. 이후 output은 flatten되고 linear layer을 거쳐 forecasting을 얻는다.
-
CALF : CALF는 input time series의 각 채널을 token으로 취급하여 임베딩한다. 모델의 절반은 ‘textual branch’로, cross attention을 사용하여 time series erepresentation을 LM에 통과시켜 “textual prediction”을 얻는다. 동시에 “temporal branch”는 input time series를 기반으로 하여 low-rank adapter를 학습시켜 “temporal prediction”을 얻으며, 이는 inference에 사용된다. 이 표현 2개간의 유사성을 높일 수 있는 loss term이 포함된다.
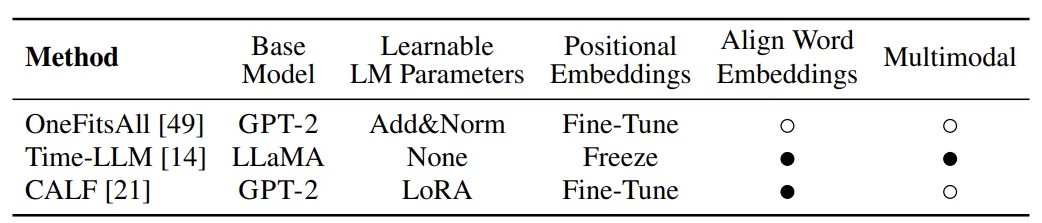
Proposed Ablations
LLM을 이용하여 forecasting하는 모델들은 공통적으로 다음과 같은 구조를 가진다.
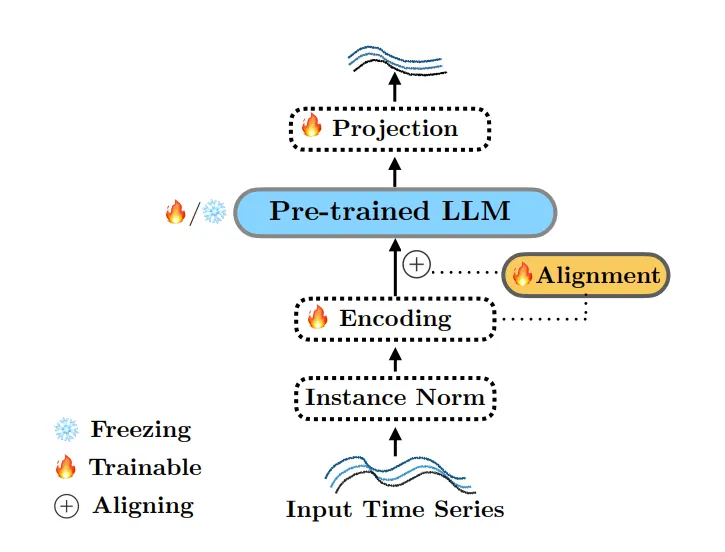
LLM based forecaster에서 LLM의 기여를 제거하기 위해 다음과 같은 3가지의 ablations를 제안한다.
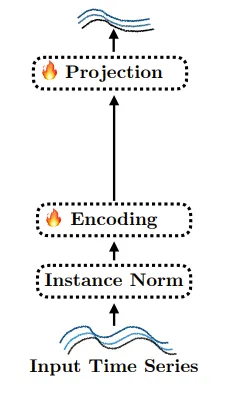
- w/o LLM : LM을 완전히 제거하고, input token을 referece method의 final layer로 바로 전달한다.
- LLM2Attn : Language model을 single randomly-initialized multi-head attention layer로 교체한다.
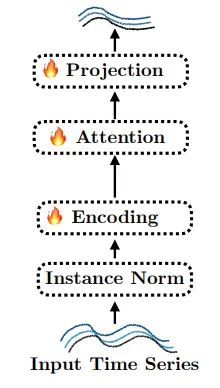
- LLM2Trsf : Language model을 single randonly-initialized transformer block으로 교체한다.
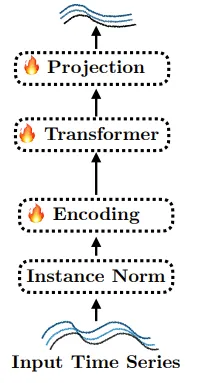
위의 ablation method들에서 forecaster의 LM을 제외한 나머지 부분들은 변경하지 않는다.
Dataset and Evalutation Metrics
Benchmark datasets
- ETT : electricity transformers에 관한 7가지 factors들을 포함하며, ETTh1, ETTh2 (시간단위 기록), ETTm1, ETTm2 (15분 단위 기록)으로 구성된다.
- Illness : Venters for Disease Control에서 influenza-like illness의 비율을 주별로 기록한 데이터
- Weather : 2010년부터 2013년 동안 미국에서 1600개의 위치에서 수집한 날씨 데이터. 각 datapoint는 11가지의 feature을 가지고 있다.
- Traffic : 캘리포니아의 교통부에서 수집한 hour 단위로 기록된 데이터셋이며, 샌프란시스코 Bay area의 도로 점유율을 기록한 데이터이다.
- Electricity : 321명의 소비자에 의해 소비된 전력량을 시간 단위로 기록한 데이터.
- Exchange Rate : 1990-2016 기간동안 수집됨. 8개의 국가에서 기록된 daily 단위의 환율 변동 데이터
- Covid Deaths : 266개의 국가에서 기록된 Covid-19 사망자 통계
- Taxi : 2015-2016동안 뉴욕에서 30분 간격으로 기록된 택시 승차 데이터
- NN5 : 영국에서 111개의 ATM에서 기록된 현금 인출 데이터 (daily)
- FRED-MD : 1959년부터 연방준비은행이 발표한 거시경제지표 107개
Evaluation Metrics and Setup
MSE와 MAE를 기반으로 하여 평가를 진행하였다.
Result
6가지의 질문에 대해 연구 결과를 설명한다.
Does pretrained language models contribute to forecasting performance?
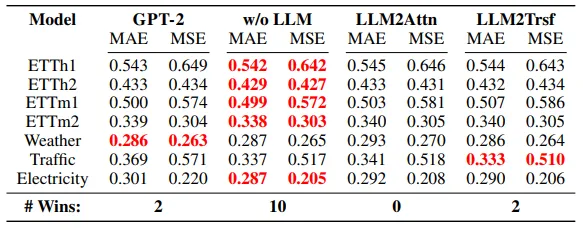
이 연구는 Pretrained LLM이 time series forecasting 작업에 유용하지 않다는 것을 보여준다.
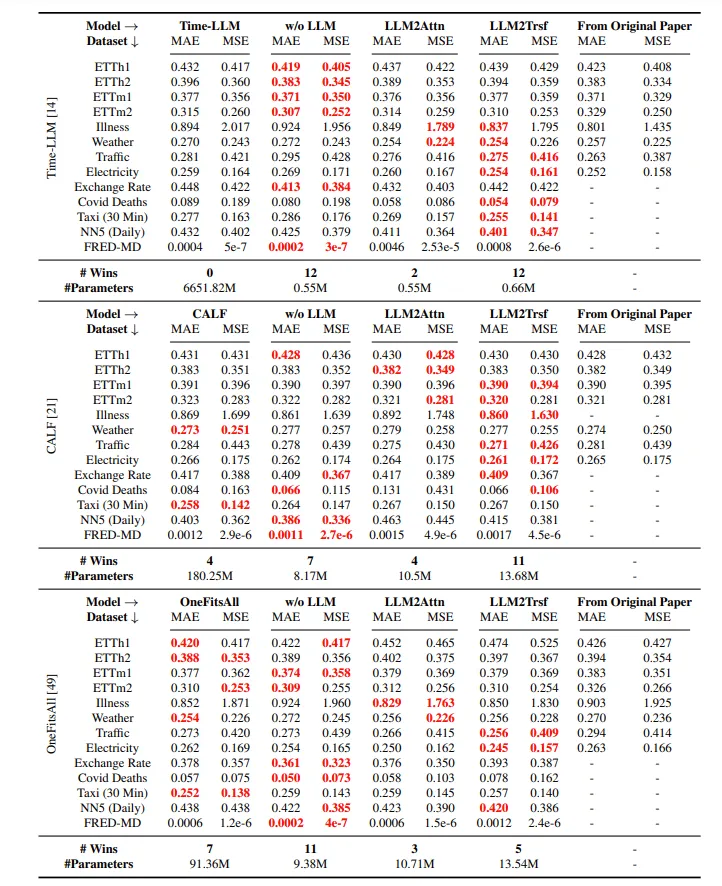
위의 표에서 볼 수 있듯이 13개의 데이터셋과 2개의 metric에서 Time LLM의 경우 ablation method들이 26개 모두 최고의 성능을 달성했으며, CALF는 22/26, OneFitsAll은 19/26이었다. 4개의 예측 길이를 평균낸 결과에서도 (13개의 dataset, 4개의 prediction lengths) ablation method는 Time LLM, CALF, OneFitsAll를 각각 35/40, 31/40, 29/40으로 능가했다 (MAE 기준).
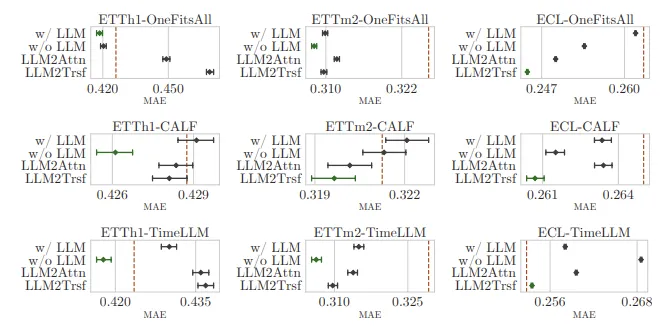
LLM의 성능이 더 높게 나타나는 경우에도 95%의 신뢰구간을 고려한다면 겹치는 부분이 많은 경우가 있다. 따라서 확연하게 LM이 time series forecasting에 효과적이라고 결론내릴 수 없다.
Are LLM-based methods worth the computational cost?
본 연구에서 사용한 LM들은 백만에서 10억개 단위의 parameter을 가지고 있다. LM이 frozen 되어있다고 해도 이러한 parameter들은 training이나 inference 과정에서 overhead를 부여한다.
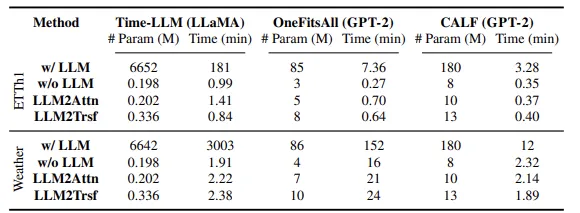
위의 표에서 보이듯이, Time-LLM은 Weather dataset에 대해 6642M의 parameter을 가지며 3003min의 training time이 걸린다. 반면 ablation method는 0.245M의 parameter로 training에 평균 2.17분이 소요된다.
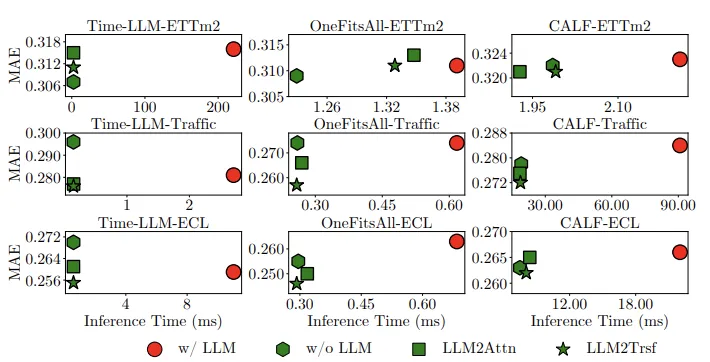
inference time의 경우, maximum batch size로 나누어 example마다의 inference time estimation을 구한다. Time LLM, OneFitAll, CALF는 ablation method보다 평균적으로 각각 28.2, 2.3, 1.2배 느렸다.
Does language model pretraining help performance on forecasting tasks?
결론부터 말하자면, language dataset을 이용하여 pretraining을 하는 것은 time series forecasting에 불필요하다. pretraining에서 학습된 지식이 forecasting 성능을 유의미하게 증가시키는지를 확인하기 위해 CALF를 pretraining과 finetuning을 이용하여 확인해 보았다.
- Pretrain + Finetune (Pre + FT) : original paper에서 했던 방식으로, pretrained된 LM은 time series datat에 대해 finetuning된다. CALF의 경우 LM은 frozen되고 low lank adapter (LoRA)가 학습된다.
- Random Initialization + Finetune (woPre + FT) : LM의 weight를 random하게 초기화 한 뒤 LLM을 scratch로 training한다.
- Pretrain + No Finetuning (Pre + woFT) : Language model은 동결하고, LoRA 역시 학습하지 않는다. 이 결과는 base LM에서 time series를 통한 additional guidance 없이도 얼마나 잘 예측할 수 있는지에 대한 능력을 나타낸다고 볼 수 있다.
- Random Initialization + No Finetuning (woPre + woFT) : input time series에서 forecasting prediction으로의 random projection을 나타내며, 위 3가지 방법들과 비교하는 baseline이 된다.
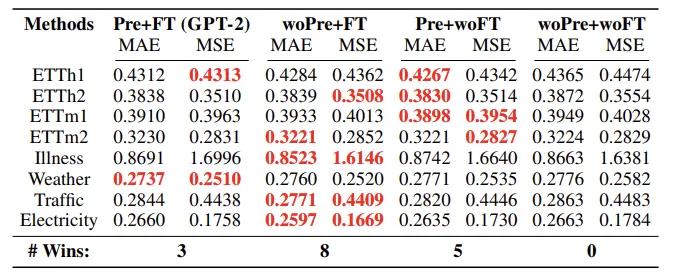
Pretraining + Finetune 전략은 MAE와 MSE를 metric으로 한 8개의 데이터셋 중 3개에서만 최고 성능을 달성했다. 한편 Random Initialization + Finetune은 8개에서 최고성능을 달성하였다. 이는 LM의 prior knowledge가 forecasting에 큰 도움을 주지 못한다는 것을 의미한다. Pretrain + No Finetuning과 Random initialize + No Finetuning의 경우 각각 5개, 0개에서 최고성능을 달성했고, 이는 Language Knowledge가 finetuning process에서 유의미하게 기여하지 않는다는 것을 의미한다.
Do LLMs represent sequential dependencies in time series?
LLM을 이용하여 time series forecasting을 수행할 때 sequence 내에서 timestep의 position을 인코딩하기 위해 positional encoding을 사용한다. positional representation이 좋은 모델은 input이 shuffled되었을 때 forecasting performance가 크게 줄어들 것이라고 가정한다. 본 논문에서는 3가지의 shuffling을 제안한다 : 전체 sequence를 shuffling (sf-all), sequence의 첫 절반만 shuffling (sf-half), 그리고 sequence의 첫 절반과 나머지를 교환하는 방식 (ex-half)이다.
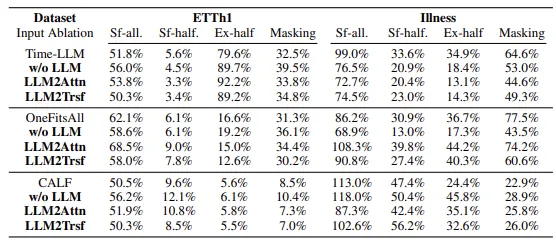
LLM이 time series의 sequential한 정보를 인코딩할 수 있다면 데이터가 섞였을 때 성능이 크게 떨어져야 한다. 하지만 LLM based methods들은 ablation method들과 비교했을 때 shuffling에 크게 취약한 모습을 보이지는 않았다. 이는 LLM이 sequential 한 정보를 표현하는데 큰 영향을 주진 않는다는 것을 의미한다.
Do LLMs help with few shot learning in forecasting?
이 단락에서는 LLM이 few shot learning에서 유용하지 않음을 보여준다. LLM이 time series forecasting에 유용하지는 않지만, pretrained weight에 encoede된 prior knowledge가 few shot setting에 도움을 줄 가능성이 존재한다. 이를 평가하기 위해 각 데이터의 10%만을 가지고 시나리오에 대해 훈련을 진행한다. 우선 Time-LLM의 Llama와 그 ablation method들에 대해 평가하였다.
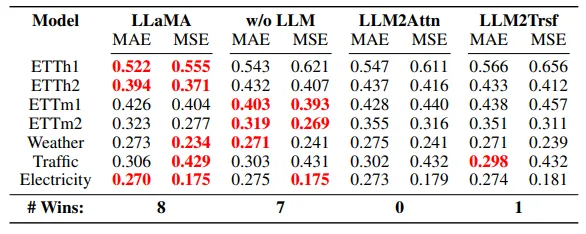
LLama와 LLM을 완전히 제거한 ablation method를 비교하였을 때, 두 경우 모두 8번씩 최고의 성능을 보였으며, 큰 차이가 없었다.
CALF (GPT-2 based)로도 유사한 실험을 진행했고, few shot 환경에서는 ablation이 LLM보다 나은 성능을 발휘할 수 있음을 확인하였다.
Where does the performance come from?
LLM based time series forecasting에 사용되는 encoding을 평가한 결과, patching with one layer attention 기법이 간단하면서도 효율적인 방법임을 발견하였다.
저자들은 LLM 기반 ablation method들이 성능을 저하시키지 않는다는 사실을 확인했다. 이 방법이 왜 효과적인지 확인하기 위해 patching, decomposition, basic transformer block을 각각 encoding으로 사용하여 평가한다.
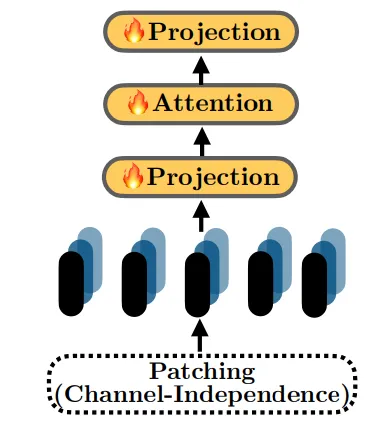
그 결과, patching과 attention을 결합한 구조인 PAttn이 timestamp가 100만개 미만인 소규모 dataset에서 효과적임을 발견하였고, LLM model과도 비교될만한 성능을 보인다 (위의 그림). 자세하게는 시계열 데이터에 instance norm을 적용하고 patching, projection을 진행한다. 이후 1 layer attention을 사용하여 patches간 feature learning을 가능하게 한다.
15M이나 8M 등의 대규모 데이터셋에서는 CALF의 인코더를 사용하는 LTrsf가 가장 좋은 성능을 발휘한다. 여기서는 time series embedding을 single linear layer으로 projection하여 forecasting을 수행한다.
