[DL] Transformer
1.[DL] Attention is all you need(0) : references

아래 reference들을 주로 참고하였습니다. 추천하는 방법은, 본 포스팅 또는 Jay Alammar의 블로그를 통해 내용 숙지를 한 후에, paper와 네 번째 링크인 havard edu의 코드를 함께 보면 좋을 것 같습니다. 추가로 참고하실 사항은, 제 생각과
2023년 7월 19일
2.[DL] Attention is all you need(1) : prior knowledge
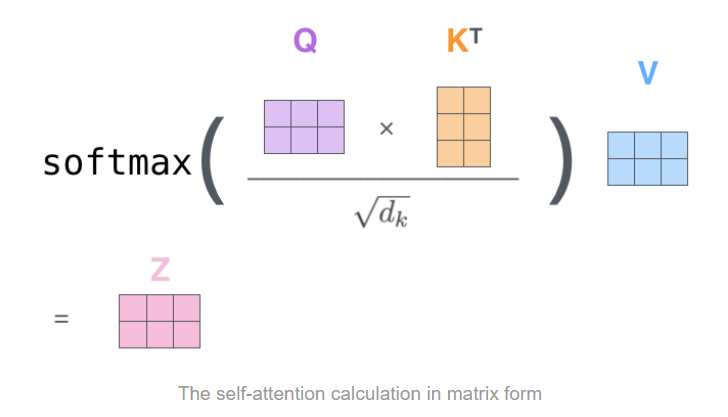
Attention은 입력 sequence에서 특정 위치에 얼마나 집중해야 하는지를 나타낸다. 이 개념은 해당 논문에서 제시한 모델 'Transformer'에서 처음 사용된 것은 아니지만, 기존엔 Convolution 등 특정 블록에 얹어지는 정도로 사용했다면 이를 Ma
2023년 7월 19일
3.[DL] Attention is all you need(2) : paper review
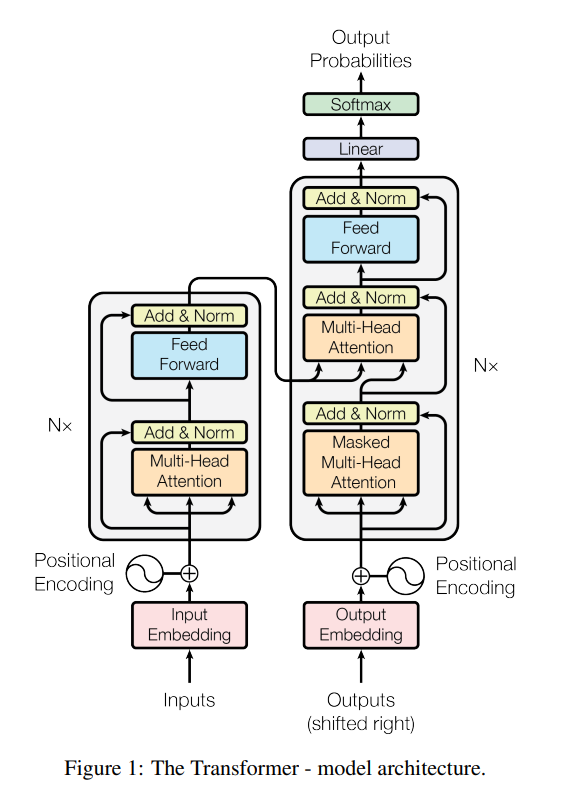
0. Abstract - 기존에는 sequence transduction model로 복잡한 RNN이나 인코더/디코더를 포함한 CNN이 주로 사용되었음. - Recurrence와 convolution없이 Attention 메커니즘만을 사용하여 Transforme
2023년 7월 19일