
Chapter 2 머신러닝 프로젝트 처음부터 끝까지 (~2.3까지)
- 주요 단계
- 큰 그림을 본다.
- 데이터를 구한다.
- 데이터로부터 통찰을 얻기 위해 탐색하고 시각화한다.
- 머신러닝 알고리즘을 위해 데이터를 준비한다.
- 모델을 선택하고 훈련시킨다
- 모델을 상세하게 조정합니다.
- 솔루션을 제시합니다.
- 시스템을 론칭하고 모니터링하고 유지 보수합니다.
2.1 실제 데이터로 작업하기
머신러닝을 배울 때는 인공적으로 만들어진 데이터셋이 아닌 실제 데이터로 실험해보는 것이 가장 좋다.
- 유명한 공게 데이터 저장소
- UC 얼바인 머신러닝 저장소
- 캐글 데이터 셋
- 아마존 AWS 데이터 셋 - 메타 포털 (공개 데이터 저장소가 나열되어 있는 페이지)
- 데이터 포털
- 오픈 데이터 모니터
- 퀸들 - 인기 있는 공개 데이터 저장소가 나열되어 있는 다른 페이지
- 위키백과 머신러닝 데이터셋 목록
- Quora.com
- 데이터셋 서브레딧
이 장에서 다루는 데이터
- 1990년 캘리포니아 주택 가격 데이터 셋
2.2 큰 그림 보기
캘리포니아의 블록 그룹 마다 인구, 중간 소득, 중간 주택 가격 등을 담고 있다.
- 블록그룹은 미국 인구조사국에서 샘플 데이터를 발표하는데 사용하는 최소한의 지리적 단위이다.
목표는 데이터로 모델을 학습시켜서 다른 측정 데이터가 주어졌을 때 구역의 중간 주택 가격을 예측하는 것이다.
tip : 잘 훈련된 데이턱 과학자로서 해야할 첫번째 할일은 프로젝트 체크리스트를 준비하는 것이다.
*체크리스트
2.2.1 문제 정의
- 비즈니스의 목적을 정확히 정의하는 것이 중요하다.
- 이 모델을 이용하여 어떻게 이익을 얻을 것인지, 문제를 어떻게 구성할지, 어떤 알고리즘을 선택할지, 모델 평가에 어떤 성능 지표를 사용할지, 모델 튜닝을 위해 얼마나 노력할지를 결정.
데이터 처리 "컴포넌트" 들이 연속되어 잇는 것을 파이프 라인 이라고 합니다.
=> 머신 러닝 시스템은 데이터를 조작하고 변환할 일이 많아서 파이프라인을 사용하는 일이 흔하다.
** 컴포넌트의 동작 방법
- 비 동기적으로 동작한다.
- 각 컴포넌트는 많은 데이터를 추출해 처리하고 그 결과를 다른 데이터 저장소로 보낸다.
그러면 일정 시간 후 파이프라인의 다음 컴포넌트가 그 데이터를 추출해 자신의 출력 결과를 만든다.
- 각 컴포넌트는 완전히 독립적이다. 즉, 컴포넌트 사이의 인터페이스는 데이터 저장소 뿐이다.
이는 (데이터 흐름도 덕분에) 시스템을 이해하기 쉽게 만들고, 각 팀은 각자의 컴포넌트에
집중할 수 있다.주의! : 모니터링이 적절히 되지 않으면 고장난 컴포넌트는 한동안 모를 수 있다. => 즉, 데이터가 만들어진지 오래되면 전체 시스템의 성능이 떨어진다.
- 현재 솔루션은 어떻게 구성되어 있는가?
- 만약 있다면 : 문제 해결방법에 대한 정보는 물론이고 참고 성능으로도 사용할 수 있다.
- 문제를 잘 정의해야 한다.
문제가 지도학습,비지도 학습, 강화학습, 배치학습과 온라인 학습 중 어떤 것인지 정의 해야한다.
-
우리가 예를 들고 있는 데이터에는
레이블된 훈련 샘플 값(각 샘플이 기대출력값, 구역의 중간 주택 가격을 가지고 있음)이 있으므로지도학습이다. -
값을 예측해야 하므로 전형적인
회귀문제이며, 예측에 사용될 특성이 여러 개(구역의 인구, 중간 소득 등)이므로다중 회귀문제이다. -
각 구역마다 하나의 값을 예측하므로
단변량 회귀이다.구역마다 여러개의 값을 예측한다면 다변량 회귀 이다.
-
데이터에 연속적인 흐름이 없고, 데이터가 메모리에 들어갈 정도로 충분히 작으므로
일반적인 배치학습이다.
Tip : 데이터가 매우 크면 (맵리듀스 기술을 이용해서) 배치학습을 여러 서버로 분할하거나, 대신 온라인 학습 기법을 사용할 수 있다.
- 맵 리듀스 : 대표적인 프레임워크는 아파치 하둡(Hadoop)이며, 일반적으로 맵 리듀스에서는 스파크(Spark)의 MLlib을 사용하는 것이 편리하고 성능도 뛰어납니다.
2.2.2 성능 측정 지표 선택
- 회귀문제의 전형적인 성능 지표는
RMSE (평균 제곱근 오차)이다.
- 오차가 커질수록 이 값은 더욱 커지므로 예측에 얼마나 많은 오류가 있는지 가늠하게 해준다.
-> 추정 값
- 회귀문제에서의 다른 성능 지표
- 이상치로 보이는 구역이 많다고 할 때MAE (평균 절대 오차)를 고려할 수 있다.
- 거리측정 방법 = norm
- Euclidean norm : RMSE 계산이며 우리와 친숙한 거리 개념이다. 놈이라고도 부르며 (또는 )로 표기한다.
- Manhattan norm : 절대값의 합을 계산하는 것. 놈에 해당하며 로 표기한다.
- 일반적으로 원소가 개인 벡퍼 의 놈은 으로 정한다. 는 단순히 벡터에 있는 0이 아닌 원소의 수이고, 는 벡터에서 가장 큰 절댓값이 됩니다.
- 놈의 지수가 클 수록 큰 값의 원소에 치우치며 작은 값은 무시된다. 그래서 가 보다 조금 더 이상치에 민감하다. 하지만 (종 모양 분포의 양 끝단 처럼) 이상치가 매우 드물면 가 잘 맞아 일반적으로 널리 사용된다.
2.2.3 가정 검사
마지막으로 지금까지 만든 가정을 나열하고 검사해보는 것이 좋다
- 예를 들어
=> 시스템이 출력한 구역의 가격이 다음 머신러닝 시스템의 입력으로 들어가게 되는데 이 값이 그대로 사용될 것이라 가정한다.
=> 하지만, 하위 시스템에서 가격 대신 카테고리를 사용한다면 이 작업은 회귀가 아니라 분류작업이 되므로 앞에서 한 머신러닝 시스템은 소용이 없기 때문에 가정을 필수적으로 검사하여야 한다.
2.3 데이터 가져오기
- 데이터를 가져올 때 간단한 함수를 만들어 사용하면 편하다.
- 데이터를 다운로드 함수를 준비하면 특히 데이터가 정기적으로 바뀌는 경우 유능하다.
- 스케줄링 하여 주기적으로 자동 실행할 수도 있다.
데이터를 다운로드 하는 스크립트
import os
import tarfile
import urllib
DOWNLOAD_ROOT = 'https://raw.githubusercontent.com/ageron/handson-ml2/master/'
HOUSING_PATH = os.path.join('datasets','housing')
HOUSING_URL = DOWNLOAD_ROOT + 'datasets/housing/housing.tgz'
def fetch_housing_data(housing_url = HOUSING_URL , housing_path = HOUSING_PATH):
os.makedirs(housing_path,exist_ok=True) ## 폴더를 만드는 함수
tgz_path = os.path.join(housing_path, 'housing.tgz')
urllib.request.urlretrieve(housing_url, tgz_path)
## tar 아카이브 파일을 압축 해제 하는 법
housing.tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path = housing_path)
housing_tgz.close()# 함수 실행
fetch_housing_data()파일을 읽어들이는 스크립트
import pandas as pd
def load_housing_data(housing_path = HOUSING_PATH):
csv_path = os.path.join(housing_path, 'housing.csv')
return pd.read_csv(csv_path)## 데이터 읽어오기
housing = load_housing_data()2.3.1 데이터 구조 훑어보기
데이터 head()만 불러오기
housing.head()결과
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
데이터의 간략한 설명과 전체 행 수, 각 특성의 데이터 타입과 null이 아닌 값의 갯수를 확인하기
housing.info()결과

- 해석
- total_bedrooms 의 데이터만 Non-Null 의 갯수가 20433개 이다. 즉 total_bedrooms의 데이터에 Null 값이 207개가 있다는 뜻이다.
- ocean_proximity 필드만 빼고 모든 특성이 정수형이다.- ocean_proximity 데이터 타입이 object 이므로 어떤 파이썬 객체도 될 수 있지만, CSV파일에서 읽어 들였기 때문에 텍스트 속성일 것이다.
ocean_proximity 데이터 확인
housing['ocean_proximity'].head()결과

- 해석
- 열의 값이 반복되는 것으로 보아 이 특성은 아마도 범주형일 것이다.
카테고리별 갯수 확인하기
housing['ocean_proximity'].value_counts()결과
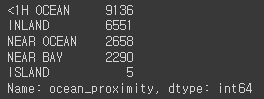
숫자형 특성의 요약정보 확인하기
housing.describe()결과
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20433.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | -119.569704 | 35.631861 | 28.639486 | 2635.763081 | 537.870553 | 1425.476744 | 499.539680 | 3.870671 | 206855.816909 |
| std | 2.003532 | 2.135952 | 12.585558 | 2181.615252 | 421.385070 | 1132.462122 | 382.329753 | 1.899822 | 115395.615874 |
| min | -124.350000 | 32.540000 | 1.000000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 | 0.499900 | 14999.000000 |
| 25% | -121.800000 | 33.930000 | 18.000000 | 1447.750000 | 296.000000 | 787.000000 | 280.000000 | 2.563400 | 119600.000000 |
| 50% | -118.490000 | 34.260000 | 29.000000 | 2127.000000 | 435.000000 | 1166.000000 | 409.000000 | 3.534800 | 179700.000000 |
| 75% | -118.010000 | 37.710000 | 37.000000 | 3148.000000 | 647.000000 | 1725.000000 | 605.000000 | 4.743250 | 264725.000000 |
| max | -114.310000 | 41.950000 | 52.000000 | 39320.000000 | 6445.000000 | 35682.000000 | 6082.000000 | 15.000100 | 500001.000000 |
히스토그램
- 데이터를 가장 빠르게 검토하는 방법은 각 숫자형 특성을 히스토그램으로 그려보는 것이다.
import matplotlib.pyplot as plt
housing.hist(bins= 50 , figsize = (20,15))
plt.show()결과
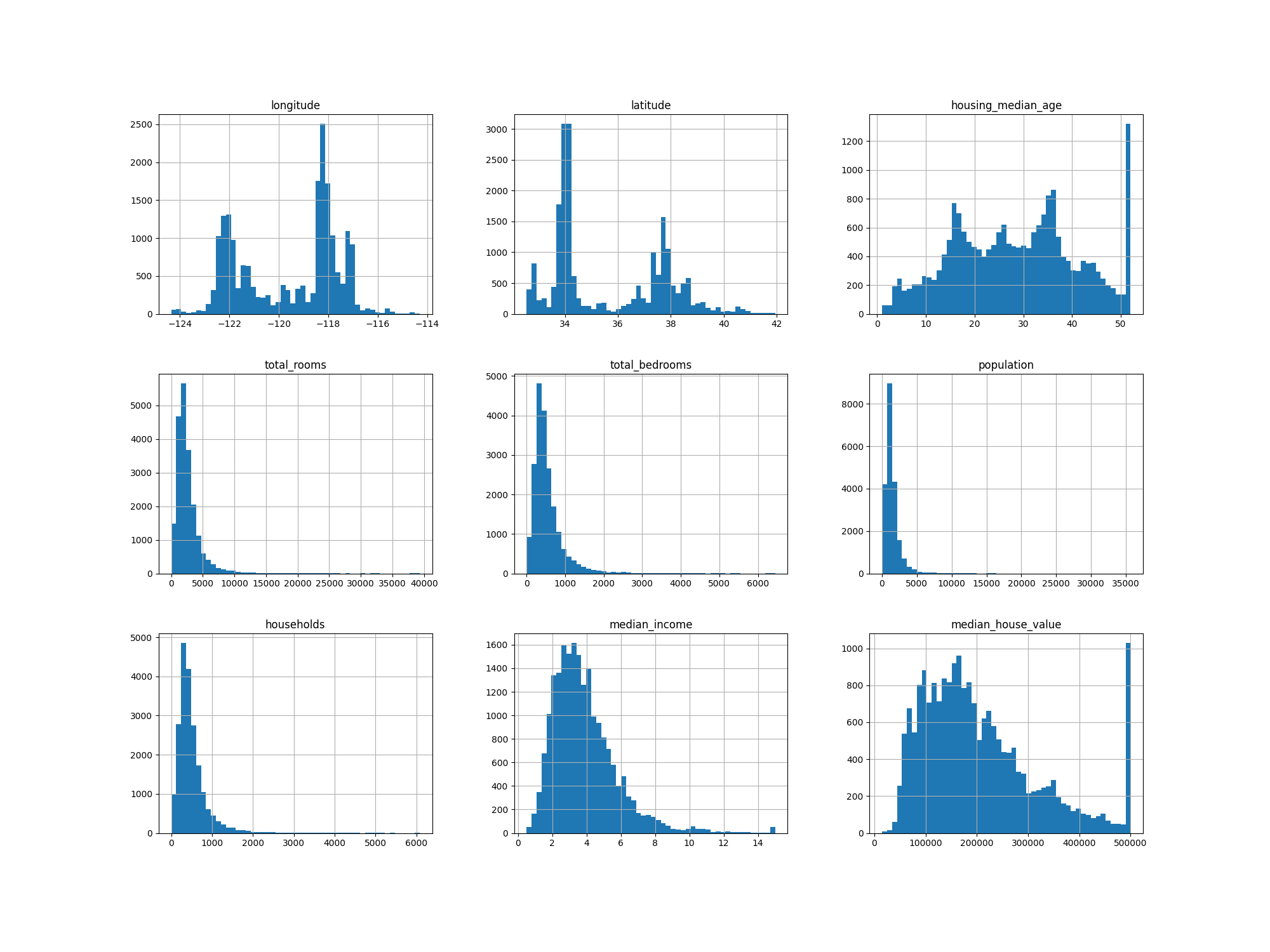
그래프 해석 (세트 분리전 개요 느낌으로)
1) median_incom : 단위 (만 달러) 이며, scale 된 데이터 이다.
2) housing_median_age, median_house_value 는 최대값과 최솟값을 한정하였다.
- median_house_value 는 타깃속성(레이블)으로 사용되었기 때문에 심각한 문제가 된다.
=> 자칫하면 가격이 한곗값을 넘어가지 않도록 머신러닝 알고리즘이 학습될지도 모른다.
- 이때 median_house_value가 $500,000가 넘어가더라도 정확한 예측값이 필요하다면 두가지 방법이 있다.
A. 한계값 밖의 구역에 대한 정확한 레이블을 구한다.
B. 훈련 세트에서 $500,000을 넘어가는 구역을 제거한다. 평가 결과가 매우 나쁠 것이므로 테스트 세트에서도 제거한다.)
3) 스케일들이 서로 다르기 때문에 스케일링이 필요하다.
4) 히스토그램의 꼬리가 두껍다. 이런 분포는 머신러닝이 패턴을 찾기 어렵기 때문에 종 모양의 분포가 되도록 변형시킬 필요가 있다.
(2021.12.16 추가)
2.3.4 테스트 세트 만들기
- 만약 테스트 세트를 들여다본다면 테스트 세트에서 겉으로 드러난 어떤 패턴에 속아 특정 머신러닝 모델을 선택하게 될지도 모른다.
=> 이 테스트 세트로 일반화 오차를 추정하면 매우 낙관적인 추정이 되며 시스템을 론칭했을 때 기대한 성능이 나오지 않을 것이다. 이를데이터 스누핑 (Data Snooping) 편향이라고 한다.
무작위로 어떤 샘플을 서택해서 데이터 셋의 20%정도를 떼어놓는 함수
import numpy as np
def split_train_set(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_inices = shuffled_indices[test_set_size:]
return data.iloc[train_indices],data.iloc[test_indices]- 이 함수 사용 법
train_set , test_set = split_train_test(housing, 0.2)
print('train_set : ', len(train_set) , '\n' 'test_set', len(test_set))결과
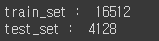
-
위의 코드로 데이터를 분리 했을 때의 문제점
프로그램을 다시 실행하면 다른 테스트 세트가 생성된다. 여러번 계속하면 (머신러닝 알고리즘이) 전체 데이터셋을 보는 셈이므로 이런 상황은 피해야 한다.
해결책
1) 첫 실행에 테스트 세트를 저장하고 다음번에 불러온다.
2) np.random.permutation() 전에 난수발생기의 초기값을 형성한다. (예를 들어 np.random.sedd(42))
- 위의 해결책 또한 또다른 문제점이 존재
다음번에 업데이트 된 데이터 셋을 사용할 때 문제가 된다.
데이터 셋을 업데이트 한 후에도 안정적인 훈련/ 테스트 분할을 위한 일반적인 해결책은
샘플의 식별자를 사용하여 테스트 세트로 버낼지 말지 정하는 것이다.=> 샘플이 고유하고 변경 불가능한 식별자를 가지고 있다고 가정)
- 예를 들어
각 샘플마다 식별자의 해시값을 계산하여 해시 최대값의 20%보다 작거나 같은 샘플만 테스트 세트로 보낼 수 있다. => 이렇게 하면 여러번 반복 실행되면서 데이터 셋이 갱신되더라도 테스트 세트가 동일하게 적용, 새로운 테스트 세트는 새 샘플의 20%를 갖게 되지만 이전에 훈련시킨 샘플은 포함시키지 않을 것이다.
코드
from zlib import crc32
import numpy as np
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_ : test_set_check(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]housing_with_id = housing.reset_index() # 행의 index를 식별자 컬럼으로 사용한다.
train_set , test_set = split_train_test_by_id(housing_with_id, 0.2 , 'index')사이킷런에서 데이터셋을 여러 서브셋으로 나누는 다양한 방법을 제공한다.
코드
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size = 0.2, random_state = 42)- train_test_split 함수의 특징
- random_state 매개변수로 난수 초기값 지정
- 행의 개수가 같은 여러 개의 데이터 셋을 넘겨서 같은 인덱스 기반으로 나눌 수 있다.
(예를 들어 데이터프레임이 레이블에 따라 여러 개로 나뉘어 있을 때 매우 유용하다.)
계층적 샘플링
계층이라는 동일의 그룹으로 나누고 테스트 세트가 모집단을 대표하도록 각 게층에서 올바른 수의 샘플을 추출하는 것
예_) 중간 소득이 중간 주택 가격을 예측하는데 매우 중요한 경우, 테스트 세트가 전체 데이터 셋에 있는 여러 소득 카테고리를 잘 대표해야 한다.
=> 소득에 대한 카테고리 특성을 만드는 것
코드
housing['income_cat'] = pd.cut(housing['median_income'],
bins = [0.,1.5,3.0,4.5,6.,np.inf],
labels = [1,2,3,4,5])
housing['income_cat'].hist()
plt.grid(False) # grid 지우는 함수결과
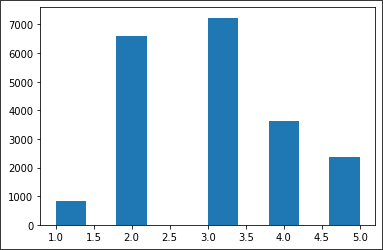
- 주의 : 계층별로 데이터 셋에 충분한 샘플 수가 있어야 한다. 그렇지 않으면 계층의 중요도를 추정하는데 편향이 발생할 것이다.
-> 즉, 너무 많은 계층으로 나누면 안돼고 각 게층이 충분히 커야한다는 것이다.
소득 카테고리를 기반으로 계층 샘플링을 하는 방법 (Stratified ShuffleSplit 사용)
# 소득 카테고리를 기반으로 계층 샘플링
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits = 1, test_size = 0.2, random_state = 42)
for train_index, test_index in split.split(housing, housing['income_cat']):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]## 테스트 세트에서 소득 카테고리의 비율을 확인
strat_test_set['income_cat'].value_counts()/len(strat_test_set)결과

전체 데이터와 계층샘플링, 무작위 샘플링 비교하기
| total_data | hierarchical_data | random_data | diff total, random | dif total, hierarchical | |
|---|---|---|---|---|---|
| 1 | 0.039826 | 0.039971 | 0.040213 | -0.000388 | -0.000145 |
| 2 | 0.318847 | 0.318798 | 0.324370 | -0.005523 | 0.000048 |
| 3 | 0.350581 | 0.350533 | 0.358527 | -0.007946 | 0.000048 |
| 4 | 0.176308 | 0.176357 | 0.167393 | 0.008915 | -0.000048 |
| 5 | 0.114438 | 0.114341 | 0.109496 | 0.004942 | 0.000097 |
- 계층 샘플링으로 만든 테스트 세트가 전체 데이터셋에 있는 소득 카테고리의 비율과 거의 같다. 반면 일반 무작위 샘플리으로 만든 테스트 세트는 비율이 많이 달라졌다.
income_cat 특성을 삭제하여 데이터를 원래상태로 되돌린다.
## income_cat 특성 삭제
for set_ in (strat_train_set, strat_test_set, housing , test_set):
set_.drop('income_cat', axis = 1, inplace = True)21.12.27 일단 오늘 여기까지 그동안 git과 colab을 연결하는 방법을 찾느라 한참 고생해서 결국 못찾아서 다시 공부시작합니다...
