sharding을 애플리케이션 단에서 구현하려면 sharding key를 정하고 해당 key를 바탕으로 런타임 시점에서 DataSource를 정해야 된다.
이의 구현 과정을 설명해보려고 한다.
동적 DataSourceRouting의 필요성
-
DB에 가해지는 부하를 줄이기 위해서 sharding을 해야겠다고 판단했다.
-
NoSQL의 경우, DB 단에서 알어서 sharding이 일어나기에애플리케이션 단에서 설정할게 없다.
-
하지만 현재 사용하고 있는 DB는 MySQL이기에 애플리케이션 단에서 sharding key를 기준으로 동적으로 DataSource를 결정해야 된다.
sharding key 고르기
- userId를 sharding key로 설정했다.
- 내 비지니스 설정 상, 대부분의 api는 로그인 후에 사용 가능하고, 로그인 시에 session에 현재 유저 정보가 들어가 있다.
ID 생성 전략 수정
-
userId와 postId는 snowflake Id 생성 전략을 사용했다.
-
feed와 같이 모든 DB에서 게시물을 가져와서 id순으로 정렬해서 리턴해야될 때, 만약 auto increment와 같은 자동 생성 전략을 사용한다면 id 값이 중복되어 정렬을 할 수 없게 된다.
-
그래서 ID에 시간 데이터가 포함되어 생성 순으로 정렬할 수 있고, 분산 DB 환경에서도 고유한 ID를 생성할 수 있는 Snowflake ID 생성 전략을 사용했다.
DB 설정 과정
spring:
datasource:
shard0:
jdbc-url: jdbc:mysql://000.00.000.000:3306/outstagram
username: root
password: 1234
driver-class-name: com.mysql.cj.jdbc.Driver
shard1:
jdbc-url: jdbc:mysql://000.00.000.000:3306/outstagram
username: root
password: 1234
dirver-class-name: com.mysql.cj.jdbc.Driver
@Configuration
@EnableTransactionManagement
public class DatabaseConfig {
@Primary
@Bean(name = "shard0")
@ConfigurationProperties(prefix = "spring.datasource.shard0")
public DataSource shard0DataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "shard1")
@ConfigurationProperties(prefix = "spring.datasource.shard1")
public DataSource shard1DataSource() {
return DataSourceBuilder.create().build();
}
@Bean
public DataSource routingDataSource(
@Qualifier("shard0") DataSource shard0DataSource,
@Qualifier("shard1") DataSource shard1DataSource) {
DataSourceRouting dynamicDataSource = new DataSourceRouting();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(0L, shard0DataSource);
dataSourceMap.put(1L, shard1DataSource);
dynamicDataSource.setDefaultTargetDataSource(shard1DataSource);
dynamicDataSource.setTargetDataSources(dataSourceMap);
return dynamicDataSource;
}
}- yaml 파일에 세팅된 DB 정보들을 받아서 모두 Bean으로 설정해놓고 Default로 1번 DB를 설정함
@Slf4j
public class DataSourceRouting extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
Long shardId = null;
if (requestAttributes != null) {
shardId = (Long) requestAttributes.getAttribute("shardId", RequestAttributes.SCOPE_REQUEST);
}
if (shardId == null) shardId = DataSourceContextHolder.getShardId();
if (shardId != null) {
log.info("=============================== Current Shard ID: {}", shardId);
return shardId;
}
log.warn("Request attributes are null, defaulting to shard 0");
return 0L;
}
}- DB에서 쿼리를 날리기 직전마다
determineCurrentLookupKey()가 호출되서 현재RequestContextHolder에 있는shardId값으로 DataSource를 세팅해놓고 쿼리를 수행한다.
public class DataSourceContextHolder {
private static final ThreadLocal<Long> contextHolder = new ThreadLocal<>();
public static void setShardId(Long shardId) {
contextHolder.set(shardId);
}
public static Long getShardId() {
return contextHolder.get();
}
public static void clearShardId() {
contextHolder.remove();
}
}
-
DataSourceContextHolder는 HTTP Request가 들어와서 발생하는 쿼리가 아닌 경우, (예를 들어, scheduler에 의해 발생한 쿼리들) 애초에RequestContextHolder가 존재하질 않는다. -
그래서 이때
shardId세팅을 위해ThreadLocal을 사용한다.
Interceptor 설정
@Slf4j
public class ShardInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HttpSession session = request.getSession(false); // 세션이 없으면 null 반환
if (session != null) {
UserDTO user = (UserDTO) session.getAttribute(LOGIN_USER);
log.info("================ shard 세팅 인터셉터 실행 : user = {}", user);
if (user != null) {
Long shardId = user.getId() % DBConst.DB_COUNT;
RequestContextHolder.getRequestAttributes().setAttribute("shardId", shardId, RequestAttributes.SCOPE_REQUEST);
log.info("================ shard 세팅 완료 : {}", shardId);
}
} else {
log.warn("Session does not exist. Skipping shard ID assignment.");
}
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 요청이 완료된 후에 shardId를 제거
RequestContextHolder.getRequestAttributes().removeAttribute("shardId", RequestAttributes.SCOPE_REQUEST);
}
}@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoggingInterceptor())
.order(1)
.addPathPatterns("/**");
registry.addInterceptor(new LoginCheckInterceptor())
.order(2)
.addPathPatterns("/**")
.excludePathPatterns(
"/api/users/check-duplicated-email", "/api/users/check-duplicated-nickname",
"/api/users/signup", "/api/users/login"
);
registry.addInterceptor(new ShardInterceptor())
.order(3)
.addPathPatterns("/**");
}-
이 인터셉터는
LoginCheckInterceptor뒤에 있다. -
그래서 세션에 저장되어 있는 유저 정보를 바탕으로
userId(sharding key)를 찾아서 DB 개수로 나머지 연산한 값을shardId로RequestContextHolder에 세팅한다. -
요청이 완료되어서 응답으로 나갈 때, 해당
shardId정보를 삭제해준다.
샤딩 로직
- 편의를 위해
userId는 sharding DB 개수가 k라 하면 저장되는 위치는 userId % k 값인 DB에 저장하고 싶다.- 예를 들어
userId = 192834767이고 sharding한 DB의 개수가 3개라면192834767 % 3 = 2-> 2번 DB에 해당 user가 저장되는거다.
- 예를 들어
private long generateId(long shardId) {
long userId;
do {
userId = snowflake.nextId(shardId);
} while (userId % DBConst.DB_COUNT != shardId);
return userId;
}
@Transactional
public void insertUser(Long shardId, UserDTO userInfo) {
// 이메일, 닉네임 중 중복 체크
validateUserInfo(userInfo);
LocalDateTime now = LocalDateTime.now();
long userId = generateId(shardId);
userInfo.setId(userId);
userInfo.setCreateDate(now);
userInfo.setUpdateDate(now);
userInfo.setPassword(encryptedPassword(userInfo.getPassword()));
userMapper.insertUser(userInfo); // mysql에 저장
userProducer.save(USER_UPSERT_TOPIC, userInfo); // elasticsearch db에 저장
}
근데 userId 생성할 때는 sharding key가 없는데?
@PostMapping("/signup")
public ResponseEntity<ApiResponse> signup(@RequestBody @Valid UserDTO userInfo) {
long shardId = System.currentTimeMillis() % DBConst.DB_COUNT;
RequestContextHolder.getRequestAttributes().setAttribute("shardId", shardId, RequestAttributes.SCOPE_REQUEST);
userService.insertUser(shardId, userInfo);
ApiResponse response = ApiResponse.builder()
.isSuccess(true)
.httpStatus(HttpStatus.OK)
.message("회원가입 성공")
.build();
return ResponseEntity.ok(response);
}- 그래서 이 경우에만 현재 시간을 바탕으로 어떤 shard에 저장할지 정한다.
게시물 생성 시에 저장될 DB는?
-
게시물 생성할 때는 현재 유저가 저장되어 있는 DB에 저장하도록 했다.
-
그래서 따로 설정할 필요 없이
ShardInterceptor를 통해서 설정되어 있는 DataSource로 쿼리를 날리면 된다.
그럼 게시물 조회할 때는 모든 DB에 다 조회해봐야 되는거 아니야...?
-
맞다... 게시물 조회 뿐만 아니라, 중복된 ID, nickname 있는지 확인하는 등.. 꽤 많은 곳에서 모든 DB를 조회해봐야 되는 경우가 있었다.
-
그래서 초기에는 각 로직을 아래와 같이 shard DB 개수만큼 반복문을 돌면서 각 DB에 쿼리를 날리고 그 결과를 리턴하도록 수정하려고 했다.
수정 전
@Cacheable(value = POST, key = "#postId")
public PostDTO getPost(Long postId) {
return postMapper.findById(postId);
}수정 후
@Cacheable(value = POST, key = "#postId")
public PostDTO getPost(Long postId) {
for (long shardId = 0; shardId < DB_COUNT; shardId++) {
RequestContextHolder.getRequestAttributes().setAttribute("shardId", shardId, RequestAttributes.SCOPE_REQUEST);
PostDTO post = postMapper.findById(postId);
if (post == null) {
log.warn("No post details found in shard {}", shardId);
RequestContextHolder.getRequestAttributes().removeAttribute("shardId", RequestAttributes.SCOPE_REQUEST);
continue;
}
return post;
}
return null;
}-
이렇게 모든 DB를 조회하는 메서드들에 위와 같은 반복문을 다 넣으려고 했다.
-
즉, 각 메서드를 DataSource를 바꿔 가면서 모두 질의해보는 방식이다.
-
근데 이건 현재 메서드에 무관한 관심사이고 여러 부분에서 공통적으로 사용되는 로직이니깐 Spring AOP로 이 로직을 추출해낼 수 있을 것 같았다.
Spring AOP로 DataSource 바꿔가면서 쿼리 날리도록 구현해보기
@Slf4j
@Component
@Aspect
public class QueryAllShardsAspect {
private static final int SHARD_COUNT = (int) DB_COUNT;
private final ExecutorService executor = Executors.newFixedThreadPool(SHARD_COUNT);
@Pointcut("@annotation(com.outstagram.outstagram.common.annotation.QueryAllShards)")
public void queryAll() {
}
@Around("queryAll()")
public Object queryAllShards(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("============== @QueryAllShards Started");
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
CompletableFuture<Object>[] futures = new CompletableFuture[SHARD_COUNT];
for (int shardId = 0; shardId < SHARD_COUNT; shardId++) {
final int currentShardId = shardId;
futures[shardId] = CompletableFuture.supplyAsync(() -> {
// 비동기 스레드에서 RequestAttributes를 설정합니다.
RequestContextHolder.setRequestAttributes(requestAttributes);
RequestContextHolder.getRequestAttributes().setAttribute("shardId", currentShardId,
ServletRequestAttributes.SCOPE_REQUEST);
try {
return joinPoint.proceed();
} catch (Throwable throwable) {
throwable.printStackTrace();
return null;
} finally {
RequestContextHolder.getRequestAttributes().removeAttribute("shardId", RequestAttributes.SCOPE_REQUEST);
}
}, executor);
}
for (int shardId = 0; shardId < SHARD_COUNT; shardId++) {
Object result = futures[shardId].get();
if (result != null) {
RequestContextHolder.getRequestAttributes().setAttribute("shardId", shardId, ServletRequestAttributes.SCOPE_REQUEST);
return result;
}
}
return null;
}
}@Cacheable(value = POST, key = "#postId")
@QueryAllShards
public PostDTO getPost(Long postId) {
return postMapper.findById(postId);
}-
@QueryAllShards가 달린 메서드는 실제 해당 메서드(getPost()) 수행하기 전에RequestContextHolder에shardId를 설정하고 실제 메서드를 수행시키고 그 결과를 담아놓는다. -
각 실행을 비동기적으로 수행하고 모든 DB에 쿼리를 다 날리고 결과가 돌아오면 그걸 반환하도록 구현했다.
❌ 문제점...
-
혹시 이상한 점을 눈치 채셨는지...?
-
DB에 가해지는 부하를 줄이려고 sharding을 통해 현재 DB를 2개로 나눴는데, 이렇게 전체 DB를 확인해봐야 하는 경우, 모든 DB에 질의해야된다.
-
물론 비동기적으로 각 DB에 쿼리를 날리기 때문에 성능이 많이 저하되진 않을 것 같지만
-
그래도 하나의 DB에 가해지는 부하가 1이라고 했을 때, 0.5, 0.5 씩 나누려고 sharding을 했지만 이건 1, 1씩 부하를 주는 꼴인 것 같았다.
⭐ 해결방안
-
생각해보니, 해당
postId가 어떤 DB에 저장되었는지를 모르니깐 모든 DB에 질의해서 알아내야 된다. -
그럼 게시물을 생성할 때, 해당
postId와shardId를 캐시해놓으면 나중에 게시물 조회할 때, 캐시에서 찾아보고 있으면 그shardId로 세팅해서 DB에 조회해보면 된다. -
만약 캐시에 없다면, 그 때 모든 DB에 조회해서 몇 번째 shard에 저장되었는지 파악하고 캐시 해놓으면 된다.
Spring AOP를 통해 캐시에 postId - shardId 매핑 정보 저장하기 or 가져오기
캐시에 매핑 정보 저장하기
@Slf4j
@Component
@Aspect
@RequiredArgsConstructor
public class CachePostIdToShardIdAspect {
private final RedisTemplate<String, Object> redisTemplate;
@Around("@annotation(cachePostIdToShardId)")
public Object queryAllShards(ProceedingJoinPoint joinPoint, CachePostIdToShardId cachePostIdToShardId) throws Throwable {
log.info("============== @CacheShardId Started");
Object result = joinPoint.proceed();
Long postId = ((PostDTO) result).getId();
Long shardId = (Long) RequestContextHolder.getRequestAttributes().getAttribute("shardId", RequestAttributes.SCOPE_REQUEST);
redisTemplate.opsForValue().set(postId.toString(), shardId);
log.info("============== Cached shardId: {} for postId : {}", shardId, postId);
return result;
}
}
@Transactional
@CachePostIdToShardId
public PostDTO insertPost(CreatePostReq createPostReq, Long userId) {
...
}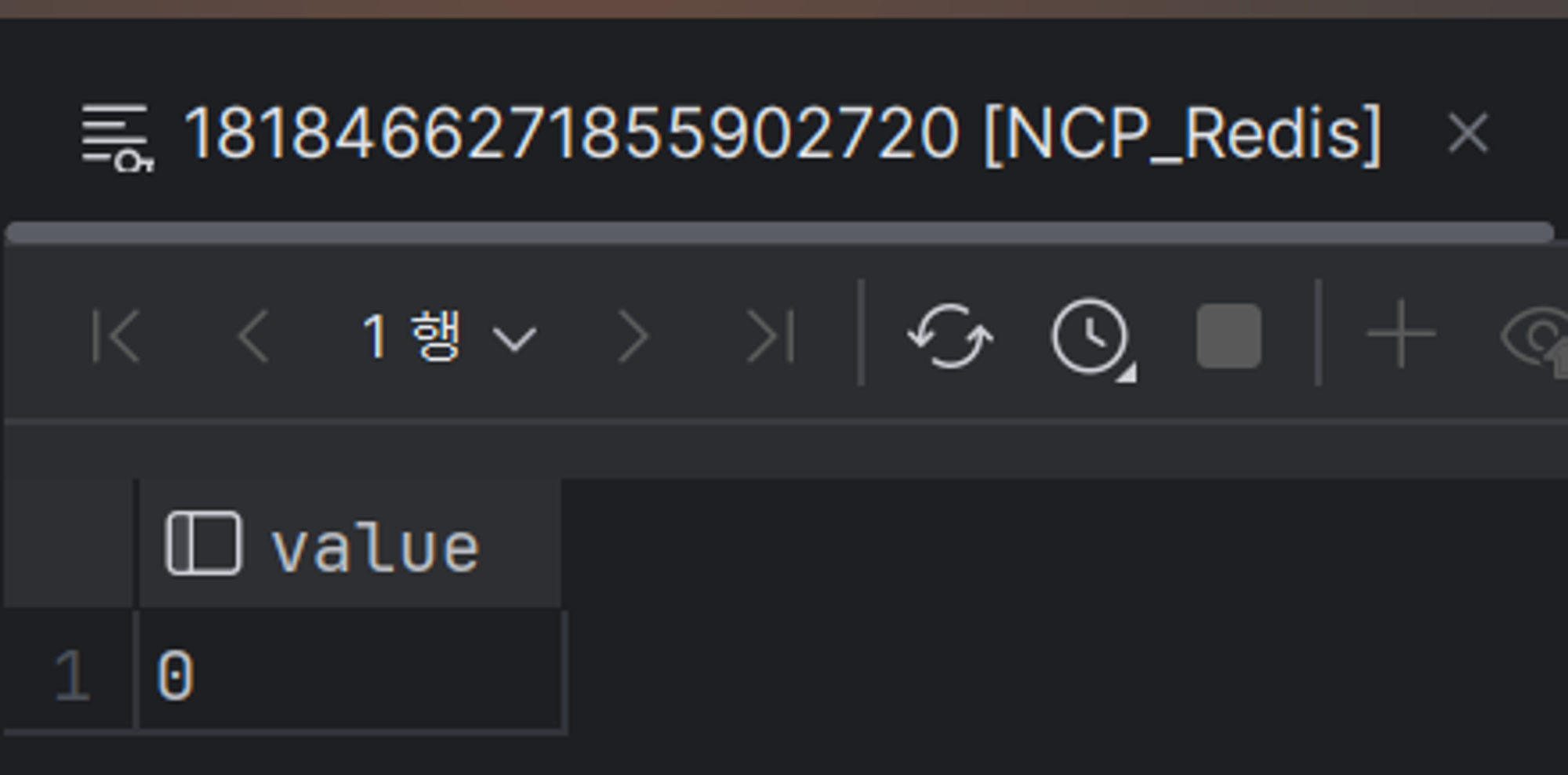
-
이렇게
@CachePostIdToShardId달려 있으면 해당 메서드의 리턴값을 통해 postId와 현재 로그인한 유저의 shardId를 캐시에 저장해놓는다. -
위 예시는
postId = 1818466271855902720가shardId = 0에 저장되어 있다는 매핑 정보다.
캐시에서 매핑 정보 가져와서 DataSource 세팅하기
@Slf4j
@Component
@Aspect
@RequiredArgsConstructor
public class LoadShardIdFromPostIdAspect {
private final RedisTemplate<String, Object> redisTemplate;
private final PostMapper postMapper;
@Around("@annotation(loadShardIdFromPostId) && args(postId, ..)")
public Object queryAllShards(ProceedingJoinPoint joinPoint, LoadShardIdFromPostId loadShardIdFromPostId, Long postId) throws Throwable {
log.info("============== @LoadShardIdFromPostId Started");
Long currentShardId = (Long) RequestContextHolder.getRequestAttributes().getAttribute("shardId", RequestAttributes.SCOPE_REQUEST);
Object shardId = redisTemplate.opsForValue().get(postId.toString());
if (shardId != null) {
RequestContextHolder.getRequestAttributes().setAttribute("shardId", Long.valueOf(shardId.toString()), RequestAttributes.SCOPE_REQUEST);
log.info("============== Loaded shardId : {} for postId : {}", shardId, postId);
} else {
// 모든 db에 조회해서 shardId 찾아내기
log.info("============== ShardId not found in cache, querying all shards");
Long shard = queryAllShardsForPostId(postId);
if (shard != null) {
redisTemplate.opsForValue().set(postId.toString(), shard);
RequestContextHolder.getRequestAttributes().setAttribute("shardId", shard, RequestAttributes.SCOPE_REQUEST);
log.info("============== Found and cached shardId : {} for postId : {}", shard, postId);
} else {
log.info("============== PostId not found in DB and in cache!!! postId : {}", postId);
throw new ApiException(ErrorCode.POST_NOT_FOUND);
}
}
try {
return joinPoint.proceed();
} finally {
// 기존 shardId(현재 로그인한 유저가 저장된 shardId)로 다시 전환
RequestContextHolder.getRequestAttributes().setAttribute("shardId", currentShardId, RequestAttributes.SCOPE_REQUEST);
log.info("============== Restored original shardId : {}", currentShardId);
}
}
private Long queryAllShardsForPostId(Long postId) throws Exception {
List<CompletableFuture<Long>> futures = new ArrayList<>();
for (long shardId = 0; shardId < DB_COUNT; shardId++) {
futures.add(findById(postId, shardId));
}
CompletableFuture<Void> allFutures = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
allFutures.join();
for (CompletableFuture<Long> future : futures) {
Long shardId = future.get();
if (shardId != -1) {
return shardId;
}
}
return null;
}
@Async
protected CompletableFuture<Long> findById(Long postId, Long shardId) {
RequestContextHolder.getRequestAttributes().setAttribute("shardId", shardId, RequestAttributes.SCOPE_REQUEST);
PostDTO post = postMapper.findById(postId);
RequestContextHolder.getRequestAttributes().removeAttribute("shardId", RequestAttributes.SCOPE_REQUEST);
return CompletableFuture.completedFuture(post != null ? shardId : -1);
}@LoadShardIdFromPostId // postId로 cache에서 매핑된 shardId 찾아서 RequestContextHolder에 넣어줌
public PostDetailsDTO getPostDetails(Long postId, Long userId) {
...
}-
@LoadShardIdFromPostId이 달려 있고 매개변수에postId가 있다면queryAllShards가 호출된다. -
이 메서드는 캐시에 해당
postId가 있다면 매핑된shardId값을RequestContextHolder에 세팅해놓는다. -
만약 없다면 비동기적으로 모든 DB를 조회해서
shardId찾아서 세팅하고 캐시해놓는다. -
그리고 마지막에
finally구문에서 기존shardId로 원복해놓는다.
로그를 통해 잘 적용되었는지 확인해보자
INFO c.o.o.c.i.LoggingInterceptor - REQUEST [53a7e8f0-61e0-40a4-ad59-8efb1d12ff5b][/api/posts/1818466782868934656][com.outstagram.outstagram.controller.PostController#getPost(Long, UserDTO)]
INFO c.o.o.c.i.LoginCheckInterceptor - 인증 체크 인터셉터 실행 /api/posts/1818466782868934656
1. INFO c.o.o.c.interceptor.ShardInterceptor - ================ shard 세팅 인터셉터 실행 : user = UserDTO(id=1816358736130740225, nickname=user_1d76ea1c-78c4-4f73-a61c-0085c9f3571c, email=1d76ea1c-78c4-4f73-a61c-0085c9f3571c@test.com, password=null, imgUrl=null, isDeleted=null, createDate=null, updateDate=null)
INFO c.o.o.c.interceptor.ShardInterceptor - ================ shard 세팅 완료 : 1
INFO c.o.o.common.aop.LoginAspect - AOP - @Login Check Started
3. INFO c.o.o.c.a.LoadShardIdFromPostIdAspect - ============== @LoadShardIdFromPostId Started
4. INFO c.o.o.c.a.LoadShardIdFromPostIdAspect - ============== ShardId not found in cache, querying all shards
INFO c.o.o.c.database.DataSourceRouting - =============================== Current Shard ID: 0
DEBUG c.o.o.mapper.PostMapper.findById - ==> Preparing: SELECT id, user_id, contents, likes, create_date, update_date FROM post WHERE id = ? AND is_deleted = 0
DEBUG c.o.o.mapper.PostMapper.findById - ==> Parameters: 1818466782868934656(Long)
DEBUG c.o.o.mapper.PostMapper.findById - <== Total: 0
INFO c.o.o.c.database.DataSourceRouting - =============================== Current Shard ID: 1
DEBUG c.o.o.mapper.PostMapper.findById - ==> Preparing: SELECT id, user_id, contents, likes, create_date, update_date FROM post WHERE id = ? AND is_deleted = 0
DEBUG c.o.o.mapper.PostMapper.findById - ==> Parameters: 1818466782868934656(Long)
TRACE c.o.o.mapper.PostMapper.findById - <== Columns: id, user_id, contents, likes, create_date, update_date
TRACE c.o.o.mapper.PostMapper.findById - <== Row: 1818466782868934656, 1816358736130740225, <<BLOB>>, 0, 2024-07-31 11:00:41, 2024-07-31 11:00:41
DEBUG c.o.o.mapper.PostMapper.findById - <== Total: 1
4. INFO c.o.o.c.a.LoadShardIdFromPostIdAspect - ============== Found and cached shardId : 1 for postId : 1818466782868934656
5. INFO c.o.o.c.database.DataSourceRouting - =============================== Current Shard ID: 1
DEBUG c.o.o.mapper.PostMapper.findById - ==> Preparing: SELECT id, user_id, contents, likes, create_date, update_date FROM post WHERE id = ? AND is_deleted = 0
DEBUG c.o.o.mapper.PostMapper.findById - ==> Parameters: 1818466782868934656(Long)
TRACE c.o.o.mapper.PostMapper.findById - <== Columns: id, user_id, contents, likes, create_date, update_date
TRACE c.o.o.mapper.PostMapper.findById - <== Row: 1818466782868934656, 1816358736130740225, <<BLOB>>, 0, 2024-07-31 11:00:41, 2024-07-31 11:00:41
DEBUG c.o.o.mapper.PostMapper.findById - <== Total: 1
INFO c.o.o.c.database.DataSourceRouting - =============================== Current Shard ID: 1
DEBUG c.o.o.m.I.findImagesByPostId - ==> Preparing: SELECT id, img_url FROM image WHERE post_id = ? AND is_deleted = 0 ORDER BY id
DEBUG c.o.o.m.I.findImagesByPostId - ==> Parameters: 1818466782868934656(Long)
TRACE c.o.o.m.I.findImagesByPostId - <== Columns: id, img_url
TRACE c.o.o.m.I.findImagesByPostId - <== Row: 3, C:\Users\andan\OneDrive\바탕 화면\outstagram\com.outstagram.upload.pathe14cb192-atest.PNG
DEBUG c.o.o.m.I.findImagesByPostId - <== Total: 1
INFO c.o.o.c.database.DataSourceRouting - =============================== Current Shard ID: 1
DEBUG c.o.o.mapper.UserMapper.findById - ==> Preparing: SELECT id, nickname, img_url, email, create_date, update_date FROM user WHERE id = ? AND is_deleted = 0
DEBUG c.o.o.mapper.UserMapper.findById - ==> Parameters: 1816358736130740225(Long)
TRACE c.o.o.mapper.UserMapper.findById - <== Columns: id, nickname, img_url, email, create_date, update_date
TRACE c.o.o.mapper.UserMapper.findById - <== Row: 1816358736130740225, user_1d76ea1c-78c4-4f73-a61c-0085c9f3571c, null, 1d76ea1c-78c4-4f73-a61c-0085c9f3571c@test.com, 2024-07-25 15:24:04, 2024-07-25 15:24:04
DEBUG c.o.o.mapper.UserMapper.findById - <== Total: 1
INFO c.o.o.c.database.DataSourceRouting - =============================== Current Shard ID: 1
DEBUG c.o.o.mapper.PostMapper.findById - ==> Preparing: SELECT id, user_id, contents, likes, create_date, update_date FROM post WHERE id = ? AND is_deleted = 0
DEBUG c.o.o.mapper.PostMapper.findById - ==> Parameters: 1818466782868934656(Long)
TRACE c.o.o.mapper.PostMapper.findById - <== Columns: id, user_id, contents, likes, create_date, update_date
TRACE c.o.o.mapper.PostMapper.findById - <== Row: 1818466782868934656, 1816358736130740225, <<BLOB>>, 0, 2024-07-31 11:00:41, 2024-07-31 11:00:41
DEBUG c.o.o.mapper.PostMapper.findById - <== Total: 1
INFO c.o.o.c.database.DataSourceRouting - =============================== Current Shard ID: 1
DEBUG c.o.o.m.CommentMapper.findByPostId - ==> Preparing: SELECT c1.id AS commentId, u1.id AS userId, c1.post_id AS postId, c1.parent_comment_id AS parentCommentId, c1.level AS level, u1.img_url AS userImgUrl, u1.nickname AS nickname, IF(c1.is_deleted = 1, '삭제된 댓글입니다.', c1.contents) AS contents, c1.create_date AS createDate, c1.update_date AS updateDate, c2.id AS replyId, u2.id AS replyUserId, c2.parent_comment_id AS replyParentCommentId, c2.level AS replyLevel, u2.img_url AS replyUserImgUrl, u2.nickname AS replyNickname, IF(c2.is_deleted = 1, '삭제된 대댓글입니다.', c2.contents) AS replyContents, c2.create_date AS replyCreateDate, c2.update_date AS replyUpdateDate FROM comment AS c1 JOIN user AS u1 ON c1.user_id = u1.id LEFT JOIN comment AS c2 ON c1.id = c2.parent_comment_id LEFT JOIN user AS u2 ON c2.user_id = u2.id WHERE c1.post_id = ? AND c1.parent_comment_id IS NULL ORDER BY c1.id, c2.id
DEBUG c.o.o.m.CommentMapper.findByPostId - ==> Parameters: 1818466782868934656(Long)
DEBUG c.o.o.m.CommentMapper.findByPostId - <== Total: 0
6. INFO c.o.o.c.a.LoadShardIdFromPostIdAspect - ============== Restored original shardId : 1
INFO c.o.o.c.i.LoggingInterceptor - RESPONSE [53a7e8f0-61e0-40a4-ad59-8efb1d12ff5b][/api/posts/1818466782868934656]
-
로그인 한 유저가 요청을 보내면
ShardInterceptor에서 세션에 저장된user를 가지고shardId를 파악한다 -
그 다음에는 컨트롤러에서
PostService의getPostDetails()메서드를 호출함 -
getPostDetails()는@LoadShardIdFromPostId달려있기에LoadShardIdFromPostIdAspect로직이 동작함 -
캐시에 postId-shardId 매핑 정보 있는지 확인 → 현재 경우엔 없어서 모든 DB에 비동기적으로 질의
-
1번 shard에
1818466782868934656이 게시물 id 가 있는걸 확인해서 현재 조회할 db를 1번 shard로 세팅 -
getPostDetails()메서드 끝나고 원래shardId로 다시 복원
이게 맞나...?
-
솔직히 이렇게 sharding 구현하는게 맞나 싶긴 하다...
-
내가 아직 생각이 짧아서 이렇게 뭔가 복잡하게 샤딩을 구현하는 것 같다.
-
그래도 내가 할 수 있는 범위 내에서 최대한 애플리케이션 단에서의 샤딩을 구현해보려고 노력했다.
