1. Before reading this paper
논문을 읽기 전에 공부한 내용입니다. 논문의 흐름과 동일하게 구성하였습니다.
Attention은 입력 sequence에서 특정 위치에 얼마나 집중해야 하는지를 나타낸다. 이 개념은 해당 논문에서 제시한 모델 'Transformer'에서 처음 사용된 것은 아니지만, 기존엔 Convolution 등 특정 블록에 얹어지는 정도로 사용했다면 이를 Main Block으로 사용하여 혁신적인 모델이였고, 성능과 cost 측면에서 매우 큰 성과를 얻어 빠르게 주목받았다. (GPT 또한 transformer 구조를 사용한다.)
1-1. Transformer의 구조
Transformer는 전체적으로 인코더-디코더 구조를 가지고 있다. encoder, decoder 각각에서 sub-layer들은 residual connection으로 연결되어 있고, 그 후에는 layer-normalization 과정을 거친다.
인코더는 Self-Attention layer, Feed-forward layer로 구성되어 있다. 인코더로 들어온 입력은 Self-Attention layer에서 다른 단어들과의 관계를 반영하여 변환된다. 변환된 vector는 feed-forward 신경망으로 들어가 decoder로 보낼 출력을 만든다.
디코더는 인코더에서의 두 레이어 사이에 encoder-decoder layer가 추가된 형태이다.
1-2. Attention Mechanism (in self-attention layer)
이제 attention의 mechanism에 대해 설명해보자면,
self-attention layer에서는 encoder에 입력된 벡터(각 단어의 embedding 벡터)들로부터 "Query", "Key", "Value"라는 3차원의 벡터를 만들어낸다. 이 벡터들은 세 개의 learnable matrix(W_q, W_k, W_v)에 입력 벡터를 곱하여 만들 수 있다. (단어를 embedding하는 것이 궁금하시다면 Word2vec에 대해 정리한 글을 번역하였으니 확인해보시기 바랍니다.)
 (ref. Jay Alammar's Blog)
(ref. Jay Alammar's Blog)
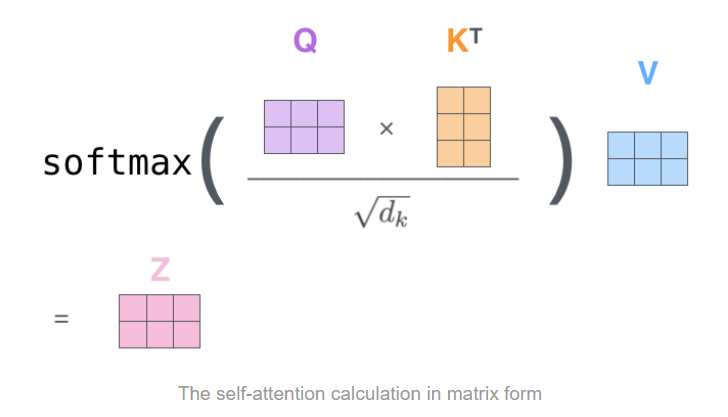
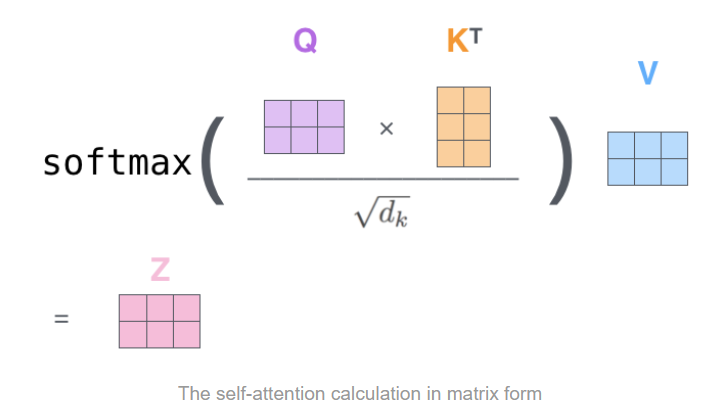
그 다음 각 단어 사이의 상관도(유사도)를 나타내는 "Attention score" 벡터를 구하는데, 이는 내적으로 벡터끼리 얼마나 align 되어있는지를 통해 얻는다. 좀 더 자세히 설명하자면, 각 위치별로 해당 단어의 query vector와 나머지 단어들의 key vector들을 내적한 뒤, scale을 거쳐(paper review part에서 자세히 다룹니다.) softmax에 넣어 score vector의 모든 요소를 양수로 만들고, 그 합을 1로 맞추어준다. 이렇게 구한 score vector가 해당 단어를 볼 때 다른 위치의 단어(문맥)에 얼마나 집중해야 하는지를 알려준다.
영어가 모국어가 아니다보니, 각 vector의 naming에 대해 조금 더 천천히 음미하고 가면 좋을 것 같습니다. attention mechanism은 attention이라는 단어의 뜻처럼, 해당 단어를 읽을 때 문맥의 어느 부분에 집중해야할지 알려주는 mechanism입니다. 그래서 해당 단어의 query vector를 사용해 다른 단어들 각각에 대해서 얼마나 중요한지(해당 단어와 얼마나 관련이 있는지)를 물어보고, 다른 단어들은 key를 통해 대답한다고 이해하면 좋을 것 같습니다.
이제 각 단어들의 value 벡터에 score를 곱하여 유사도가 높은 벡터들에 가중치를 준다. 그 다음 weighted vector들을 모두 합하여 self-attention layer의 출력으로 내보낸다. 추가로 각각의 입력 embedding에 positional encoding이라는 벡터를 추가하여 sequence 내 각 단어의 위치 정보를 결정한다.(이후 paper review part 3.5에서 자세히 설명)
1-3. multi-head self attention
transformer에서는 self-attention layer에 multi-headed attention이라는 메커니즘을 더한다. 이는 모델이 다른 위치에 집중하는 능력(기존 attention은 스스로에게 너무 높은 score를 가짐)을 향상시키고, 여러 개의 representation 공간(논문에서는 8개)을 갖게 한다.
representation 공간을 늘리는 것은 query, key, value를 만드는 각 행렬을 랜덤하게 초기화시켜 여러 개의 query/key/value set을 만들고, 그렇게 만들어진 다양한 vector를 통해 점수를 여러 번 구하는 방식이다. 여러 개의 representation을 가짐으로써 병렬화 뿐만 아니라 모델의 표현력이 증가하고, 과적합을 방지할 수 있을 것 같습니다.
feed-forward layers에서는 하나의 matrix를 받기 때문에, multi-head 기법으로 늘어난 행렬들을 하나의 행렬로 연결(concat)한다.
1-4. decoding step
decoding step은 출력 완료를 의미하는 기호(end of sentence)를 출력할 때까지 반복되며, encoder의 self-attention과는 이전 위치에 대해서만 attend할 수 있다는 점이 다르다.(softmax 취하기 전에 현재 스텝 이후의 위치에 -inf로 마스킹하여 구현한다. softmax(-inf) = 0이기 때문.)
encoder-decoder attention layer는 self-attention과 한 가지 다른데, query 행렬들을 그 밑의 layer에서 가져오고, key와 value 행렬들을 encoder의 출력에서 가져온다는 점이 다르다. 즉, attention mechanism을 encoder의 sequence에서 실행하므로 encoder-decoder attention이다. 반면 self-attention은 자기자신의 sequence에서 수행한다.
마지막으로 Fully connected layer를 통해 마지막으로 나온 float 벡터 하나를 가지고 있는 vocabulary의 크기만큼 키우면, 벡터의 각 셀은 대응되는 단어에 대한 점수가 되고, softmax를 통해 각 단어의 확률로 변환하여 가장 높은 확률값의 단어를 출력하게 된다.
본격적으로 paper review로 넘어가기 전에, Recurrence 구조와 Attention-based 구조의 차이점을 짚어보겠습니다.
Recurrence 구조에서는 hidden state에 이전 정보들을 담고 있기 때문에, 문장의 길이가 길어져 depth가 커지면 hidden state가 이전의 모든 정보들을 충분히 표현하지 못합니다(long term dependecy problem). 반면 Attention-based 구조에서는 모든 item(단어)에 대해 vector를 만들기 때문에 memory cost는 커지지만 위치에 관계없이 단어간 유사도를 표현할 수 있습니다. 병렬적으로 처리하며 잃어버린 순서정보는 positional encoding을 통해 보완합니다.

아주 유익한 내용이네요!