
[2026/01/06] 기본 ai 사용 구조 확인 및 진행방식 확인
[2026/01/07] 테이블 명세서 / ERD / api 명세서 작성으로 인해서 코드작업 ❌
코드 작업 시작 전 다른 주제의 ai 예시코드 확인
[2026/01/08] 욕설 비속어 1차 거르기 코드
[2026/01/09] 리뷰 생성 모델 등록 및 리뷰 등록 시리얼라이즈 작성
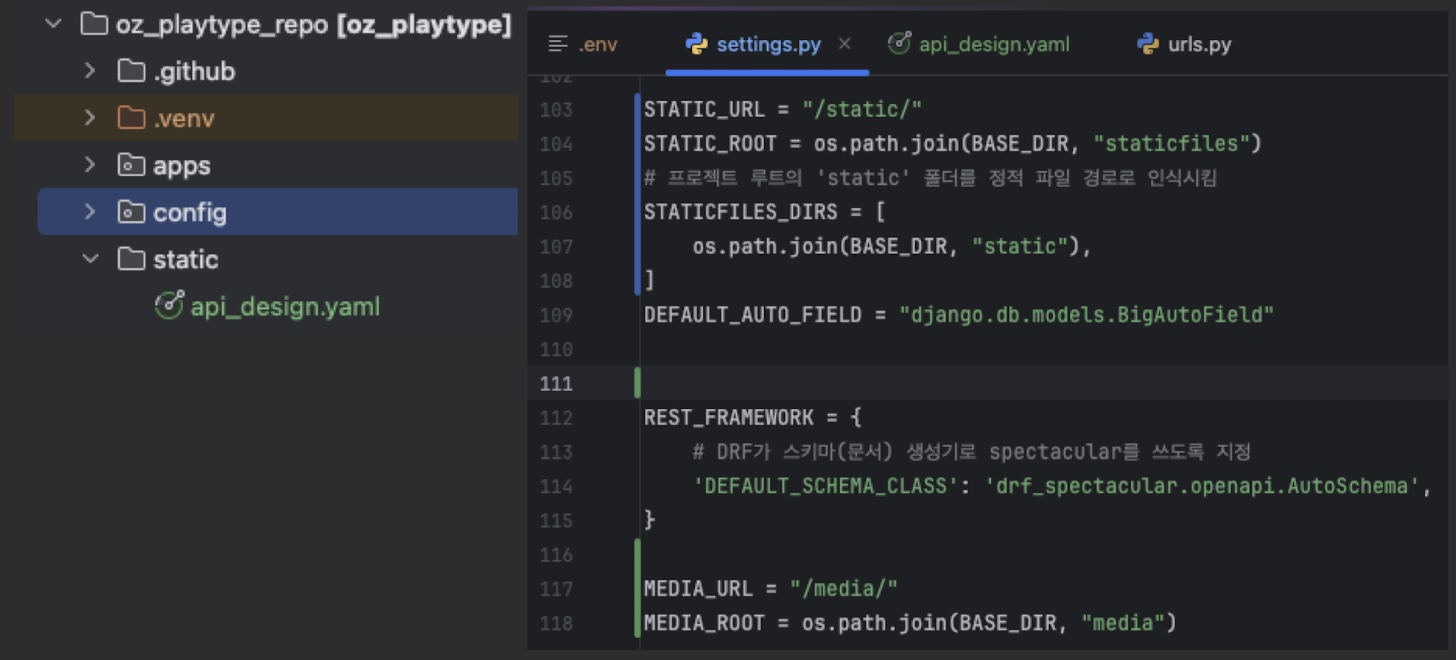
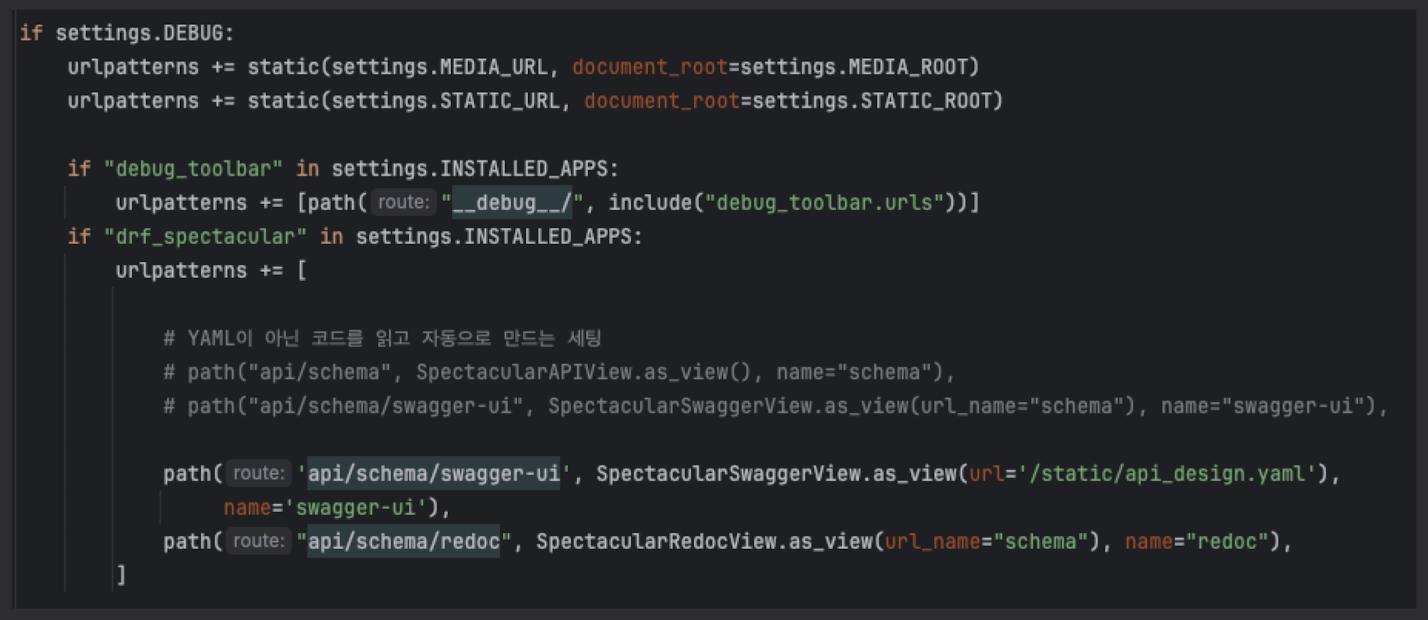
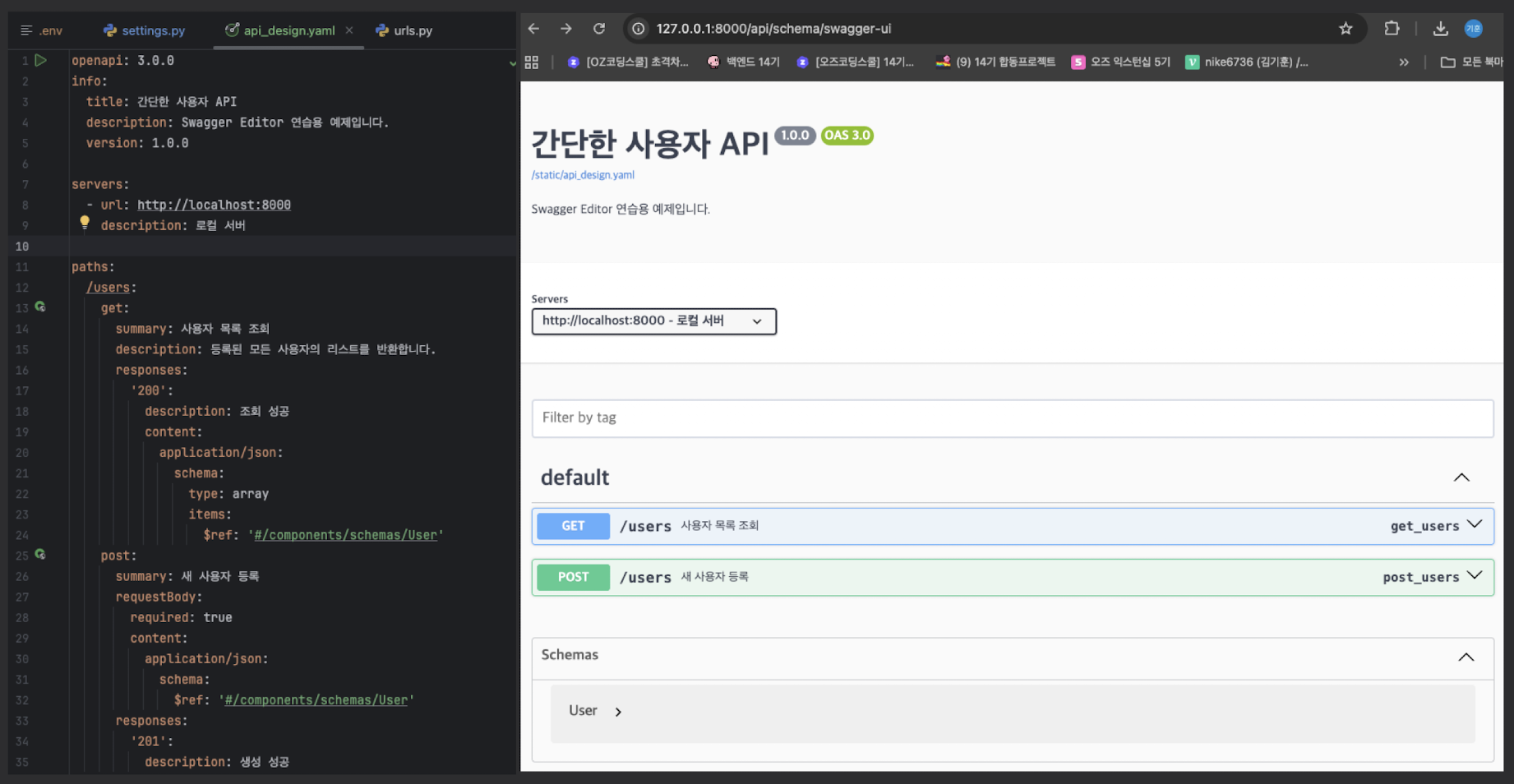
[2026/01/10~11] swagger 기본 세팅 추가
코드 자동변경이 아닌 초반 YAML파일 보여주기 세팅
2026.01.06 ✅
google-generativeai
사전 준비
pip install django rest_framework google-generativeai django-environ
# views.py
import google.generativeai as genai
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from django.conf import settings
from .models import Review
from .serializers import ReviewSerializer
# 1. Gemini API 설정: Google AI Studio에서 발급받은 API 키를 시스템에 등록합니다.
genai.configure(api_key="YOUR_GEMINI_API_KEY")
class ReviewSummaryAPIView(APIView):
"""
특정 페이지의 리뷰를 가져와 AI로 요약해주는 API View
"""
def get(self, request):
# 2. 페이지네이션 처리: URL 쿼리 파라미터에서 page를 가져오며, 숫자가 아닐 경우 400 에러를 반환합니다.
try:
page = int(request.query_params.get('page', 1))
except ValueError:
return Response({"error": "Invalid page number"}, status=status.HTTP_400_BAD_REQUEST)
# 3. 데이터 슬라이싱: 한 페이지당 10개씩 최신순으로 리뷰를 DB에서 조회합니다.
page_size = 10
start_index = (page - 1) * page_size
end_index = page * page_size
reviews = Review.objects.all().order_by('-created_at')[start_index:end_index]
# 4. 예외 처리: 만약 해당 페이지에 데이터가 없다면 404 응답을 보냅니다.
if not reviews:
return Response({"message": "해당 페이지에 리뷰가 없습니다."}, status=status.HTTP_404_NOT_FOUND)
# 5. 프롬프트 구성: 각 리뷰 앞에 '-'를 붙여 리스트화하고, AI에게 요약 규칙(3줄 이내)을 지시합니다.
review_contents = [f"- {r.content}" for r in reviews]
combined_text = "\n".join(review_contents)
prompt = f"""
다음은 쇼핑몰의 고객 리뷰들이다.
전체적인 분위기와 핵심 내용을 파악해서 3줄 이내로 요약해줘.
리뷰 내용:
{combined_text}
"""
try:
# 6. AI 모델 호출: 성능과 비용을 고려해 'gemini-1.5-flash' 모델을 사용해 텍스트를 생성합니다.
model = genai.GenerativeModel('gemini-1.5-flash')
response = model.generate_content(prompt)
summary = response.text
except Exception as e:
# 7. 에러 핸들링: 외부 API 장애 시 서비스 전체가 멈추지 않도록 기본 에러 메시지를 할당합니다.
summary = "AI 요약 중 오류가 발생했습니다."
# 8. 직렬화 및 반환: 리뷰 리스트는 JSON 형태로 변환하고 요약본과 함께 응답 데이터로 구성합니다.
serializer = ReviewSerializer(reviews, many=True)
return Response({
"current_page": page,
"summary": summary,
"reviews": serializer.data
}, status=status.HTTP_200_OK)
# [코드 요약 설명]
# 이 API는 클라이언트가 요청한 '페이지'의 리뷰를 가져와서, 이를 하나로 묶어 Gemini AI에게 전달합니다.
# AI로부터 받은 요약 텍스트와 원본 리뷰 데이터를 JSON 형태로 함께 응답하여
# 사용자 화면에서 요약문과 개별 리뷰를 동시에 보여줄 수 있게 설계되었습니다.
# [코드 설명]
# 1. genai.configure를 통해 구글 API 키를 설정
# 2. DB 슬라이싱을 이용해 요청받은 페이지에 해당하는 리뷰 10개를 가져옴
# 3. 리스트 컴프리헨션을 사용하여 AI가 읽기 좋게 리뷰들을 하나의 문자열(combined_text)로 합침
# 4. GenerativeModel('gemini-1.5-flash')를 생성하고 generate_content() 함수로 요약 결과를 받음
# 5. AI 요약본(summary)과 원본 리뷰 리스트(serializer.data)를 딕셔너리 형태로 묶어 최종 응답# 캐싱 로직 추가
from django.core.cache import cache
def get(self, request):
page = request.query_params.get('page', 1)
cache_key = f"summary_page_{page}"
# 1. 캐시에 저장된 요약본이 있는지 확인
cached_summary = cache.get(cache_key)
if cached_summary:
return Response({"summary": cached_summary, "source": "cache"})
# 2. 캐시에 없으면 AI 호출
summary = call_gemini_api(review_text)
# 3. 결과를 캐시에 저장 (예: 1시간 동안 유지)
cache.set(cache_key, summary, 3600)
return Response({"summary": summary, "source": "ai_api"})
# [코드 설명]
# 1. Django의 내장 캐시 시스템을 사용하여 불필요한 API 호출을 방지
# 2. 특정 페이지 번호를 키값(cache_key)으로 생성하여 저장
# 3. AI 응답이 성공하면 그 내용을 1시간(3600초) 동안 보관하여 다음 요청 시 바로 반환# 한도 에러
try:
model = genai.GenerativeModel('gemini-1.5-flash')
response = model.generate_content(prompt)
summary = response.text
except Exception as e:
# 한도 초과(429) 또는 네트워크 오류 시 사용자에게 보여줄 메시지
summary = "현재 요청이 많아 요약 기능을 잠시 사용할 수 없습니다. 나중에 다시 시도해주세요."
# 로깅을 남겨서 관리자가 알 수 있게 함
print(f"API Error: {e}")
# [코드 분석]
# 1. API 호출 부분을 try-except로 감싸는 것이 매우 중요합니다.
# 2. 한도 초과 시 서비스 전체가 멈추는 대신, '요약만' 안 나오게 처리하여 안정성을 높입니다.캐싱 적용
- 딱히 요약된 리뷰의 내용은 저장할 필요가 없기 때문에 모델은 필요없다
from django.core.cache import cache # 장고의 캐시 모듈 임포트
class ReviewSummaryAPIView(APIView):
def get(self, request):
page = request.query_params.get('page', 1)
# 1. 고유한 캐시 키 생성 (페이지 번호 포함)
cache_key = f"review_summary_page_{page}"
# 2. 캐시에서 먼저 데이터가 있는지 확인
cached_data = cache.get(cache_key)
if cached_data:
# 캐시에 데이터가 있다면 AI 호출 없이 바로 반환
return Response(cached_data, status=status.HTTP_200_OK)
# --- 캐시에 데이터가 없을 때만 아래 로직 실행 (AI 호출) ---
# (기존의 리뷰 조회 및 Gemini API 호출 로직 생략...)
summary = "AI가 요약한 내용..."
response_data = {
"current_page": page,
"summary": summary,
"reviews": serializer.data
}
# 3. 결과를 캐시에 저장 (3600초 = 1시간 동안 보관)
cache.set(cache_key, response_data, 3600)
return Response(response_data, status=status.HTTP_200_OK)
# [코드 설명]
# 1. cache.get(key)를 통해 이미 요약된 내용이 있는지 확인합니다.
# 2. 데이터가 있다면 즉시 반환하여 Gemini API 호출 비용을 아낍니다.
# 3. 데이터가 없다면 API를 호출한 뒤, 그 결과를 cache.set(key, value, timeout)으로 저장합니다.
# 4. 이렇게 하면 1시간 동안은 똑같은 페이지 요청에 대해 돈이 한 푼도 들지 않습니다.2026.01.07 ✅
openai
openai라이브러리를 사용하여 구현한 예시- 요청이 들어오면 DB에서 리뷰를 가져와
GPT에게 요약을 요청
- 요청이 들어오면 DB에서 리뷰를 가져와
import openai
from django.conf import settings
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from .models import Review, Product # 예시 모델
class ReviewSummaryView(APIView):
"""
특정 상품에 대한 리뷰들을 모아 AI를 통해 요약본을 생성하는 API
"""
def post(self, request):
try:
# 1. 클라이언트로부터 상품 ID 받기
product_id = request.data.get('product_id')
if not product_id:
return Response({"error": "product_id is required"}, status=status.HTTP_400_BAD_REQUEST)
# 2. 해당 상품의 리뷰 데이터 조회 (최신 50개 등으로 제한 권장)
reviews = Review.objects.filter(product_id=product_id).values_list('content', flat=True)[:50]
if not reviews:
return Response({"message": "요약할 리뷰가 없습니다."}, status=status.HTTP_200_OK)
# 3. 리뷰 텍스트 전처리 (하나의 문자열로 결합)
combined_reviews = "\n".join(reviews)
# 4. OpenAI API 호출하여 요약 생성
summary_text = self._call_ai_summary(combined_reviews)
return Response({"summary": summary_text}, status=status.HTTP_200_OK)
except Exception as e:
# 실무에서는 로깅을 추가하는 것이 좋습니다.
return Response({"error": str(e)}, status=status.HTTP_500_INTERNAL_SERVER_ERROR)
def _call_ai_summary(self, text_data):
"""
OpenAI API를 호출하는 내부 메서드
"""
client = openai.OpenAI(api_key=settings.OPENAI_API_KEY)
# AI에게 역할을 부여하고 데이터 전달
prompt = f"다음은 고객들의 리뷰 모음이야. 이 내용들을 바탕으로 장점과 단점을 포함해서 3줄로 핵심만 요약해줘:\n\n{text_data}"
response = client.chat.completions.create(
model="gpt-3.5-turbo", # 또는 gpt-4o
messages=[
{"role": "system", "content": "당신은 쇼핑몰 리뷰를 분석하고 요약해주는 AI 어시스턴트입니다."},
{"role": "user", "content": prompt}
],
temperature=0.5, # 0에 가까울수록 일관된 답변, 1에 가까울수록 창의적 답변
)
return response.choices[0].message.content
# [코드 분석]
# 1. APIView 구조 (ReviewSummaryView)
# - post 메서드를 사용하여 데이터를 처리
# - 요약 생성은 비용(API 호출)과 시간이 드는 작업이므로,
# - 단순히 조회하는 GET보다는 POST가 의미론적으로 적합할 수 있음
# (단, 캐싱된 요약을 조회만 한다면 GET 사용)
#
# 2. 리뷰 데이터 조회 (Review.objects.filter...)
# - `values_list('content', flat=True)`를 사용하여 ORM 객체가 아닌
# - 리뷰 내용(텍스트) 리스트만 가볍게 가져옴
# - `[:50]` 슬라이싱: 토큰 제한과 API 비용 절약을 위해 너무 많은 리뷰를
# - 한 번에 보내지 않도록 개수를 제한하는 것이 중요함
#
# 3. 데이터 전처리 ("\n".join(reviews))
# - AI가 각 리뷰를 구분할 수 있도록 줄바꿈 문자로 연결하여 하나의 긴 문자열로 만듬
#
# 4. _call_ai_summary 메서드 (AI 연동 핵심)
# - `openai.OpenAI`: 최신 SDK 버전에 맞춘 클라이언트 인스턴스 생성 방식
# - `messages`:
# - `system`: AI의 페르소나를 정의 (ex. 너는 리뷰 분석가야)
# - `user`: 실제 요약할 데이터와 구체적인 지시사항(3줄 요약 등)을 전달
# - `temperature`: 요약문은 사실에 기반해야 하므로 너무 높지 않게(0.3~0.5) 설정하는 것이 좋음
#
# - 토큰 관리: 리뷰가 너무 많으면 API 비용이 많이 들고 입력 한도를 초과할 수 있음
# - 텍스트를 자르거나(Truncation), 최신 리뷰 N개만 사용하는 전략이 필요
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Review
from .serializers import ReviewSerializer
import openai # OpenAI 사용
class ReviewSummaryAPIView(APIView):
def get(self, request):
page = request.query_params.get('page', 1)
# 1. 특정 페이지의 리뷰 쿼리셋 가져오기 (예: 10개씩)
reviews = Review.objects.all().order_update('-created_at')[(int(page)-1)*10 : int(page)*10]
# 2. 요약을 위해 리뷰 텍스트 합치기
review_text = " ".join([r.content for r in reviews])
# 3. AI 요약 (Pseudo code)
# response = openai.ChatCompletion.create(..., messages=[{"role": "user", "content": f"요약해줘: {review_text}"}])
summary = "AI 요약 결과 예시입니다."
serializer = ReviewSerializer(reviews, many=True)
return Response({
"page": page,
"summary": summary,
"reviews": serializer.data
})
# [코드 설명]
# 1. APIView를 사용하여 GET 요청을 처리
# 2. 슬라이싱을 통해 페이지네이션을 수동 구현하거나 DRF 기본 Pagination 클래스를 활용 가능
# 3. 합쳐진 리뷰 텍스트를 외부 AI API에 전달하여 요약본을 받아옴
# 4. 최종적으로 요약문(summary)과 원본 리뷰 리스트를 함께 반환Python 라이브러리(SDK)
# 설치 예시
# pip install openai
import openai
# API 키 설정 (보통 .env 파일에 보관)
openai.api_key = "YOUR_API_KEY"
def get_ai_summary(text):
response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "너는 리뷰 요약 전문가야."},
{"role": "user", "content": f"다음 리뷰들을 한 줄로 요약해줘: {text}"}
]
)
return response.choices[0].message.content
# [코드 설명]
# 1. 설치된 openai 라이브러리를 임포트합니다.
# 2. 발급받은 고유 API Key를 인증에 사용합니다. (보안을 위해 환경변수 처리가 필수입니다.)
# 3. 모델(gpt-4o-mini 등)을 선택하고 대화 형식으로 요약 요청을 보냅니다.
# 4. AI가 생성한 응답 내용(content)만 추출하여 반환합니다.구현
구현 로직 단계
- 데이터 조회
- PageNumberPagination 등을 이용해 해당 페이지의 리뷰 데이터들을 DB에서 가져옴
- 텍스트 추출
- 가져온 리뷰 객체들에서 요약할 텍스트 내용만 추출하여 하나의 긴 문자열로 합침
- AI 요약 요청
- OpenAI(GPT)나 Anthropic(Claude) 같은 LLM API에 합쳐진 텍스트를 보내 요약을 요청
- 결과 반환
- AI가 보내온 요약본과 해당 페이지의 리뷰 목록을 함께 Serializer를 통해 반환
- 데이터 조회
주요 고려 사항
- 비용 및 속도
- 매 요청마다 AI API를 호출하면 비용이 발생하고 응답 속도가 느려질 수 있음 (캐싱 고려 필요)
- 토큰 제한
- 한 페이지의 리뷰가 너무 많으면 AI 모델의 입력 토큰 제한을 넘을 수 있음
- 비동기 처리
- 응답 시간이 길어질 경우 Celery 같은 라이브러리를 사용해 비동기로 처리하는 것이 좋음
- 비용 및 속도
ai 연동
- 사용자
- 웹/앱에서 "리뷰 요약해줘" 버튼 클릭 (내 Django 서버로 요청)
- 내 서버 (DRF)
- DB에서 리뷰 데이터를 꺼내서 정리
- 외부 AI API
- 정리된 리뷰 데이터를 AI 업체 서버로 전송
- 내 서버 (DRF)
- AI가 보낸 요약 결과값을 받아서 내 DB에 저장하거나 사용자에게 전달
2026.01.08 ✅
욕설 1차 필터
비속어 처리
- better-profanity 라이브러리를 사용하여 1차 정제 후 2차로 재미나이한테 넘기기
from better_profanity import profanity
# better_profanity 모듈에서 profanity 객체를 가져옵니다.
korean_bad_words = ['시발', '꺼져', '개새끼', '병신']
# 필터링하고 싶은 한국어 비속어 리스트를 정의합니다 (실제로는 더 방대한 리스트가 필요합니다).
profanity.load_censor_words(korean_bad_words)
# 정의한 비속어 리스트를 라이브러리에 로드하여 감지할 단어로 설정합니다.
text = "이 게임 진짜 개새끼들이 운영하네."
# 필터링 테스트를 할 샘플 텍스트입니다.
censored_text = profanity.censor(text, '*')
# 텍스트 내의 비속어를 찾아 '*' 문자로 마스킹(치환)합니다.
print(censored_text)
# 결과: "이 게임 진짜 ****들이 운영하네." (설정한 단어가 마스킹되어 출력됩니다)- 예시에는 직접 입력했지만
- 실제로는 외부 파일(.txt) 등에서 불러오는 것으로 진행 할 예정
from better_profanity import profanity
import google.generativeai as genai
def filter_and_summarize(raw_review, api_key):
# 1. 한국어 비속어 리스트 정의
korean_bad_words = [
'시발', '씨발', '개새끼', '병신', '지랄', '존나',
'ㅅㅂ', 'ㅄ'
]
# 2. 라이브러리에 커스텀 단어 리스트 로드
profanity.load_censor_words(korean_bad_words)
# 3. 비속어 필터링 실행 (비속어는 '*'로 치환됨)
clean_review = profanity.censor(raw_review, '*')
# 4. Gemini 설정 및 연결
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-pro')
# 5. 정제된 데이터로 프롬프트 구성
prompt = f"""
다음은 게임 리뷰 데이터야. 비속어는 이미 필터링(* 표시) 되었어.
이 내용을 바탕으로 게임의 장점과 단점을 분석해서 3줄로 요약해줘.
[리뷰 내용]
{clean_review}
"""
# 6. 결과 생성
response = model.generate_content(prompt)
return clean_review, response.text
# --- 실행 예시 ---
# api_key = "YOUR_API_KEY"
# review = "이 게임 존나 재밌는데 운영이 병신같음. 시발 내 돈 돌려내."
# filtered_text, summary = filter_and_summarize(review, api_key)
# print(f"원문 정제: {filtered_text}")
# print(f"AI 요약: {summary}")from better_profanity import profanity
import google.generativeai as genai
def load_bad_words(file_path):
# 외부 텍스트 파일에서 욕설 리스트를 불러오는 헬퍼 함수입니다.
try:
with open(file_path, 'r', encoding='utf-8') as f:
bad_words = [line.strip() for line in f if line.strip()]
return bad_words
except FileNotFoundError:
print(f"오류: {file_path} 파일을 찾을 수 없습니다.")
return []
# 파일 열기 -> 줄 단위로 읽기 -> 공백 제거(strip) -> 리스트로 변환 과정을 거칩니다.
# 파일이 없을 경우를 대비해 예외 처리(try-except)를 추가했습니다.
def filter_and_summarize_from_file(raw_review, api_key, bad_word_file='fword_list.txt'):
# 파일 로드 및 필터링, 그리고 요약까지 수행하는 메인 함수입니다.
# 1. 파일에서 욕설 리스트 로드
korean_bad_words = load_bad_words(bad_word_file)
if not korean_bad_words:
return "욕설 리스트 로드 실패", ""
# 리스트가 비어있다면 로직을 수행하지 않고 중단합니다.
# 2. 라이브러리에 로드 (기존 영어 욕설 리스트 덮어쓰기)
profanity.load_censor_words(korean_bad_words)
# 메모리에 로드된 리스트를 better-profanity의 필터링 대상으로 설정합니다.
# 3. 필터링 실행
clean_review = profanity.censor(raw_review, '*')
# 리뷰 원문 내의 욕설을 찾아 별표(*)로 마스킹합니다.
# 4. Gemini에게 요약 요청
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-pro')
prompt = f"""
아래는 게임 리뷰 데이터야. 욕설은 '*'로 처리되었어.
이 내용을 바탕으로 핵심 내용을 3줄로 요약해줘.
[리뷰 본문]
{clean_review}
"""
response = model.generate_content(prompt)
return clean_review, response.text
# 정제된 텍스트와 AI가 생성한 요약문을 반환합니다.
# --- 사용 예시 ---
# 1. 'fword_list.txt' 파일을 파이썬 파일과 같은 폴더에 만들어주세요.
# 2. 그 파일 안에 욕설을 한 줄에 하나씩 적어넣으세요.
# filter_and_summarize_from_file("리뷰 내용...", "API_KEY")잘못된 감지 줄이기
- 완전 일치하는 단어만 필터링할지 아니면 포함된 단어도 필터링할지 결정하는 옵션
- 부분 일치
- exact_match=False
- 완전 일치
- exact_match=True
- 부분 일치
import re
import google.generativeai as genai
# 외부 파일에서 욕설 리스트 로드 (이전과 동일)
def load_bad_words(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
return [line.strip() for line in f if line.strip()]
except FileNotFoundError:
return []
def filter_text_advanced(text, bad_words, exact_match=False):
"""
text: 원본 텍스트
bad_words: 욕설 리스트
exact_match: True면 완전 일치만, False면 부분 일치도 필터링
"""
filtered_text = text
for word in bad_words:
if exact_match:
# [정규식 설명]
# (?<!\w): 단어 앞에 문자가 없어야 함 (공백이나 문장 시작)
# (?!\w): 단어 뒤에 문자가 없어야 함 (공백이나 문장 끝, 특수문자)
# re.escape(word): 욕설에 포함된 특수문자가 정규식으로 오인되지 않게 처리
pattern = r'(?<!\w)' + re.escape(word) + r'(?!\w)'
filtered_text = re.sub(pattern, '*' * len(word), filtered_text)
else:
# 단순 치환 (부분 일치 허용)
filtered_text = filtered_text.replace(word, '*' * len(word))
return filtered_text
def summarize_review(raw_review, api_key, bad_word_file='fword_list.txt', exact_match_mode=False):
# 1. 욕설 리스트 로드
korean_bad_words = load_bad_words(bad_word_file)
# 2. 선택한 모드(exact_match_mode)에 따라 필터링 수행
# better-profanity 대신 위에서 만든 커스텀 함수를 사용하여 정교하게 제어합니다.
clean_review = filter_text_advanced(raw_review, korean_bad_words, exact_match=exact_match_mode)
# 3. Gemini 요약 요청
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-pro')
prompt = f"""
아래 게임 리뷰를 읽고 3줄로 요약해줘.
'*'로 표시된 부분은 욕설이므로 문맥을 파악할 때 참고만 하고, 요약문에는 포함하지 마.
[리뷰 본문]
{clean_review}
"""
response = model.generate_content(prompt)
return clean_review, response.text
# --- 실행 예시 ---
# review_text = "이번 프로젝트의 시발점은 아주 좋았어. 근데 운영이 시발이야."
# 1. 부분 일치 모드 (기존 방식) -> '시발점'도 필터링 됨
# cleaned, summary = summarize_review(review_text, API_KEY, exact_match_mode=False)
# 결과: "이번 프로젝트의 **점은 아주 좋았어. 근데 운영이 **이야."
# 2. 완전 일치 모드 (개선된 방식) -> '시발점'은 살리고 '시발'만 필터링
# cleaned, summary = summarize_review(review_text, API_KEY, exact_match_mode=True)
# 결과: "이번 프로젝트의 시발점은 아주 좋았어. 근데 운영이 **이야."2026.01.09 ✅
serializer
from rest_framework import serializers
from apps.community.models.reviews import Review
class ReviewSerializer(serializers.ModelSerializer[Review]):
class Meta:
model = Review
fields= [
'content',
'rating',
]2026.01.10~11 ✅
ci 분석
기본
# GitHub Actions 탭에서 보일 이 워크플로우의 이름
name: Code Quality Checks & Tests
# develop, main 브랜치를 상대로 풀 리퀘스트가 생성될 때 CI가 실행(불필요한 브랜치에서 리소스 낭비를 막기 위함)
on:
pull_request:
branches:
- "main"
- "develop" jobs
jobs:
# 1. 린트 및 정적 분석 (Linting)
ci:
runs-on: ubuntu-latest
# GitHub에서 제공하는 최신 우분투 리눅스 가상 환경에서 실행합니다.
steps:
- name: Checkout code
uses: actions/checkout@v3
# 현재 저장소(Repository)의 코드를 이 가상 환경(Runner)으로 내려받습니다.
## 이 단계가 없으면 코드가 없어서 아무것도 할 수 없습니다.
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.12"
# 파이썬 3.12 환경을 설치하고 구성합니다.
- name: Install Poetry
run: |
curl -sSL https://install.python-poetry.org | python3 -
echo "${HOME}/.poetry/bin" >> $GITHUB_PATH
# 의존성 관리 도구인 Poetry를 설치하고, 터미널 어디서든 실행 가능하도록 경로(PATH)를 등록합니다.
- name: Cache Poetry dependencies
id: cache-venv
uses: actions/cache@v3
with:
# pyproject.toml과 poetry.lock 해시를 키로 사용하여 캐싱
path: ~/.cache/pypoetry/virtualenvs
key: python-3.12-poetry-${{ hashFiles('**/poetry.lock') }}
restore-keys: |
python-3.12-poetry-
# CI 속도 최적화의 핵심입니다.
## 'poetry.lock' 파일이 바뀌지 않았다면 이전에 저장해둔 라이브러리 폴더(path)를 그대로 가져와 재사용합니다.
- name: Install dependencies
if: steps.cache-venv.outputs.cache-hit != 'true'
run: poetry install --no-root
# 위 단계에서 캐시를 못 찾았을 때만(if 조건) 라이브러리를 설치합니다.
## '--no-root'는 현재 프로젝트 자체는 패키지로 설치하지 않겠다는 의미입니다(보통 개발 중엔 이렇게 함).
# isort 제거 -> Ruff가 대신 함
# Ruff 실행 (Lint + Import Sorting)
- name: Run Ruff (Lint & Import Sorting)
run: |
poetry run ruff check .
# Ruff는 최신 파이썬 린터로 속도가 매우 빠릅니다.
## 코드 스타일 오류, 사용하지 않는 변수, import 순서 등을 검사합니다.
# Black 실행 (Code Formatting Check)
- name: Run Black (Code Formatting)
run: |
poetry run black . --check
# Black은 코드 포매터입니다. '--check' 옵션은 코드를 수정하지 않고,
## 포맷에 맞지 않는 코드가 있는지만 검사하여 있다면 에러를 냅니다.
- name: Run Mypy (Type Checking)
run: poetry run mypy .
# 정적 타입 검사기입니다. 변수나 함수의 타입 힌트가 올바른지 검사하여
## 실행 전에 타입 관련 버그를 찾아냅니다.Tests
# 2. 테스트 (Tests)
test:
needs: ci
# 린트 검사가 통과해야 테스트를 실행함 (자원 절약)
## 만약 린트에서 실패하면 테스트는 실행조차 하지 않아 GitHub Actions 사용 시간(비용)을 아낍니다.
runs-on: ubuntu-latest
services:
# DB 설정을 프로젝트(.env)와 일치시킴
db:
image: postgres:15 # 버전 15로 변경
ports:
- 5432:5432
env:
POSTGRES_USER: oz_playtype_user
POSTGRES_PASSWORD: oz_playtype_pass
POSTGRES_DB: oz_playtype_db
TZ: Asia/Seoul
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
# 테스트를 위한 임시 PostgreSQL 데이터베이스 컨테이너를 실행합니다.
## 'options'의 health-cmd는 DB가 완전히 켜질 때까지 기다리도록 하는 설정입니다.
# Redis는 일단 유지
redis:
image: redis:latest
ports:
- 6379:6379
options: >-
--health-cmd "redis-cli ping"
--health-interval 5s
--health-timeout 3s
--health-retries 5
# 캐싱이나 큐 등에 사용되는 Redis 컨테이너를 실행합니다.
steps:
- name: Checkout code
uses: actions/checkout@v3
# 'test' Job은 'ci' Job과는 별개의 컴퓨터에서 실행되므로 코드를 다시 받아와야 합니다.
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.12"
- name: Install Poetry
run: |
curl -sSL https://install.python-poetry.org | python3 -
echo "${HOME}/.poetry/bin" >> $GITHUB_PATH
- name: Cache Poetry dependencies
id: cache-venv
uses: actions/cache@v3
with:
path: ~/.cache/pypoetry/virtualenvs
key: python-3.12-poetry-${{ hashFiles('**/poetry.lock') }}
restore-keys: |
python-3.12-poetry-
# ci Job과 동일하게 캐시를 활용하여 테스트 환경 셋업 속도를 높입니다.
- name: Install dependencies
if: steps.cache-venv.outputs.cache-hit != 'true'
run: poetry install --no-root
# settings.py가 루트의 .env를 바라보도록 설정했으므로 루트에 생성해야 합니다.
- name: Create .env file
run: |
echo "${{ secrets.DJANGO_ENVS }}" > .env
## GitHub 저장소의 Settings -> Secrets에 저장해둔 값(DJANGO_ENVS)을 불러와서
## 테스트 실행 시 필요한 .env 파일을 즉석에서 생성합니다.
- name: Run Django Migration
run: |
poetry run python manage.py migrate
# 위에서 띄운 서비스 컨테이너(Postgres)에 테이블을 생성합니다.
# Coverage 패키지가 필요하므로 없는 경우를 대비해 설치 확인
# (pyproject.toml에 coverage가 없다면 추가해야 합니다)
- name: Run Tests & Coverage
run: |
# 1. 전체 테스트 병렬 실행 및 커버리지 수집
# (multiprocessing 등 복잡한 옵션은 초기엔 에러가 날 수 있어 단순화했습니다)
poetry run coverage run --source='.' manage.py test
# Django 테스트를 실행하면서 코드 커버리지(테스트가 코드를 얼마나 건드렸는지) 데이터를 수집합니다.
# 2. 결과 리포트 출력
echo "======================="
echo "📊 Total Coverage Report:"
poetry run coverage report -m
# 수집된 데이터를 바탕으로 터미널에 요약 보고서를 출력합니다.
# 3. (선택 사항) apps 폴더 내부 앱별 커버리지 출력 로직은 유지
apps=$(find apps -maxdepth 1 -mindepth 1 -type d ! -name "__pycache__" -exec basename {} \;)
# 'apps' 폴더 아래에 있는 디렉토리 이름들을 찾아냅니다 (Django App들).
for app_name in $apps; do
app_path="apps/$app_name"
# __init__.py가 있는 폴더만 파이썬 패키지로 간주
if [ -f "$app_path/__init__.py" ]; then
echo "🔍 Checking coverage for apps.$app_name..."
# 해당 앱에 대한 리포트만 필터링해서 출력
poetry run coverage report -m --include="$app_path/*" || echo " - No executed code found in $app_name"
echo ""
fi
done
# 전체 리포트뿐만 아니라, 개발자가 만든 각 앱(App)별로 테스트 커버리지가 몇 퍼센트인지
## 따로 필터링해서 보여주는 쉘 스크립트 로직입니다.
안녕하세요.