논문 출처: https://doi.org/10.1145/3477495.3531973
SIGIR 2022에 발표된 논문이다.
내가 관심있는 주제인 설명 가능성과 공정성을 모두 다루는 논문이라 흥미롭게 읽었다.
구체적으로는, 추천 시스템에서의 공정성을 설명할 수 있는 기법을 연구한 논문이다.
Facebook Faculty Research Award의 지원을 받은 연구라고 한다.
저자가 Microsoft Research의 Research Talk에서 한 아래 강연을 참고하는 것도 논문을 이해하는 데 도움이 되었다.
https://www.youtube.com/watch?v=GArXoRECXFU
0. 추천시스템에서 설명가능성과 공정성이 중요한 이유
이 내용은 논문이 아닌 저자의 유튜브 영상에서 가져온 내용이다.
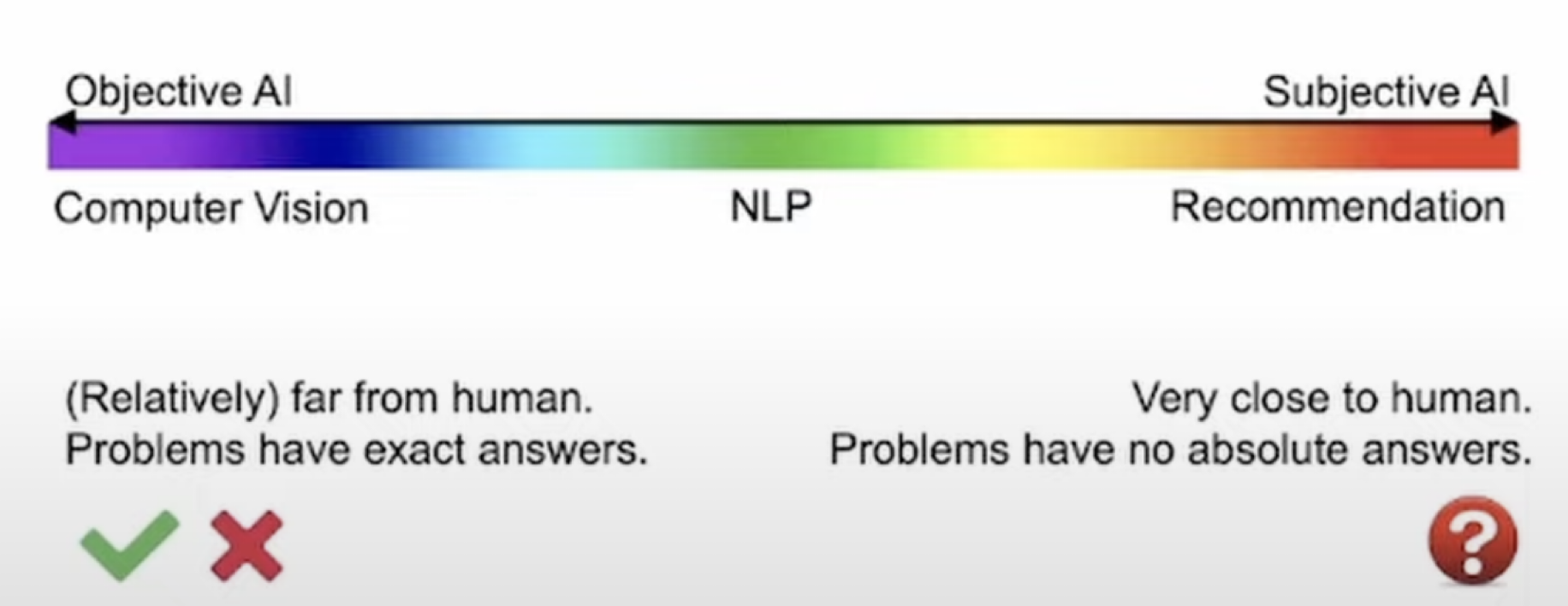
(이미지 출처: https://www.youtube.com/watch?v=GArXoRECXFU)
추천 시스템은 기본적으로 인간에게 가까운 주관적인 AI에 속한다고 저자는 말한다.
예를 들어, 비전 분야에서 object detection과 같은 task에서는, 이미지 내에 object가 어디에 존재하는지와 관련하여 객관적인 정답이 존재한다.
이와 다르게 추천 시스템에서는 어떻게 추천하는 게 절대적인 정답인지와 관련하여 기준이 존재하지 않는다.
사용자의 피드백 (클릭, 뷰 등)을 통해 추천 성능을 부분적으로 평가할 수 있을 뿐이다.
추천 시스템은 이처럼 주관적이기 때문에 explainability, fairness, controllability 같은 것들이 더욱 중요해진다.
추천에 대한 이유를 설명하지 않으면 추천 결과를 받아들이기 어렵거나 무례하게 느껴질 수 있고,
추천 결과에 대한 옳고 그름을 유저가 직관적으로 판단할 수 없기 때문에 유저는 추천 시스템 개발자에 비해 상대적으로 취약한 위치에 있으며,
추천 결과를 수동적으로 받아들여야 하기 때문에 추천 시스템에 대한 통제력이 전혀 없는 경우가 대부분이기 때문이다.
1. Introduction
RQ: What are the sources that result in model disparities in recommendation?
RQ: 추천에서 모델의 불균형(격차)를 야기하는 요인은 무엇인가?
위의 질문에 대한 답을 찾음으로써, 저자들은 아래와 같은 효과를 기대할 수 있다고 한다.
- 개발자들이 추천 시스템의 내부적인 매커니즘을 한 층 깊게 이해할 수 있다.
- 의사결정자들이 모델의 공정성을 향상시키기 위한 방법을 찾기 위한 인사이트를 제공한다.
그러나 이 문제를 해결하는 것은 챌린징한 일인데, 특히 대규모의 feature를 인풋으로 받는 large scale, deep, black-box 모델의 경우 더욱 그렇다.
저자들은 이 문제를 해결하기 위해 Counterfactual Explainable Fairness (CEF) framework를 제안한다.
해당 프레임워크는 item 노출 불균형과 관련하여 feature-based 설명을 생성한다.
본 논문에서는 feature-based 추천 시스템, 그리고 item 노출 불균형에 해당 프레임워크를 적용하였지만, 다른 추천 환경에서도 적용이 가능하다고 한다.
여기서 counterfactual explanation이란, 다음과 같은 가정을 기반으로 한 설명을 의미한다.
만약 이 item이 특정한 요소(들)에 있어서 살짝 더 나빴다면, 이 item은 추천되지 않았을 것이다.
즉, 기존의 결과와 반대되는 가정을 통해 중요하게 작용한 요소를 찾아내는 것이다.
2. Related Work
Explainable Recommendation
추천 시스템을 설명하려는 시도를 통해 추천 시스템의 투명성을 강화하고, 유저의 만족도를 높일 수 있으며, 궁극적으로는 추천 시스템에 대한 신뢰도를 향상할 수 있다.
기존에 추천시스템에 대한 설명 가능성을 증명하기 위해 아래와 같은 시도들이 있었다.
- latent factor alignment with explicit meaning
- development of neural algorithms to explain neural models
- counterfactual reasoning
Fairness in Recommendation
기존의 연구들은 성별과 인종, item의 인기도, 유저의 활동성 등으로 인해 추천 시스템에서 발생할 수 있는 편향과 불공정을 발견했다.
공정한 추천 시스템을 위한 다양한 방법론도 제시되어왔는데, 아래와 같이 그 시도를 나눠볼 수 있다.
- pre-processing: 데이터 소스 내의 편향을 최소화
- in-processing: 목적 함수에 공정성의 의미를 인코딩
- post-processing: 결과의 표현된 형태를 수정
Fairness Explanation
ML 모델의 불공정성 (불균형)을 설명하려는 시도도 있었는데, 한 예로는 Shapley value paradigm (Begley et al.)이 있다.
해당 방법론에서는 모델의 불공정성에 대한 각 feature의 기여도를 측정하여 설명을 생성한다.
그러나 이 방법을 추천 시스템에 적용하는 데에는 무리가 있다.
- 추천 시스템에서는 유저/item feature의 개수가 매우 크기 때문에 해당 방법론을 적용하기 어려움
- 공정성-성능 트레이드오프 (fairness-utility trade-off)를 설명하지 못한다. 즉, fairness만 측정하기 때문에 그로 인한 성능의 감소는 측정하지 못한다.
저자들은 본 논문에서 주장하는 CEF 프레임워크가 위 문제들을 해결할 수 있다고 한다.
3. Explainable Fairness
여기서 저자들은 CEF의 방법론을 설명한다.
Feature Generation
먼저 raw 리뷰 데이터를 이용해 feature를 생성한다.
리뷰 데이터로부터 아래와 같은 quadruple의 set을 먼저 생성한다.
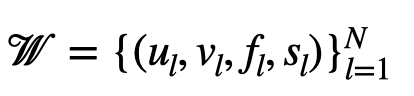
이 때, 각 element는 아래와 같은 의미를 갖는다.

즉, 유저 A가 "청바지 사이즈가 생각보다 타이트한데, 색깔은 엄청 예뻐요."라는 리뷰를 남긴 경우,
(유저 A, 청바지, 색상, +1)
(유저 A, 청바지, 사이즈, -1)
과 같은 두 개의 원소가 W에 추가된다.
W를 이용하여 아래의 식을 통해, 최종적으로 user-feature attention matrix A와, item-feature quality matrix B를 만들 수 있다.

A, B의 원소들은 각각 다음과 같은 의미를 갖게 된다.

Feature-aware Recommender Systems
유저-item의 랭킹 스코어를 예측하는 랭킹 모델을 다음과 같이 정의한다.
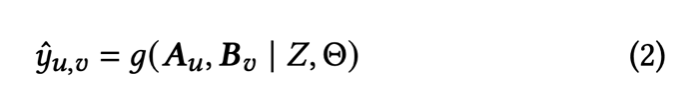
여기서 theta = model parameter, Z = all other auxiliary information에 해당한다.
랭킹 모델 g의 구조는 다층 뉴럴 네트워크이다.
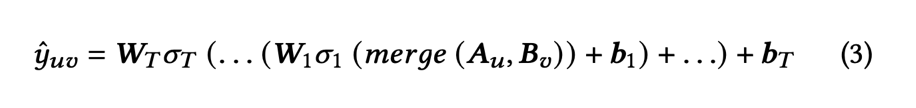
여기서 sigma = non-linear activation function, merge = user-feature & item-feature vectors를 merge하는 함수이다.
저자들은 merge operator를 다음과 같이 두 가지로 정의하여 모두 실험에 사용한다.

여기서 task는 아래와 같이 정의된다.

즉, {유저, 아이템, 유저-아이템 관계, 유저-피처 attention 행렬, 아이템-피처 quality 행렬, 랭킹 함수} 가 주어졌을 때, 블랙박스 추천 모델 g에 대해 추천 시스템의 불균형과 관련하여 feature 기반의 설명을 생성하는 것이다.
Fairness and Disparity
모델 g를 이용해 추천 결과 Rk를 얻었다고 하자. (모든 유저의 top-K 추천 리스트를 포함)
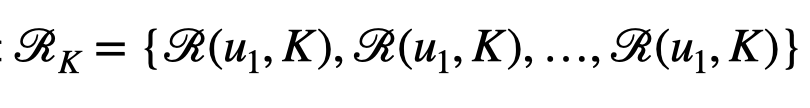
아이템을 아래와 같은 두 개의 그룹으로 나눈다. 이 때 추천 리스트에 등장하는 횟수를 기준으로 나눈다.
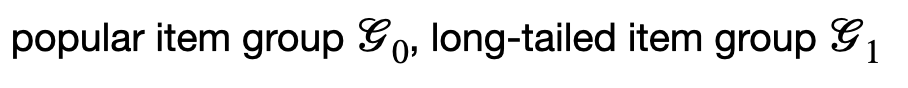
그리고 demographic parity, exack-K fairness라는 popularity bias와 관련된 두 개의 유명한 algorithmic 공정성 정의를 사용한다.

불균형 (disparity)는 위의 두 정의의 식에서 양변의 뺄셈으로 다음과 같이 간단하게 정의한다.

Counterfactual Reasoning
그 후, 각 유저-피처 벡터 A:f에 대해, 작은 개입을 통해 새로운 행렬 Acf를 얻는다.
마찬가지로, 각 아이템-피처 벡터 B:f에 대해 작은 개입을 통해 새로운 행렬 Bcf를 얻는다.
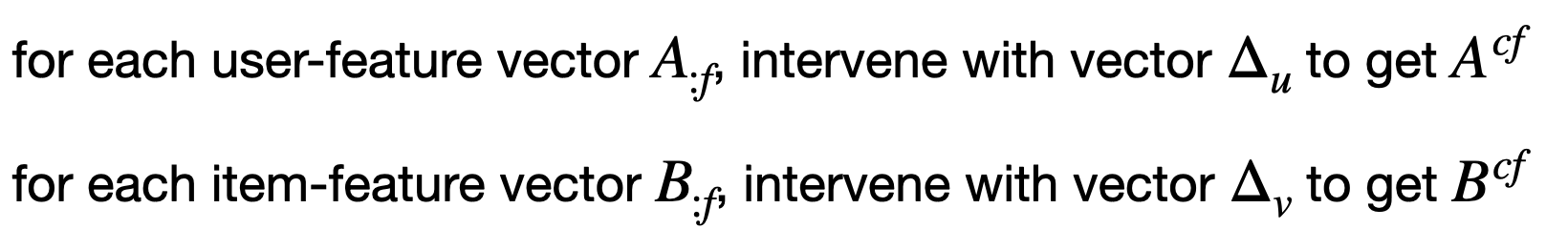
여기서 목표는, 유저/아이템 피처에 최소한의 개입을 통해 불공정성을 가장 크게 감소시킬 수 있는 방법을 찾는 것이다.
주어진 피처에 대한 목적 함수는 아래와 같이 정의될 수 있다.
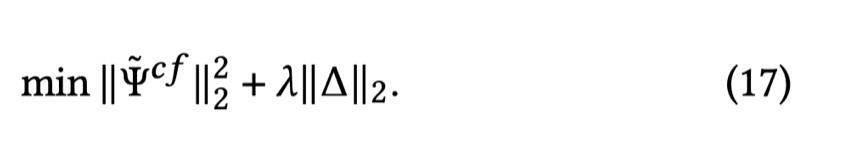
이 식에서 첫 번째 항은 기존에 정의된 불공정성에 최대의 감소를 만들기 위한 항이다.
두 번째 항 (perturbation constraint)은 기존 input과 대응되는 counterfactual 사이의 edit distance를 표현한다.
여기서 람다는 hyper-parameter이다.
Generate Feature-based Explanations
각 feature에 대해 위의 최적화 문제를 풀고 나면, 델타의 최솟값과 이에 대응하는 추천 결과를 얻을 수 있다.
아래와 같이 proximity, validity를 정의하여 최종적으로 explainability score (설명가능성 점수)를 얻는다.
- Proximity: average edit distance between original input and corresponding counterfactual
- Validity: change of fairness caused by the feature’s perturbation

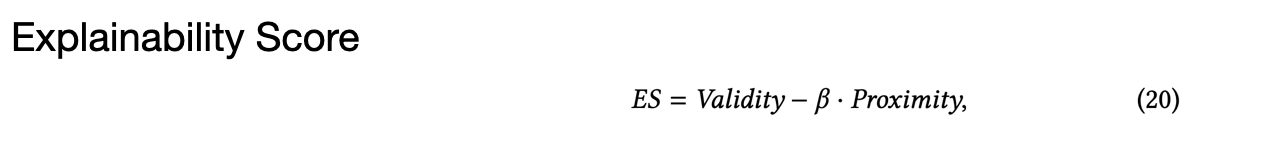
위의 explainability score은 특정 feature가 최소한의 개입으로 모델 g의 불공정성을 감소시킬 수 있는 능력을 계산하여, 각 feature의 랭킹을 산출할 수 있다.
여기서 중요한 점은 이 식에 공정성 뿐만 아니라 성능에 대한 지표도 반영이 된다는 점이다.
feature의 기존 값은 모델 g가 학습한 최적의 추천 성능을 반영하기 때문에, proximity가 높다는 것 (기존 결과에서 더 멀어졌다는 것)은 성능이 더 낮아졌다는 것을 의미하기 때문이다.
4. Experiments
CEF의 효과성을 증명하기 위해 저자들은 다음과 같이 실험을 수행한다.
Datasets
사용한 데이터셋은 다음과 같다. 해당 플랫폼의 리뷰 데이터를 사용하였고, 데이터의 크기, sparsity, 적용 시나리오 등을 다양하게 보기 위해 다음과 같이 선정하였다고 한다.
- Yelp dataset
- Amazon dataset: CDs & Vinyl, Electronics
각 유저의 최근 5개 interacted item과, 100개의 랜덤 샘플링한 음성 샘플을 테스트 데이터로 사용하였다.
훈련 데이터셋의 마지막 item은 검증 데이터로 사용하였다.
popular group과 long-tail group (G0, G1)을 구분하는 기준으로는, interaction 수를 기준으로 top 20%를 G0, 나머지를 G1으로 정의하였다.
Black-box Recommender System
g로는 아래와 같은 구조의 간단한 딥 뉴럴 네트워크를 사용하였다.

여기서 fusion layer는 위에서 정의한 두 개의 merge function 중 어떤 것을 사용하느냐에 따라서 달라진다.
SGD optimizer와 learning rate=0.01을 사용하였다.
Baselines
추천 시스템에서 공정성을 설명하는 데 사용하는 baseline이 기존에 존재하지 않았기 때문에, 저자들은 아래와 같은 방법론을 baseline으로 채택하였다.
- Random: 랜덤하게 복수의 feature를 선택
- Popularity: 행렬에 나타나는 빈도를 기준으로 top feature들을 선택
- EFM: 해당 논문에서 정의됨. 공정성은 고려하지 않고 추천 성능만 설명함
- Feature-based Explanation by Shapley Values (SV): 해당 논문에서 정의됨. 여기서는 100개의 feature coalition을 랜덤 샘플링하여 각 feature에 대해 계산을 수행
Evaluation Methods and Metrics
XAI 분야에서 널리 사용되는 방법인 erasure-based evaluation criterion을 사용하였다.
이 평가 방법에서는, 특정 설명에서 "가장 중요하다"고 나온 feature들을 제거했을 때 얼마나 성능이 감소하는지를 측정한다.
본 논문에서는 성능 감소의 정도와 더불어, 공정성이 증가하는 정도를 함께 측정하였다.
즉, "가장 중요하다"고 나온 feature들을 제거한 후, pre-train된 모델 g에 지워진 matrix들을 input으로 넣어 새로운 추천 결과를 생성하고 성능을 측정한다.
추천의 성능을 평가하기 위해서는 F1 score과 NDCG를 사용하였고,
공정성을 평가하기 위해서는 long-tail rate와 KL-divergence를 사용하였다.
long-tail rate는 단순하게 아래와 같이 정의되었다.
[추천 결과에서 long-tailed 아이템의 개수] / [추천 결과에서 총 item 개수]
Experimental Results
실험 결과를 fairness-utility trade-off 그래프로 나타냈을 때 아래와 같았다.
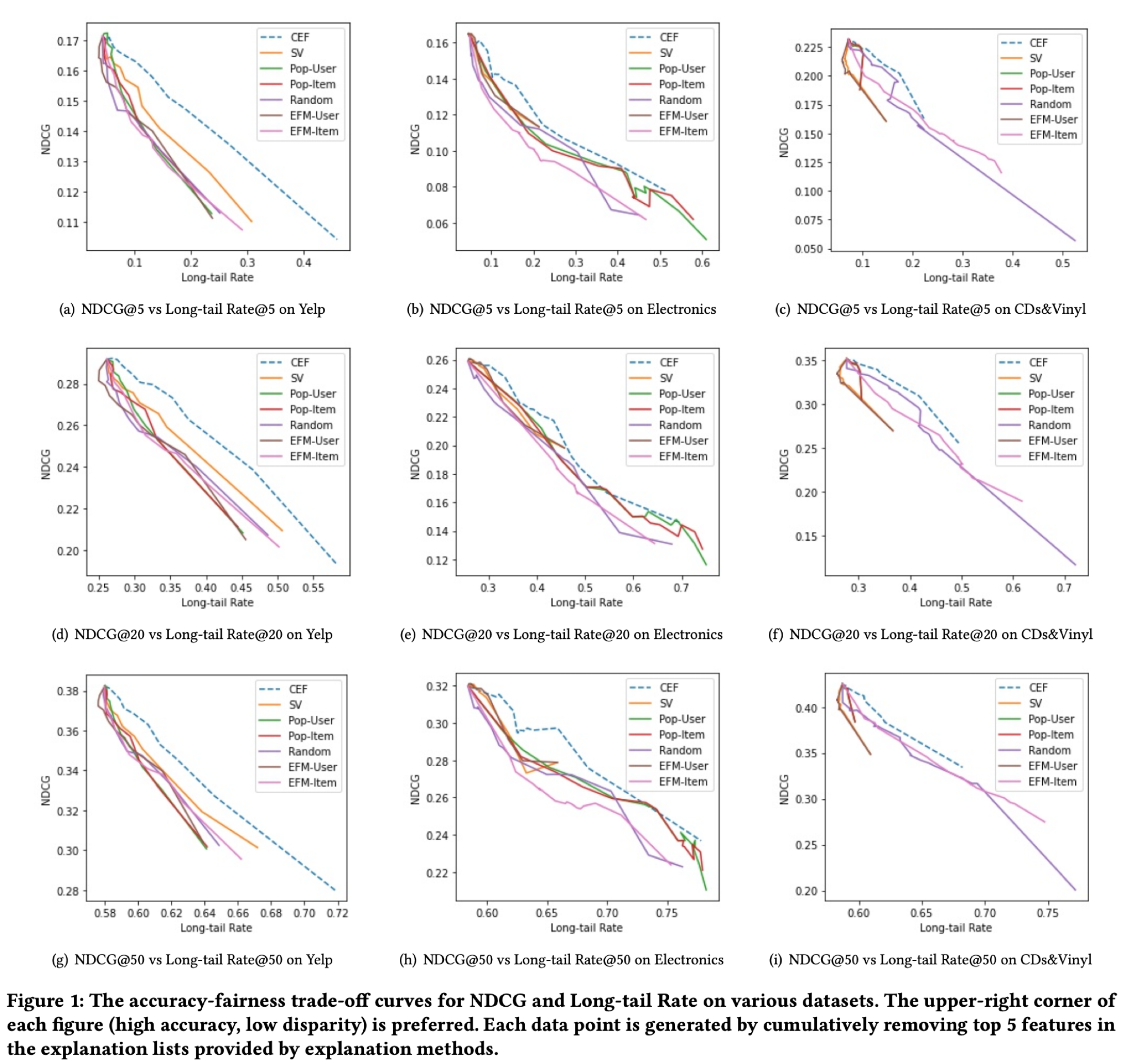
해당 그래프에서는 x축에 공정성, y축에 추천 성능을 그려 공정성과 성능 간의 trade-off를 확인할 수 있다.
그래프 상에서 오른쪽 위가 추천 성능이 높으면서 공정성이 높은 것을 의미하므로, 우리가 원하는 결과에 가깝다고 할 수 있다.
거의 모든 경우에, 논문에서 제안된 CEF (파란 점선)가 가장 좋은 trade-off를 보였다. (오른쪽 위에 가장 가까움)
자세한 수치는 아래와 같다.
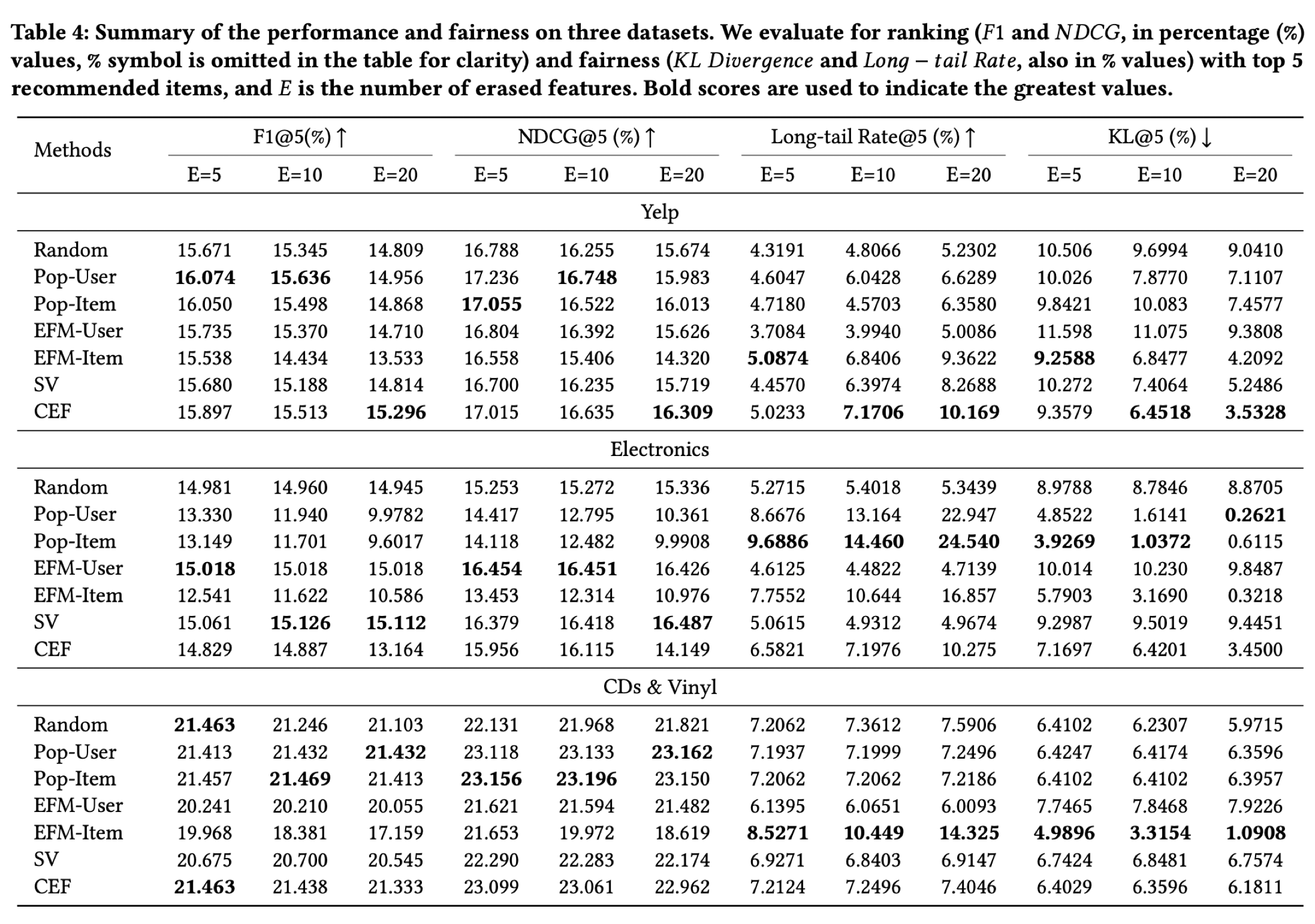
해당 결과를 통해 저자들은 세 가지 인사이트를 뽑아낸다.
1. 모든 방법론은 공정성을 향상시켰으며, 더 많은 feature를 지울수록 불균형이 더 많이 해소되었다.
이는 feature를 지울수록 인기 많은 아이템과 long-tail 아이템 간의 표현 격차 (representation gap)가 줄어들기 때문이라고 직관적으로 설명할 수 있다.
그러나, 불균형이 해소됨과 동시에 추천 성능 또한 감소하였다. 즉, fairness-utility trade-off가 발생하였다.
2. 인기 많은 feature를 선택하는 게 랜덤 선택보다도 더 안좋은 성능을 보일 수 있다.
설명을 위해 인기가 많은 feature를 선택하는 게 직관적인 것처럼 보일 수 있으나, random selection보다도 안좋은 성능을 보이는 경우가 많았는데, 이는 인기 많은 feature가 그만큼 성능에도 민감하기 때문이다.
3. SV의 성능이 CEF보다 훨씬 안좋았다.
기존에 fairness explanation에 대한 방법론으로 제안된 SV는 성능을 고려하지 못하고 공정성만을 측정하기 때문에, 표에서 보는 바와 같이 둘 모두 고려하는 CEF보다 성능이 좋지 못했다.
Ablation Studies
저자들은 조건을 바꾸어 추가적으로 실험을 수행했는데, 목적 함수의 델타를 바꾸어보았다.
기존의 결과들은 모두 u (유저), v (아이템)에 대한 델타 값을 모두 사용하였는데, 둘 중 하나만 사용했을 때 어떤 결과가 나왔는지 실험해본 것이다.

결과 중 하나를 그리면 아래와 같다.
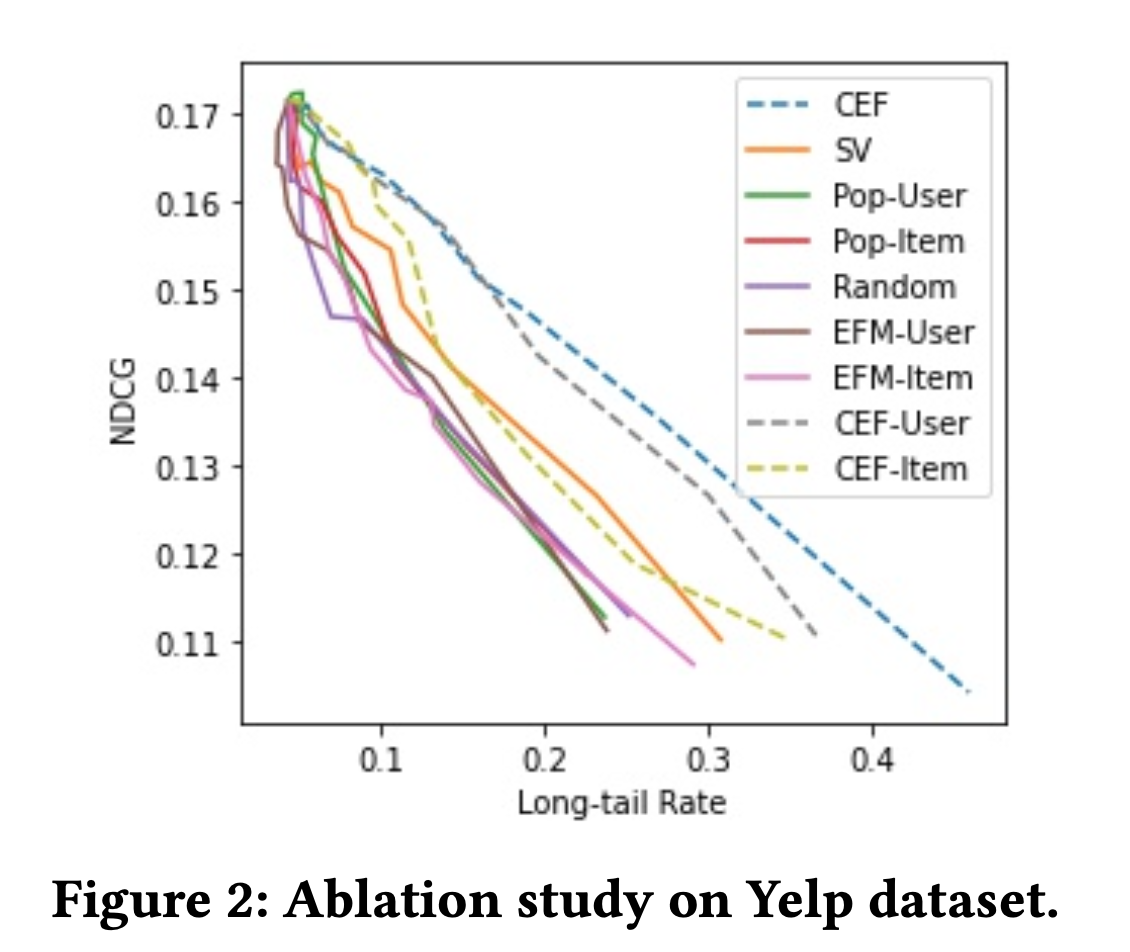
그래프에서 볼 수 있듯이, 둘 모두를 사용했을 때 (파란 점선) 보다 두루 중 하나를 사용했을 때 (회색 점선, 연두색 점선) trade-off 결과가 조금 더 안좋아졌으나, 여전히 다른 baseline들과 비교했을 때 결과가 더 좋음을 확인할 수 있다.
해당 논문을 읽으면서 수학적인 부분을 이해하는 데 약간의 장벽이 있었으나, 전반적인 컨셉을 이해하는 데 큰 무리가 없었던 것 같다. 그만큼 직관적으로 공정성에 대한 설명 가능성을 탐구한 연구라는 생각이 든다.
개인적으로 이러한 연구가 더 활발히 진행되고, 산업계에서도 AI의 공정성과 설명성의 중요성에 대한 의식이 높아지길 바란다.
기업의 목표는 어디까지나 이윤 창출이기 때문에, 이런 변화가 일어나기 위해서는 국가와 법의 빠른 변화가 필수적이라고 생각한다.
국가 차원의 더 빠른 변화를 위해서 사용자들도 AI 윤리에 관심을 갖고 목소리를 낼 수 있다면 좋을 것 같다.
