파이썬으로 데이터를 다루다보면 자주 보이는 파일 확장자가 몇 가지 있는데,
그 중에서 가장 자주 보이는 csv, xml, json 처리 방법에 대해 알아보자.
CSV
csv는 Comma Seperated Value의 약자이다.
*.csv 파일은 이름답게 각 컬럼(column)을 쉼표로 구분한다.
billboardchart = {
1 : ["Tho Box","Roddy Ricch","2019-12-19"],
2 : ["Don't Start Now", "Dua Lipa", "2019-11-01"],
3 : ["Life Is Good", "Future Featuring Drake", "2020-02-10"],
4 : ["Blinding", "The Weeknd", "2019-11-29"],
5 : ["Circles", "Post Malone","2019-08-30"]}
with open("billboardchart.csv","w") as f:
for i in billboardchart.values():
data = ",".join(i)
f.write(data+"\n")위와 같은 파일을 생성하고....
import csv
header = ["title", "singer", "released date"]
with open("billboardchart.csv","r") as inputfile:
with open("billboardchart_out.csv","w", newline='\n') as outputfile:
fi = csv.reader(inputfile, delimiter=',')
fo = csv.writer(outputfile, delimiter=',')
fo.writerow(header)
for row in fi:
fo.writerow(row)컬럼명을 추가해줄 수 있다.
import pandas as pd
import csv
# 데이터 준비
fields = ["title", "singer", "released date"]
rows = [ ["Tho Box","Roddy Ricch","2019-12-19"],
["Don't Start Now", "Dua Lipa", "2019-11-01"],
["Life Is Good", "Future Featuring Drake", "2020-02-10"],
["Blinding", "The Weeknd", "2019-11-29"],
["Circles", "Post Malone","2019-08-30"]]
# 판다스로 데이터를 csv 파일로 저장
df=pd.DataFrame(rows, columns=fields)
df.to_csv('pandas.csv',index=False)
# csv.writer 써보기
filename = "test.csv"
with open(filename, 'w+', newline='\n') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(fields)
csv_writer.writerows(rows)위와 같이 pandas의 df.to_csv()를 활용해서 파일을 생성할 수도 있다.
XML
xml은 Extensible Markup Language의 약어로, 다목적 마크업 언어라는 의미이다.


기본적으로 위와 같은 구조를 가지고 있다.
XML 파일은 태그로 구분되며, 태그에 속성값 attribute가 포함될 수 있다.
각 태그는 요소 element로 지칭된다.
<Table>
<Row>
<Cell>
<Data ss:Type="String">Notice</Data>
</Cell>
</Row>위와 같이 태그 안에 태그가 포함될 수도 있다.
Class 개념을 생각하면 이해하기 쉽다.
부를 때도 부모-자식 태그로 부른다.
이 경우에는 Table은 Row의 부모 태그이고 Cell은 Row의 자식 태그이다.
ElementTree
ElementTree는 XML 관련 기능을 제공하는 파이썬 표준 라이브러리이다.
Element(): 태그 생성SubElement(): 자식 태그 생성tag: 태그 이름text: 텍스트 내용 생성attrib: 속성 생성dump(): 생성된 xml 요소 구조를 시스템(sys.stdout)에 사용. (출력 형식은 일반 xml파일)write(): XML 파일로 저장 (파이썬 list와 유사한 메소드(append(), insert(), remove(), pop() 등) 제공)
import xml.etree.ElementTree as ET
person = ET.Element("Person")
name = ET.Element("name")
name.text = "이든"
person.append(name)
age = ET.Element("age")
age.text = "28"
person.append(age)
ET.SubElement(person, 'place').text = '강남'
ET.dump(person)
>>>
<Person>
<name>이든</name>
<age>28</age>
<place>강남</place>
</Person>위와 같이 XML파일을 생성할 수 있다.
XML 파싱
프론트엔드 할 것도 아닌데 왜 XML 구조를 잘 알아야 하냐면, 구조를 알아야 데이터를 파싱해서 가져올 수 있기 때문이다.
주로 크롤링할 때 많이 사용한다.
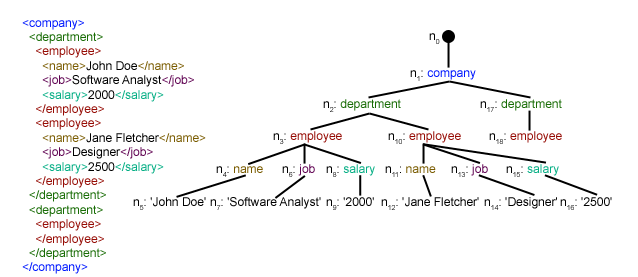
(출처: https://www.geeksforgeeks.org/xml-parsing-python/)
Parsing
파싱은 문자열을 토큰 단위로 분해해서 의미와 구조를 반영한 트리를 만드는 것이다. 웹 문서를 파싱하면 요소 단위로 접근해서 필요한 내용만 가져올 수 있다.
BeautifulSoup
앞에서 언급한 ElementTree 말고 beautifulsoup4라는 라이브러리도 많이 사용한다.
BeautifulSoup | Docs
JSON
JSON은 JavaScript Object Notation의 약어다.
이름을 보면 알겠지만 자바스크립트의 데이터 객체 표현 방식을 일컫는다.
브라우저 <-> 애플리케이션 사이에 HTTP 요청을 통해 데이터를 전송할 때 사용하는 표준 파일 포맷 중 하나로, XML과 함께 웹 API나 config 데이터를 전송할 때 많이 사용한다.
왜 그런지는 데이터 구조를 잘 살펴보면 알 수 있다.
person = {
"first name" : "Yuna",
"last name" : "Jung",
"age" : 33,
"nationality" : "South Korea",
"education" : [{"degree":"B.S degree", "university":"Daehan university", "major": "mechanical engineering", "graduated year":2010}]
} 딱 봐도 파이썬 딕셔너리와 비슷하게 생겼다.
그래서 딕셔너리와 비슷한 장점을 가지고 있다.
JSON 파일은 CSV 파일에 비해 조금 더 유연하게 데이터를 표현할 수 있고, XML 파일보다 쉽게 읽고 쓸 수 있다.
애초에 자바스크립트에서 출발했기 때문에 자바스크립트를 쓰는 프로그램에서 쉽게 처리할 수 있다는 장점도 있다. 웹의 3신기가 자바스크립트, css, html인걸 생각하면 이건 매우 중요한 포인트다.
JSON 파싱
비슷하면 비슷하게 쓸 수 있다.
파이썬 딕셔너리를 JSON으로 저장할 수 있다는 뜻이다.
import json
person = {
"first name" : "Yuna",
"last name" : "Jung",
"age" : 33,
"nationality" : "South Korea",
"education" : [{"degree":"B.S degree", "university":"Daehan university", "major": "mechanical engineering", "graduated year":2010}]
}
with open("person.json", "w") as f:
json.dump(person , f)당연히 JSON 파일을 딕셔너리 객체로 읽어오는 것도 가능하다.
import json
with open("person.json", "r", encoding="utf-8") as f:
contents = json.load(f)
print(contents["first name"])
print(contents["education"])파이썬에서 딕셔너리 객체를 바로 pandas.DataFrame으로 바꿀 수 있기 때문에 아주 유용하게 쓸 수 있다.
