2. "Attention Is All You Need"
논문 요약
용어는 원문 영어 그대로 사용하였고, 필요한 설명들은 보충하는 식으로 의역하였습니다.
0. Abstract
- 기존에는 sequence transduction model로 복잡한 RNN이나 인코더/디코더를 포함한 CNN이 주로 사용되었음.
- Recurrence와 convolution없이 Attention 메커니즘만을 사용하여 Transformer라는 이름의 간단한 network를 제안함.
- 적은 training cost로 최고 성능을 갱신함.
1. Introduction
- RNN, LSTM, GRN 등 간단히 소개
- 기존엔 attention mechanism이 접속사처럼 간단한 정도로 사용되었음.
2. Background
- sequential computation을 줄이려는 기존 시도들(Neural GPU, ByteNet, ConvS2S - 모두 conv를 basic building block으로 사용)
- 서로 다른 위치에서 임의의 두 변수를 연산하는 것은 ConvS2S에서 linear, ByteNet에서 Logarithmical
- Transformer에서는 연산 횟수를 상수로 줄였음.
- matrix dimension을 hyper parameter로 정하였고, matrix multiplication으로 attention 계산이 끝남.
- 다른 모델에 기반하지 않고, 오로지 attention만을 사용했다는 것을 novelty로 굉장히 강조하고 있음.
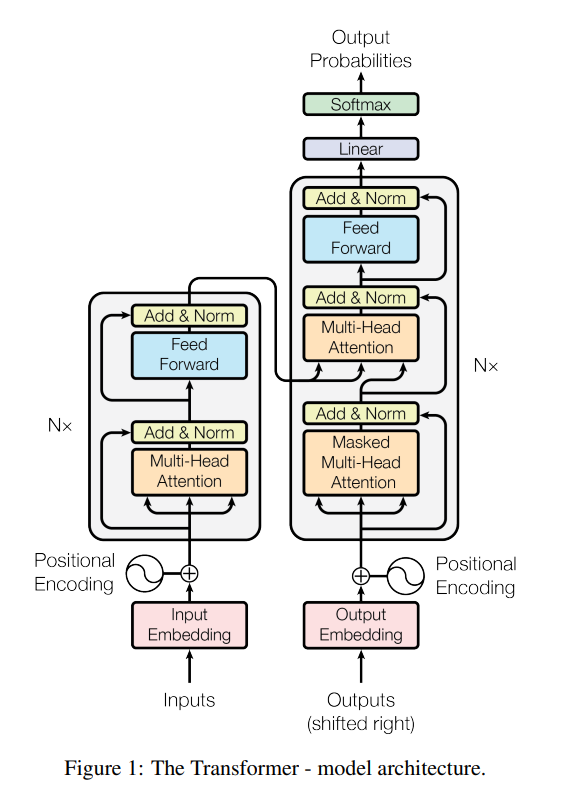
3. Model Architecture
(여기부터는 논문에 나오는 각 표기가 무엇인지 잘 따라가지 않으면 헷갈리기 쉽습니다.)
3.1 Encoder-Decoder Stacks
-
인코더-디코더 구조를 따르며, stacked self-attention과 point-wise, fully connected layer를 쌓은 형태.
-
인코더는 6개의 동일한 structure의 layer를 겹쳐 놓았다.(weight를 공유하지는 않는다.)
- 각 layer는 multi-head self-attention과 position-wise fully connected feed-forward 두 sub-layers가 residual connection으로 연결되고, 뒤이어 layer normalization을 하는 구조이다. 수식으로 나타내면 LayerNorm(x + SubLayer(x)).
- residual connection을 위해 embedding을 하는 sub-layer는 ouptut dimension을 512로 한다. input과 output의 dimension이 맞아야 연산이 가능하기 때문.
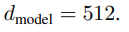
-
디코더도 6개의 동일한 layer로 구성되어 있는데, 두 sub layer 사이에 encoder-decoder attention layer가 추가된다
- 추가된 layer에서는 encoder stack의 output을 사용해 attention을 수행한다.
- output은 순차적으로 출력되기 때문에 다음 output을 미리 알 수는 없다. 때문에 self-attention layer에서는 다음 순서의 vector를 사용하지 않는다. (i번째 단어에서는 attention mechanism을 0부터 i번째 단어까지만 적용한다.)
- 이를 보완하기 위해 encoder-decoder layer가 추가되었다고 볼 수 있습니다.
3.2 Attention
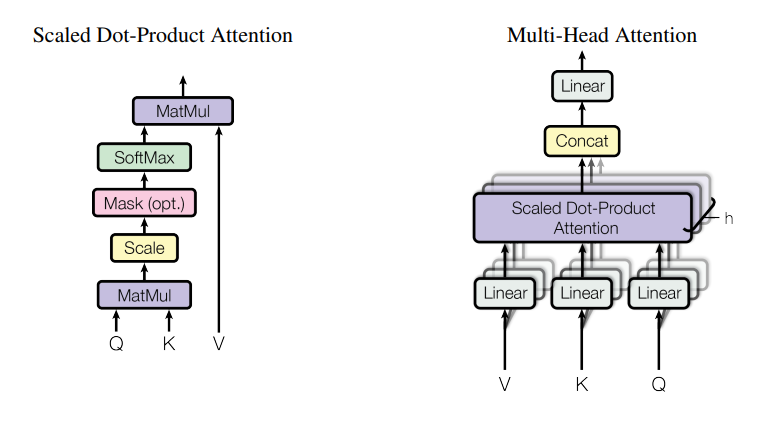
- left is Scaled Dot-Product Attention
- Mask가 optional한 것은 decoder에만 필요하기 때문인 듯하다.
- Right is Multi-head Attention (head means one scaled dot-product attention)
3.2.1 Scaled Dot-Product Attention
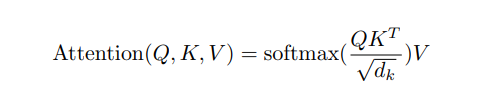
- query, key, value 벡터들의 sequence를 행렬로 표현하여 한 번에 계산한다.
- attention function은 크게 둘로 나뉘는데, additive attention과 dot-product attention이 있다.
- 둘은 이론상 비슷한 복잡도를 갖지만 행렬곱 연산의 최적화로 practically 후자가 뛰어나다.
- 본 논문에서는 후자인 dot-product attention을 사용하였는데, scaling factor d를 추가하여 scaled dot-product attention이라고 한다.
- scaling factor d를 통해 scale down을 하는 것은 softmax 함수 때문이다.
- softmax 함수를 생각해보면, scale이 커질수록 gradient는 작아지기 때문에 vanishing gradient와 같은 문제가 발생할 수 있다. 아래 그림을 참고하자.
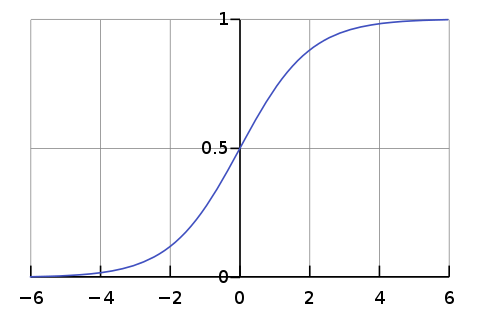 ref. wikipedia (sigmoid)
ref. wikipedia (sigmoid) - additive에 비해 dot-product를 사용하면 결과의 magnitude가 크게 커지므로 counter-action으로써 d를 사용했다고 한다.
- softmax 함수를 생각해보면, scale이 커질수록 gradient는 작아지기 때문에 vanishing gradient와 같은 문제가 발생할 수 있다. 아래 그림을 참고하자.
3.2.2 Multi-Head Attention
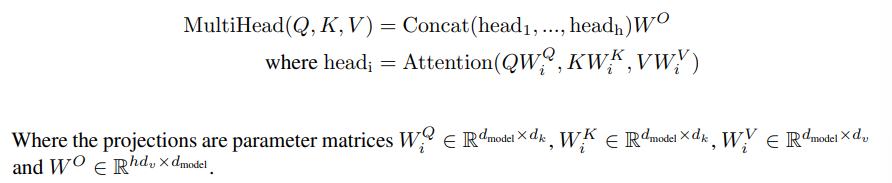
- d_model dimension(=512)으로 single attention을 하는 것보다, 각각 d_k, d_k, d_v dimension(=64)으로 h(=8)번을 pararell 하게 계산하는 것이 성능이 좋았다.
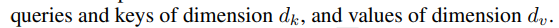 (d_k와 d_v는 논문에서는 같은 값을 사용하지만 다를 수도 있다고 한다.)
(d_k와 d_v는 논문에서는 같은 값을 사용하지만 다를 수도 있다고 한다.)- 이렇게 할 경우 output value는 하나의 d_model dimension이 아닌 h개의 d_v dimension으로 나오며, 마지막에 하나로 concate된다.
- h는 하이퍼파라미터로, head(self-attention)의 개수이고, 본 논문에서는 8을 사용하였다. d_k와 d_v에 8을 곱하면 d_model이 되므로 total computational cost를 맞추기 위해 8을 사용하였다고 한다.
- Multi-head attention을 통해 모델은 다양한 representation subspaces의 다른 위치에 접근할 수 있다. (모델의 표현력과 일반화 성능이 올라간다고 해석할 수 있을 것 같습니다.)
3.2.3 Applications of Attention in our Model
트랜스포머는 attention을 세 가지 방식으로 사용하였다.
- "encoder-decoder attention layer"에서, queries는 이전 decoder layer, keys/values는 encoder로부터 가져온다. (기존 seq2seq encoder-decoder attention 모델의 방식을 그대로 차용함)
- decoder에서 앞뒤 문맥을 모두 고려할 수 있도록 도와준다.
- encoder의 self-attention layers에서, 각 query/key/value vector들은 같은 곳(self=encoder)에서, 구체적으로는 이전 layer의 output에서 가져온다.
- 직전 layer일 필요는 없으며, 이전 layer 중 어떤 곳이든 참조할 수 있다. 첫 번째 layer의 경우 input embedding을 사용한다.
- decoder의 self-attention layer의 경우도 마찬가지인데, encoder와 다른 점은
- Auto-regressive(AR) property를 보존하기 위해 잘못된 연결에 대해 -inf로 마스킹하였다. (inf는 softmax에 의해 0이 되기 때문입니다. + 마스킹 위치는 현재 단어 이후의 position이라고 생각하면 될 것 같습니다. AR property에 대해서는 wikipedia를 권합니다.)
3.3 Position-wise Feed-Forward Network
- attention sub-layer는 fully
connected feed-forward network를 포함하는데, 각각의 position(단어)에 동일하게 적용된다는 점에서 Position-wise 하다. - 두 개의 linear transformation에 ReLU 활성화 함수를 적용하여 다음과 같은 수식으로 표현된다.
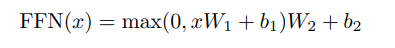
- kernel size가 1인 두 번의 convolution으로도 이해할 수 있다.(in/output dimension은 d_model(=512)이고, inner-layer dimmension은 d_ff(2048))
3.4 Embeddings and Softmax
- 다른 sequence transduction 모델들과 비슷하게, in/output token들을 d_model 차원의 vector로 바꾸는 learned embedding(학습을 통해 embedding 값이 변경됨)을 사용하였다.
- decoder output을 다음 token의 확률로 사용하기 위해 learned linear transformation과 softmax를 사용하였다.
3.5 Positional Encoding
- transformer 모델은 recurrence와 convolution이 없기 때문에 order에 대한 정보가 추가로 필요하다.
- 따라서 encoder와 decoder stacks의 가장 밑단에 positional embedding을 input에 추가해주었다.
- 서로 다른 주파수의 sine과 cosine 함수를 사용하였다.
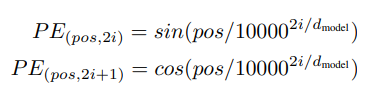 (pos는 sequence 내 item의 위치, i는 차원을 나타낸다.)
(pos는 sequence 내 item의 위치, i는 차원을 나타낸다.)- 이에 따라 position encoding은 사인 곡선 형태로 나타나며, 파장은 2π to 10000 · 2π 범위에서 결정된다.
- 이는 모델이 relative position을 통해 쉽게 학습할 수 있게 한다.
추가 설명 :
논문에도 써있지만, 위 수식에서 index가 d_model로 나눠지는 것을 통해 index가 d_model까지 반복되는 것을 유추할 수 있고, index는 i번째 dimension을 나타낸다는 것을 알 수 있다.
각 dimension마다 서로 다른 주파수의 sine, cosine 곡선을 가지고, 각 position마다 d_model dimension만큼의 값을 vector로 가지게 된다.
CS182 : Lecture 12(Transformer)에서의 설명을 덧붙이면,
- positional encoding으로 가장 naive한 방법은 각각의 Xt에 x의 위치 t를 추가하는 것이다.
- 하지만 이 방법은 relative position을 고려할 수 없는데, 일반적으로 문장에서는 absolute position보다 relative position이 중요하다.
- 예를 들면, "I walk my dog every day"와 "every day I walk my dog"라는 문맥적으로 동일한 두 문장을 absolute position embedding은 다르게 인식할 것이다.
- relative position에 집중하는 아이디어로, Frequent-based domain을 사용하면 어떨까?
- 선형성을 가지면서도 간단하게 사용할 수 있는 것이 sine과 cosine함수이고, 논문에서도 삼각함수에 몇가지 변수를 추가하여 position embedding을 구현하였다.
- 차원(i)이 커질수록 파장은 길어지는데, 이는 더 넓은 거리를 relative position의 범위로 보겠다는 것이다. 즉, 파장의 범위 내에서 순서를 고려하겠다는 것이다. 그 외 10000이라는 숫자와 d_model은 hyper parameter로 생각하면 된다.
4. Why Self-Attention
- 이 섹션에서는 self-attention을 recurrent, convolutional layer와 여러 측면에서 비교한다.

- Computational complexity per layer
- 위의 표를 통해 알 수 있듯이, self-attention layer는 n < d일 때 다른 layer보다 뛰어난데, 기계번역에서 SOTA인 모델들에서 대부분 그 조건을 만족한다.
- 만약 정말 긴 sequence에서 성능 향상을 원한다면 표에서 네번째 타입과 같이 attention의 범위를 r로 제한하는 방법이 있다. (future work)
-
Sequential Operations (amount of parallelization)
-
Long-range dependecies + network depth
- long-range ependecy와 network의 depth를 같이 보는 이유는, depth가 길수록 long-range dependecy가 사라지기 쉽기 때문이다.
-
Side effect(interpretible)
- attention distribution을 확인할 수 있다.(부록)
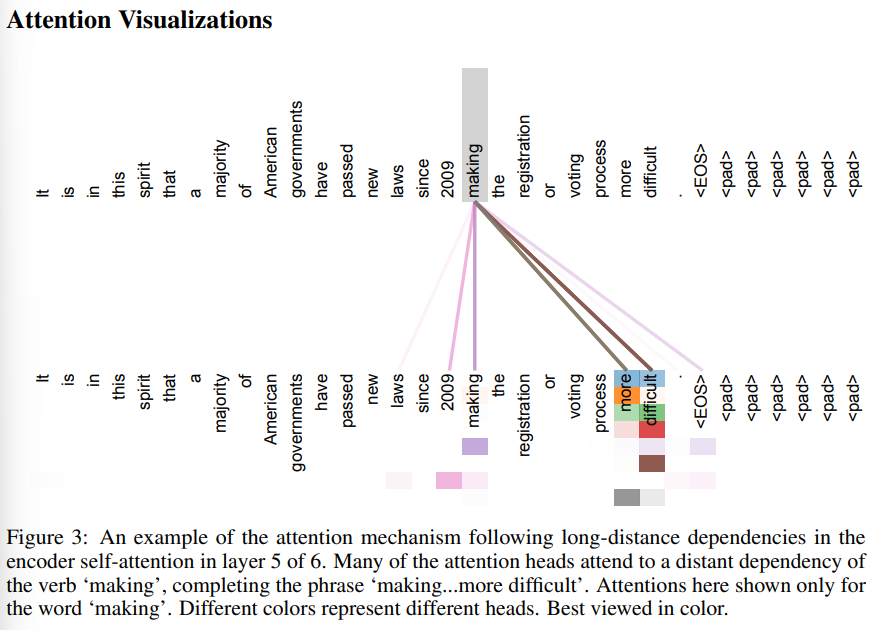
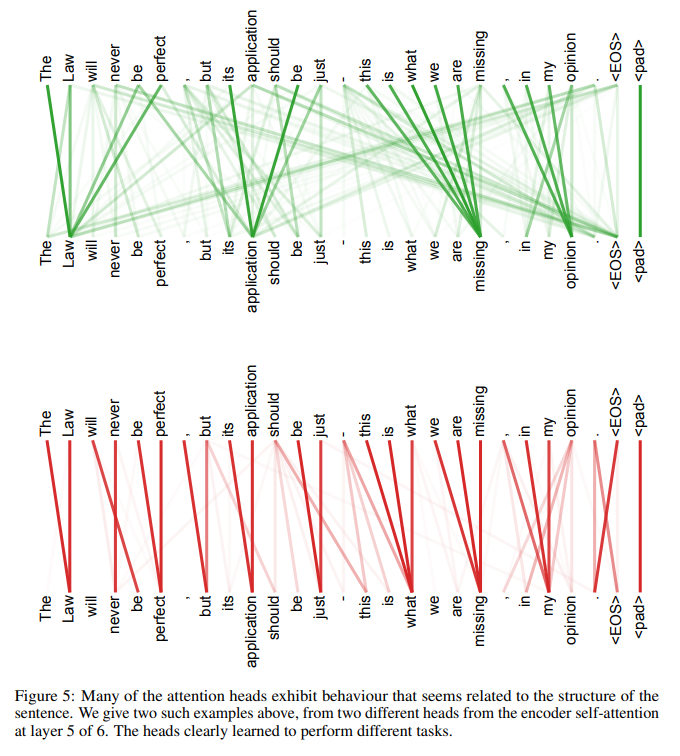
- attention distribution을 확인할 수 있다.(부록)
5. Training
5.1 Training Data and Batching
- WMT 2014 English-German dataset
- 4.5 million sentence pairs
- byte-pair encoding
- target vocabulary of about 37000 tokens
- WMT 2014 English-French dataset
- 36 million sentences
- word-piece encoding
- 32000 tokens
- 언어별 문장들의 pair는 sequence 길이로 batch되었다. 각 training batch는 대략 25000개의 원본 token과 target token으로 구성되었다.
5.2 Hardware and Schedule
- 8개의 NVIDIA P100 GPUs
- base model : training step 당 0.4 seconds * 총 100,000 steps => 12 hours
- big model : step 당 1.0 seconds * 300,000 steps => 3.5 days
5.3 Optimizer
- Adam optimizer with B1 = 0.9, B2 = 0.98, eps = 1e-9
- learning rate는 매 training마다 변하는데, 아래 공식을 따른다.
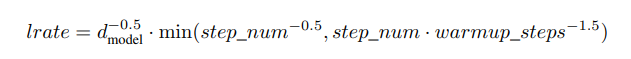 (warmup_step(<=4000)인 초반에는 learning rate가 선형적으로 증가하다가, 그 이후에는 스텝수의 power of -0.5(제곱근의 역수)에 비례하게 감소한다.)
(warmup_step(<=4000)인 초반에는 learning rate가 선형적으로 증가하다가, 그 이후에는 스텝수의 power of -0.5(제곱근의 역수)에 비례하게 감소한다.) - 처음에는 학습이 되지 않은 상태이기 때문에 변화를 크게 주고, 학습이 어느정도 된 시점(warmup = 4000)부터는 세밀하게 학습시키기 위함입니다.
- learning rate는 매 training마다 변하는데, 아래 공식을 따른다.
5.4 Regularization
- 세 가지 타입의 정규화를 사용하였다.
1, 2. Residual Dropout(P_dropout = 0.1)- 각 sub-layer의 출력이 residual connection으로 더해지고, layer normalization으로 정규화되기 전에 dropout을 적용하였다.
- encoder/decoder 양쪽에서, embedding과 positional encoding의 합에 적용하였다.
- 일반적으로 Residual connection은 이전 layer의 출력을 그대로 전달함으로써 vanishing gradient 문제를, dropout은 random하게 neural unit들을 배제함으로써 overfitting 문제를 해결하기 위해 사용합니다. Layer normalization은 gradient의 exploding 또는 vanishing 문제를 완화해주는데, 정확한 mechanism은 해당 논문(Layer Normalization)을 읽어보아야 할 것 같습니다.
- Label Smoothing
- eps 0.1로 하여 label smoothing을 하였는데, perplexity는 떨어지더라도 BLEU score와 정확도가 늘어난다.(overfitting 방지, 이것도 해당 논문(Rethinking the inception architecture for computer vision)을 읽어보아야 할 것 같습니다.)
6. Result
6.1 Machine Translation
- big model이 WMT 2014 영어2독일어 번역 task에서, BLEU 기존 최고기록보다 2.0 높은 점수를 받았다. base model도 적은 cost로 앙상블 모델 포함 기존 다른 모든 model보다 좋은 성능을 보였다. (프랑스어 부분 생략)
- base model에서는 마지막 5개의 check points(10분 간격)의 평균으로 모델을 사용했으며, big model에서는 마지막 20개의 check points를 사용하였다.(checkpoint ensemble)
- beam size 4와 length penalty 알파로 0.6을 사용하여 beam search를 하였고, output의 최대 길이를 input 길이 + 50까지 사용했고, 그 이전에 끝나는 것도 가능하도록 했다.
6.2 Model Variations
- transformer 각 요소의 중요도를 평가하기 위해, base model에 여러 variation을 주어 실험하였다.
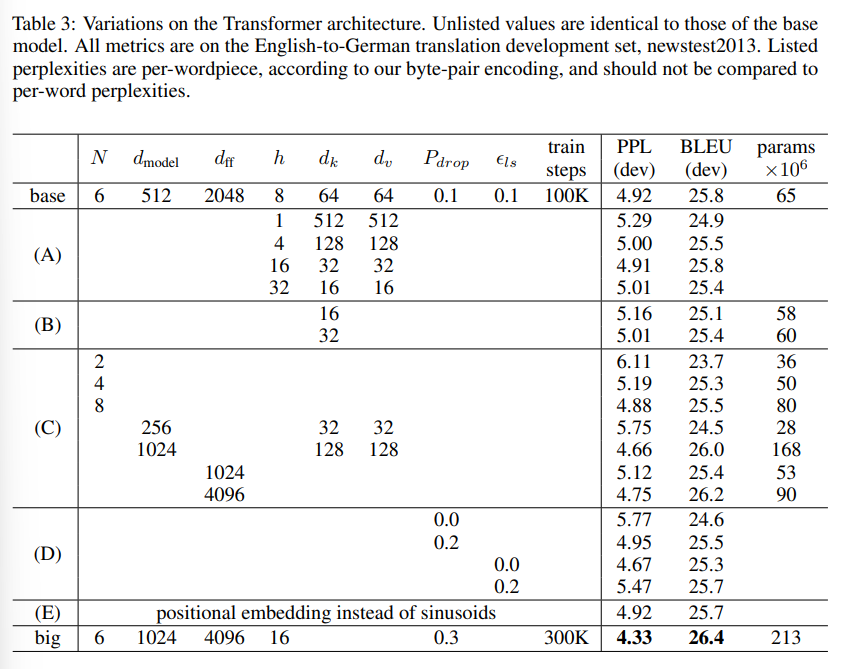 (A)의 경우 cost가 동일한 상황에서 attention head의 개수와 attention key/value 차원에 변화를 주었고, (B)의 경우 attention key size가 크면 좋다는 것을 볼 수 있다. (c)의 경우 모델이 클수록 좋다는 것을 보여주고, (d)의 경우 dropout이 과적합을 방지해 좋다는 것을 보여준다. 마지막으로 (e)의 경우 positional embedding을 sinusoid을 바꾸었는데, 거의 비슷한 결과를 보여주었다.
(A)의 경우 cost가 동일한 상황에서 attention head의 개수와 attention key/value 차원에 변화를 주었고, (B)의 경우 attention key size가 크면 좋다는 것을 볼 수 있다. (c)의 경우 모델이 클수록 좋다는 것을 보여주고, (d)의 경우 dropout이 과적합을 방지해 좋다는 것을 보여준다. 마지막으로 (e)의 경우 positional embedding을 sinusoid을 바꾸었는데, 거의 비슷한 결과를 보여주었다.
6.3 English Constituency Parsing
일반화 성능을 확인하기 위해 해당 task를 수행하였고, 잘 기능하는 것을 확인하였다.
7. Conclusion
- 본 논문에서는 기존 다른 architecture들을 대체할 첫 번째 Attention based model로 Transformer를 제시하였다.
- 번역 task에서, Transformer는 굉장히 빠른 속도로 학습하면서도 SOTA를 차지하였다.
- future of attention-based model들을 기대하고, 다른 task(이미지, 오디오, 비디오 등)로의 응용을 기대한다. 출력을 less sequential하게 생성하는 것 또한 하나의 research goal이다.
