Published in Current Biology, 2022
Summary
-
변연계에 존재하는 세로토닌 뉴런들은 외부 환경에 대한 학습률 조절에 관여함
-
약 50%는 expected uncertainty에 반응하고 약 33%는 unexpected uncertainty에 반응
Introduction
동물의 신경계를 모델링할 때는 Reinforcement Learning(RL)을 종종 사용합니다. 외부 환경과의 상호작용을 통해 피드백을 수용하고, 행동을 수정하는 메커니즘이 비슷하기 때문입니다. 이 때 expected reward와 실제 결과와의 괴리(오차)를 Reward Prediction Error (RPE)라고 합니다.
외부 환경은 항상 변하므로, 이에 잘 대응하기 위해 외부에서 얻는 정보와 내가 가진 정보를 얼마나 활용할 것인지를 나타내는 learning rate를 잘 정하는 것이 중요합니다. 적절한 learning rate를 설정하려면 개체(시스템)가 가진 사전 정보와 외부에서 들어오는 정보를 모두 고려해야 하며, 이러한 요소들을 모두 고려하여 의사 결정을 했을 때 예상되는 결과의 불확실성을 uncertainty라고 부릅니다.
Uncertainty에는 크게 2가지가 있습니다. 만약 환경에 대한 정보가 있어 어느 정도 미리 예측이 가능하다면 expected uncertainty라고 부릅니다. 이 때는 외부 환경에 대한 learning rate가 감소합니다. 디테일을 살피기 위해 천천히 훑어보는 것과 비슷합니다.
반대로 expected uncertainty가 변화하여 예측할 수 없게 된 상태를 unexpected uncertainty라고 합니다. 만약 unexpected uncertainty가 발생한다면 외부 환경에 대한 learning rate가 증가해야 합니다. 환경을 파악하기 위해서 더 많은 정보가 필요하기 때문입니다.
이런 식으로 의사 결정 방식을 조정하는 것을 Meta Learning이라고 합니다. 흔히 '메타인지가 중요하다'라고 할 때 바로 그 '메타'와 같습니다. 메타 학습에서는 주변 환경과 자기 자신에 대한 정보를 잘 파악하는 것이 중요합니다.
Serotonine modulate learning rate
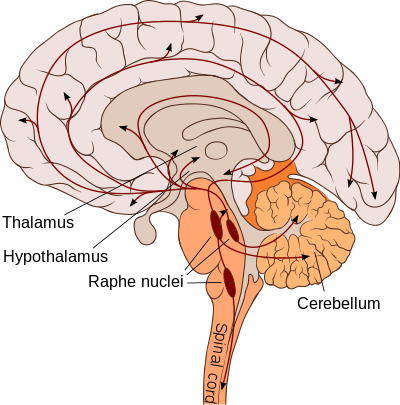
변연계에 있는 등쪽솔기핵(배측봉선핵, dorsal raphe)에는 세로토닌을 분비하는 뉴런 뭉치가 있는데 이 부분은 의사 결정과 학습을 담당하는 뇌 영역과 밀접한 연관이 있다고 알려져 있습니다.
이 뉴런들은 환경의 변화에 따라 빠르게(수백 ms) 또는 느리게(수십 s) 반응하는데, 이 부분에 장애가 있거나 일시적으로 물질 전달을 막아버리면 외부 자극에 적절하게 대응하지 못하게 됩니다. 아예 반응을 못하지는 않지만, 서로 다른 자극에 대해 적절한 반응을 새로 생성하는 속도가 매우 느려집니다. 뉴런 입장에서는 외부 환경의 변화가 거의 없다고 착각하고 expected uncertainty 정보만으로 대응하게 되는 것입니다.
반대로 만약 결과를 예상하기 힘든 확률적인 선택을 해야 하는 경우, 예컨대 도박처럼 unexpected uncertainty가 높은 상황에서는 세로토닌 뉴런들이 상대적으로 빠르게 흥분합니다. 이 과정에서 상대적으로 오래 전의 정보까지 참고하려는 경향이 나타나는데, 이는 아는 것이 별로 없는 새로운 문제를 맞닥뜨리면 최대한 알고 있는 정보들을 취합하여 대응한다고 볼 수 있습니다.
Experiment
Brief
실험은 쥐 48마리와 Q-learning 기반의 RL 모델을 사용하였습니다. 실험 결과에 따르면 expected uncertainty와 관련된 약 50%의 뉴런들은 수십 초 단위로 늦게 반응하고, unexpected uncertainty와 관련된 뉴런들은 거의 즉각적으로 반응했습니다.
모델에서 meta learning 모듈을 제거하면 쥐의 솔기핵의 세로토닌 뉴런들을 제거하였을 때와 같은 결과가 나타났습니다.
Details
Dynamics of mice decison making
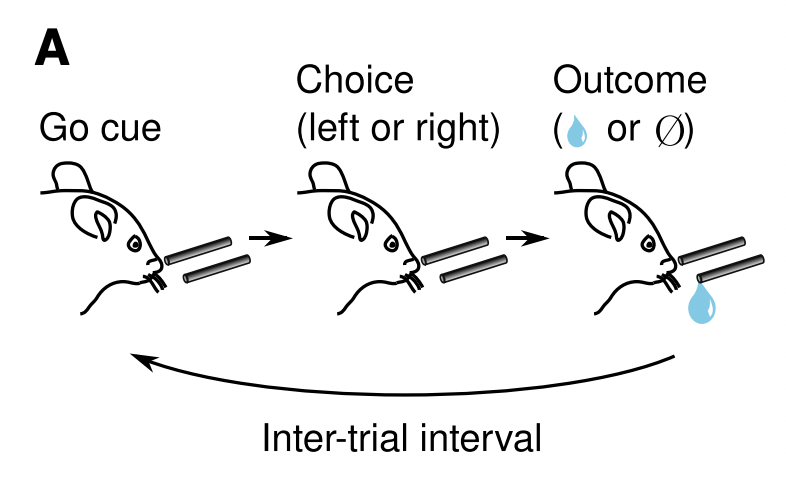
저자들은 위 그림과 같이 2개의 급수관을 놓고, Go 신호를 주는 간격을 조절하면서 쥐의 반응을 관찰하는 식으로 실험을 진행하였습니다. 총 각 급수관에 20~35 trial마다 다음과 같은 reward probability를 랜덤하게 바꿔주었으며, 총 300회의 trial을 수행하였습니다.
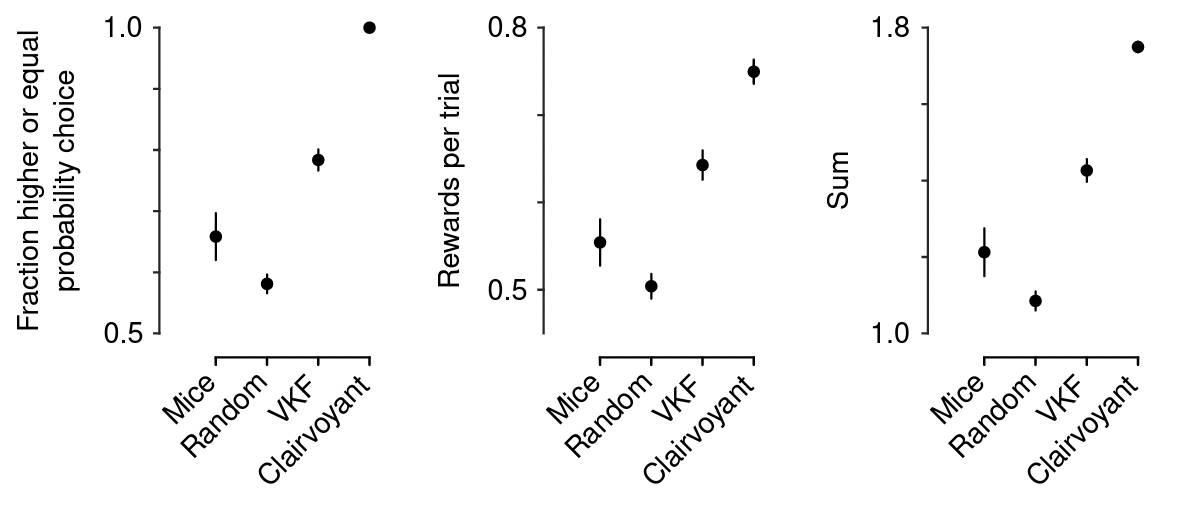
2/3의 쥐들은 더 확률이 높거나 비슷한 급수관을 선택했고, 승률은 약 55%로 random agent보다는 나았지만 optimized model보다는 더 낮은 결과를 보였습니다. 생각보다 승률이 높지 않네요.
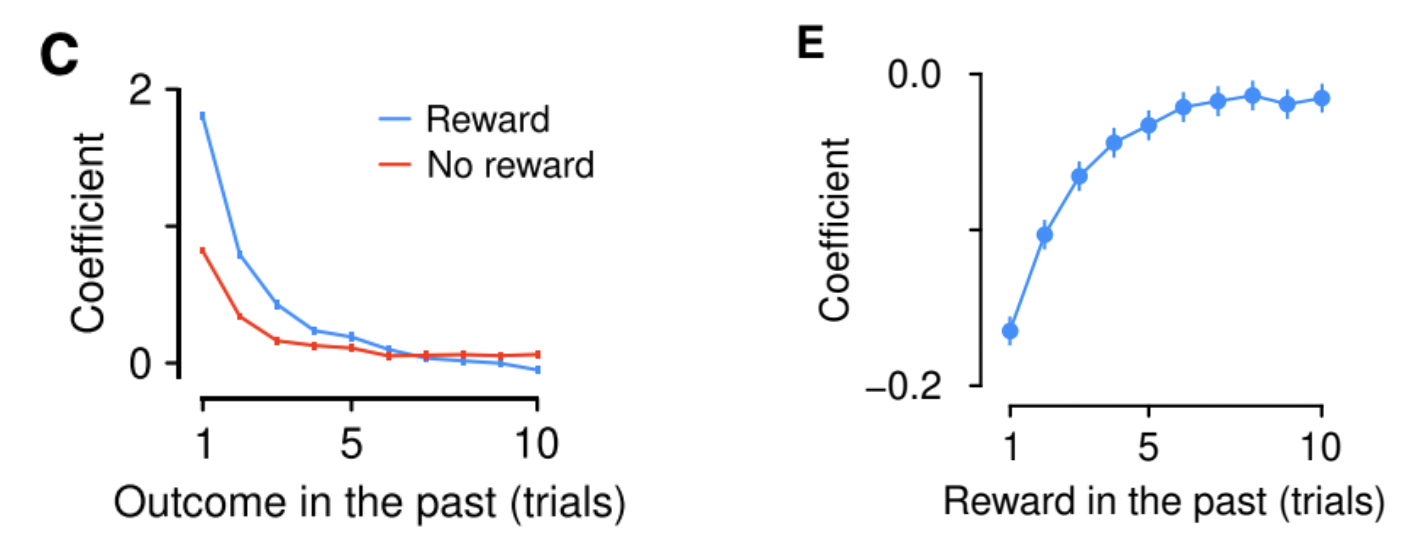
위 그림은 trial 간격에 따른 decision coefficient를 나타낸 것입니다. Reward가 주어졌을 때는 최근 정보를 더욱 우선적으로 고려하는 반면, reward가 주어지지 않았을 경우 오래된 정보도 상대적으로 균등하게 고려합니다. 즉, 쥐들은 최근 경험을 더 우선시하여 의사 결정을 내린다고 할 수 있습니다.
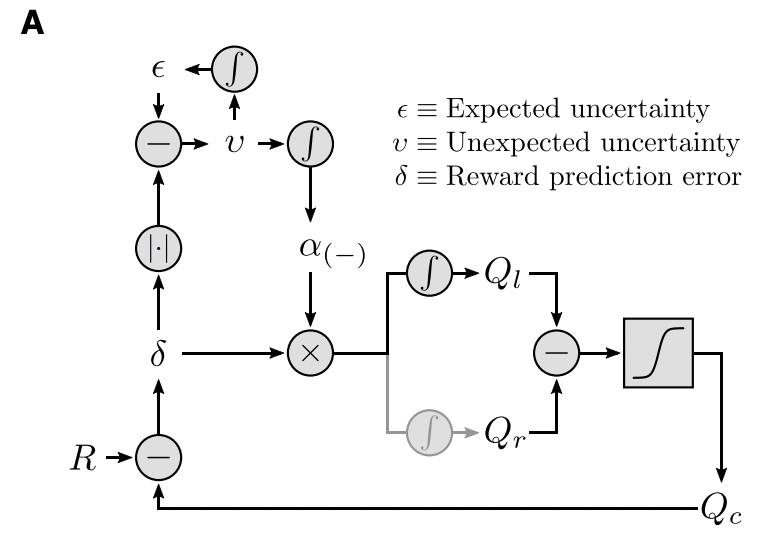
저자들은 쥐의 행동을 모델링하기 위해 위 그림과 같은 policy를 사용하는 Q-learning 기반 모델을 만들어 실험하였습니다. 학습은 RPE를 기준으로 임의의 learning rate를 사용하여 진행되었습니다.
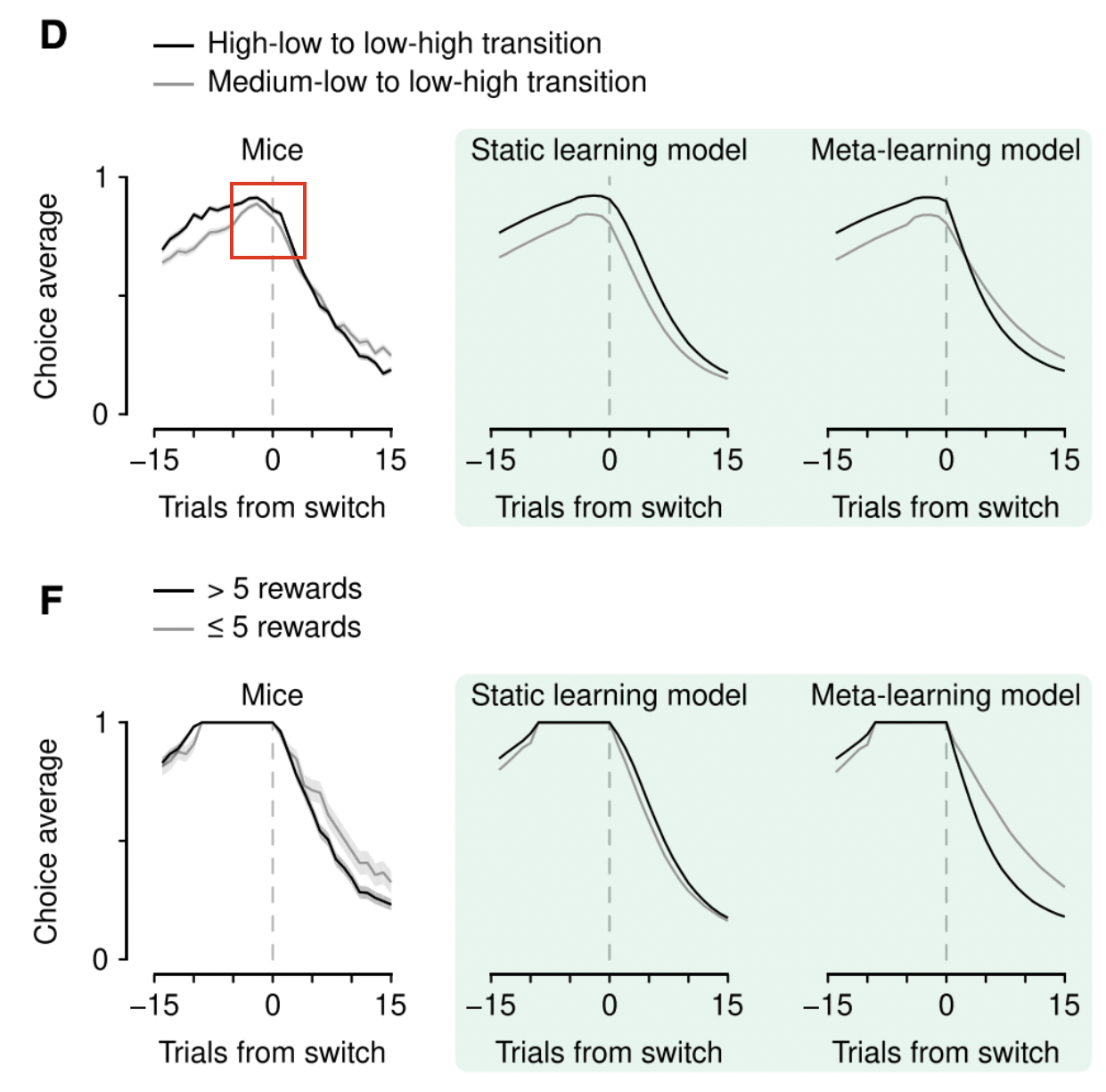
먼저 learning rate를 고정시킨 static learning model의 경우, 전반적으로 쥐의 행동을 잘 모델링하고 있지만 reward probability가 바뀌는 시점 근처에서 나타나는 변화들을 모델링하지는 못합니다.
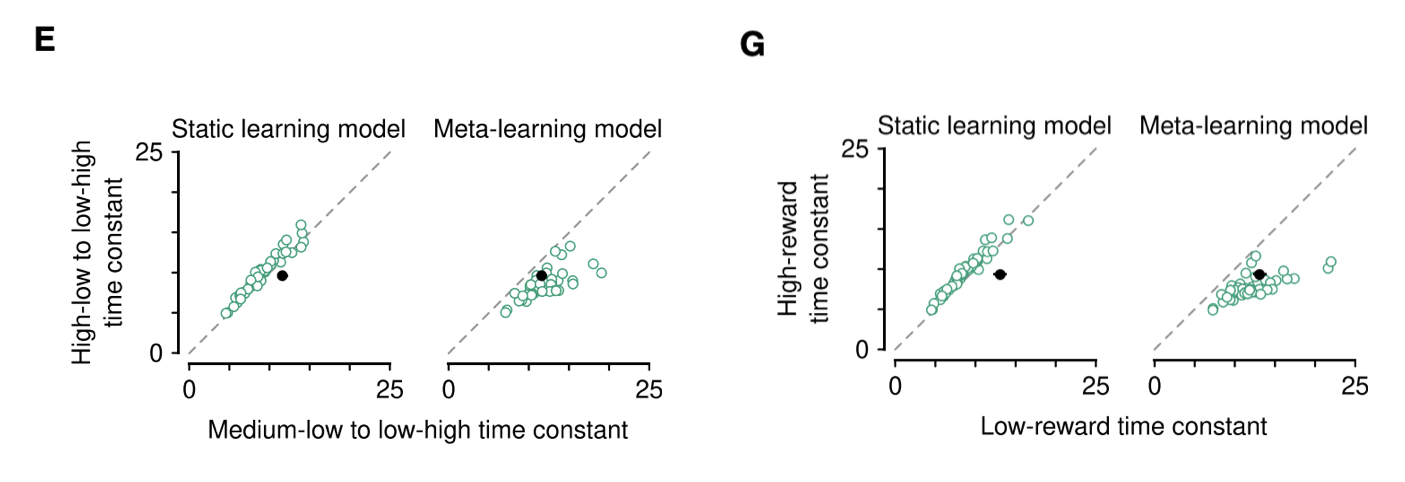
특이한 점은 reward probability가 low & high 상태에서 high & low로 바뀌는 경우 쥐들은 빠르게 변화를 감지하고 대응하였으나, reward probability가 medium & low 상태에서 low & high 상태로 바뀌는 경우에는 상대적으로 반응하는 속도가 느려졌다고 합니다. 회색 그래프를 보면 변화하는 속도가 상대적으로 느린 것을 알 수 있습니다.
이러한 현상은 특히 experienced history를 기준으로 sort해서 보면 조금 더 명확하게 알 수 있습니다. 위 그림을 보면 learning rate가 바뀌지 않는 static model은 시간이 지나도 action이 거의 달라지지 않지만 meta learning model은 시간이 지나면 action이 변화하는 것을 볼 수 있습니다.
즉, '지난 번에는 오른쪽 빨대를 건드렸으니까 이번엔 왼쪽을 건드려볼까?' 같은 식으로 choice history에 기반하여 선택하는 게 아니라, '지난 번에는 오른쪽 빨대에서 물이 나왔으니 이번에도 오른쪽을 선택해보자'와 같이 outcome history에 기반하여 의사 결정을 내린다는 것입니다.
전반적으로 reward probability가 high to low로 바뀌는 경우에 medium to low로 바뀌는 경우보다 더 명확한 변화를 보이는데, 이는 learning rate가 expected uncertainty에 기반하여 바뀐다는 것을 내포합니다. 즉, 행동과 결과에 대한 확실한 기댓값이 존재한다면 의사 결정이 더 명료해진다고 할 수 있습니다.
저자들은 위 meta-learning 모델에서 expected uncertainty가 증가하면 학습 속도가 느려진다는 사실을 바탕으로 unexpected uncertainty(unsigned RPE)와의 차이를 비교하고 outcome history에 대해 뇌가 어떻게 학습하는지를 살펴보았습니다.
실험 결과에 따르면 recent history와 크게 다른 RPE가 발생하면 (=unexpected uncertainty) 더 많은 학습이 진행되었습니다. 이는 환경이 바뀌었다는 것을 암시하며, 회로(brain)가 학습량을 더 늘려야 한다는 신호로 해석할 수 있습니다.
저자들은 또한 reward가 주어지지 않는 상황에서도 쥐들이 빨대를 여러 번 핥아보는 것을 발견했습니다. 쥐들은 빨대에서 물이 나올 거라고 기대했지만 실제론 그렇지 않았을 때 더 많이 빨대를 핥았는데, 이는 RPE의 크기보다는 meta-learning model의 unexpected uncertainty로 더 잘 설명할 수 있었다고 합니다. 쉽게 말해서 기대가 배신당했을 때 여러 번 더 시도해본다는 것입니다.
Serotonin neurons correlate with expected uncertainty
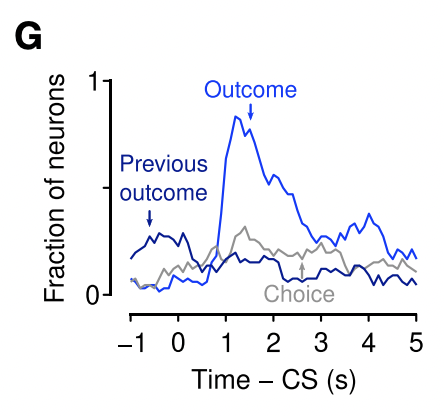
실험을 위해 foraging task를 수행중인 쥐들의 dorsal raphe neurons의 활동전위를 측정하였습니다. 대부분의 세로토닌 뉴런들은 Go 사인을 받았을 때 즉각적으로 흥분했으며, 특히 reward가 주어졌을 때와 주어지지 않았을 때 확연히 다르게 반응했다고 합니다.
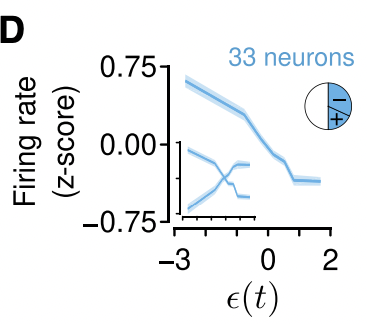
저자들은 50%의 뉴런들의 firing rate가 expected uncertainty에 큰 영향을 받는 것을 발견했습니다. 그 중에서도 약 1/3은 비례 관계를 보였고 2/3는 반비례하였다고 합니다. 특히 반비례 관계를 보이는 뉴런들은 certainty, reliability, predictability와의 관계를 나타낸다고 해석할 수 있습니다. 쉽게 말해 expected uncertainty가 증가하면 약 33%의 세로토닌 뉴런들의 firing rate가 감소하면서 learning rate가 줄어들고, 이는 곧 certainty, reliability, predictability가 높다는 것을 의미합니다.
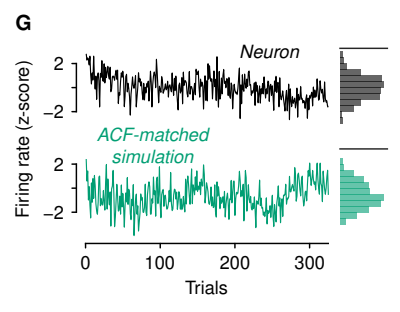
또한 실제 뉴런들의 활동을 기록한 데이터와 meta-learning model을 가지고 시뮬레이트한 데이터가 매우 비슷했다고 합니다.
Serotonin neurons correlate with unexpected uncertainty at outcomes
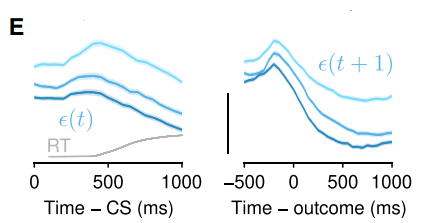
저자들이 실험에 사용한 meta-learning model에서는 unexpected uncertainty function에 따라 expected uncertainty가 변화합니다. 이를 기반으로 쥐의 뉴런을 관찰한 결과, Go 사인을 받고 어느 빨대를 핥을지 결정하기 전까지 expected uncertainty에 관련된 세로토닌 뉴런들이 빠르게 활성화되는 것을 발견하였습니다. 이러한 현상은 expected uncertainty 가 업데이트되기 전, 그러니까 빨대를 선택하고 reward를 받기 전까지 지속적으로 나타났습니다.
반대로 unexpected uncertainty 와 관련된 뉴런들은 outcome (reward)에 주로 반응하였으며 대부분 reward가 커질 수록 더 많이 흥분하는 양상을 보였습니다. 일부 뉴런은 양쪽 모두에 반응하였으나, 대부분의 경우 각 뉴런은 한 가지 종류의 uncertainty에만 반응하였습니다.
Serotonin neurons correlate with unexpected uncertainty at Pavlovian task
이상의 실험을 바탕으로 저자들은 세로토닌 뉴런과 uncertainty 간의 상관 관계가 다른 behavioral tasks에도 적용될 수 있다는 가설을 세웠습니다.
이를 검증하기 위해 9마리의 쥐를 위 그림과 같은 Pavlonian version task로 훈련시켰습니다. 또한 meta learning model을 사용하여 쥐들의 행동을 모델링하였습니다.
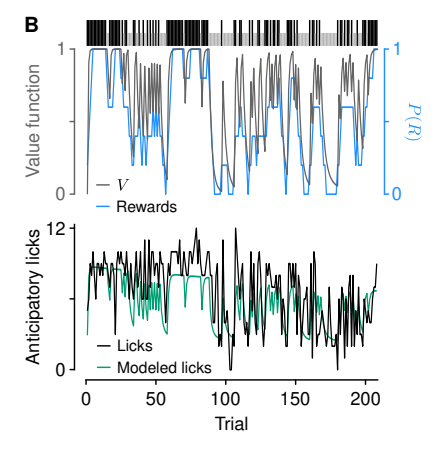
특이한 점은 위 그림처럼 모델의 움직임과 실제 쥐의 행동 데이터가 비슷했음에도 불구하고 앞선 실험들처럼 learning rate가 달라지는 현상이 나타나지 않았다는 것입니다. 다만, 이 실험에서 expected uncertainty와 관련된 dorsal raphe neuron activation은 dynamic foraging task에서 나타난 것과 매우 비슷했습니다.
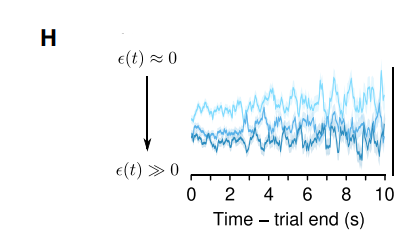
Foraging task 때와 마찬가지로 stable한 firing rate를 보였으며, 약 50%의 뉴런은 expected uncertainty에 반응하였고 나머지 50%의 뉴런은 outcome을 통해 얻는 unexpected uncertainty 정보에 반응하는 것을 확인하였습니다. 즉, task 종류에 상관 없이 세로토닌 뉴런들은 (un)expected uncertainty에 반응하는 특성을 보였습니다.
Serotonin neuron inhibition disrupts meta-learning
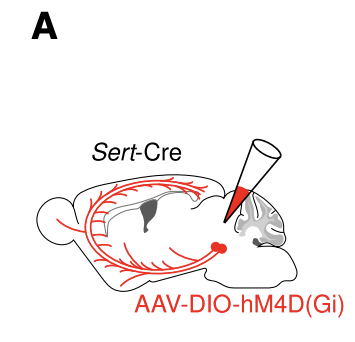
저자들은 세로토닌 뉴런의 활성화를 억제하면 learning rate modulation이 불가능해지는지를 검증하기 위해 위와 같은 designer receptor exclusively activated by designer drugs (DREADD) 실험을 진행하였습니다.
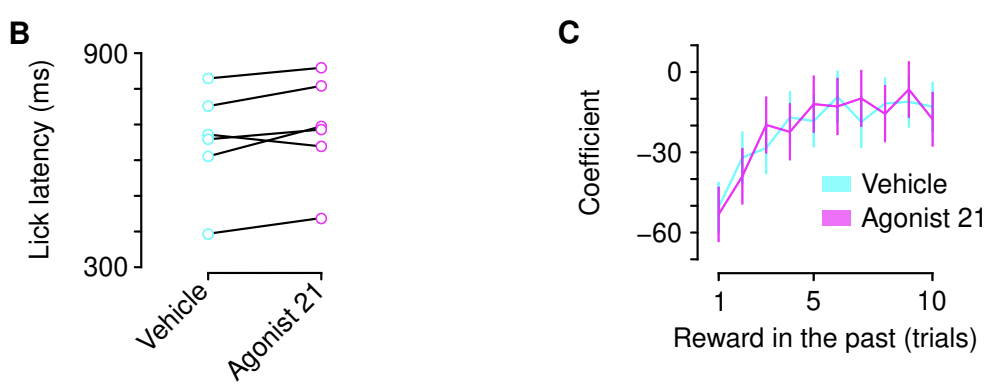
결과를 보면 세로토닌 뉴런을 억제한다고 해서 반응속도가 느려지거나 outcome(reward)에 대한 의존성이 변화하지는 않았습니다.
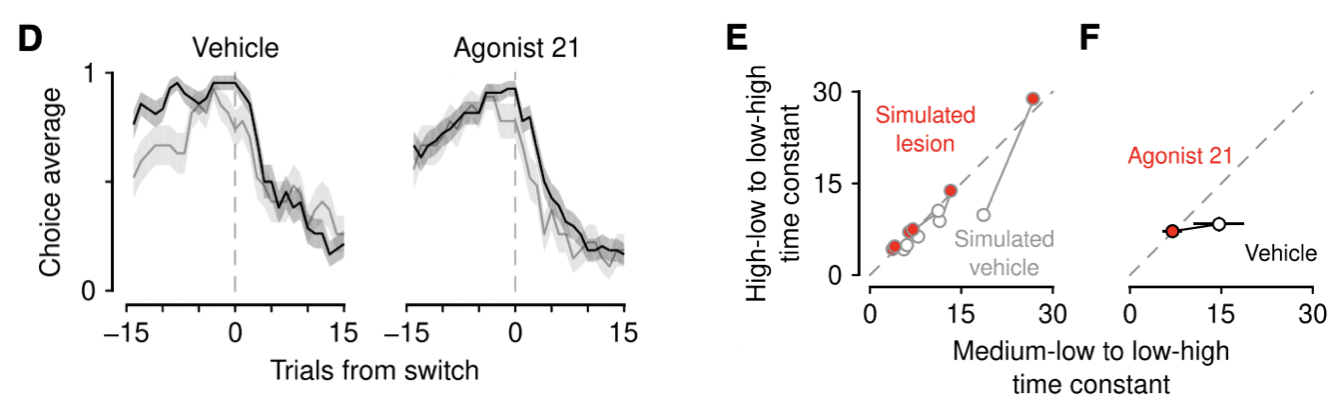
하지만 세로토닌 뉴런을 억제한 쥐의 행동 양상은 달라지는데, 특히 위 그래프에서 choice average가 변화하여 fixed learning rate model과 유사해지는 것을 볼 수 있습니다.
따라서 세로토닌 뉴런들은 uncertainty encoding을 통해 learning rate modulation에 관여한다고 할 수 있습니다.
References
[1] 신경조절물질(neuromodulator) - 위키백과
[2] 세로토닌 - 위키백과
[3] Senotonin Pathway - Wikipedia
