Chapter 1 한눈에 보는 머신 러닝
개요 : 지도학습, 비지도 학습, 온라인 학습과 배치학습, 사레기반 학습, 모델기반학습, 작업 흐름, 주요 문제점, 시스템 평가
1.1 머신러닝 이란?
정의 : 어떤
작업 T에 대한 컴퓨터 프로그램의 성능을P로 측정했을 때경험 E로 인해 성능이 향상됐다면 이 컴퓨터 프로그램은작업 T와성능 P에 대해경험 E로 학습한 것이다.
톰 미첼 , 1997
예)
작업 T : 새로운 메일이 스팸인지 구분하는 작업
경험 E : 훈련데이터
성능측정 P : 직접 정의를 해야하며, 정확히 분류된 메일의 비율 => 정확도라고 한다.
- 훈련 세트 (training sets) : 시스템이 학습하는데 사용하는 샘플
- 훈련사례 or 샘플 (training instance) : 훈련 데이터
1.2 왜 머신러닝을 사용하는가?
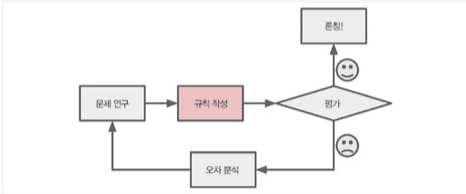
전통적인 프로그램 기법 : 스팸필터
- 문제가 어려울 때 규칙이 점점 길고 복잡해지므로 유지보수가 매우 힘들다
머신러닝
- 스팸에 자주 나타나는 패턴을 감지하여 어떤 단어와 구절이 스팸메일을 판단하는데 좋은 기준인지 자동으로 학습
-> 그러므로 프로그램이 훨씬 짧아지고 유지보수하기 쉬우며 대부분 정확도가 높다.
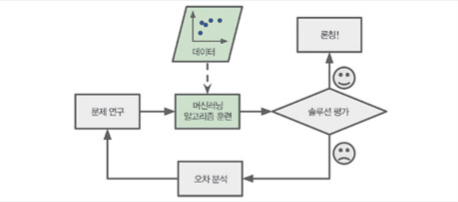
새로운 규칙 or 변수가 생겼을 경우
- 전통적인 프로그램 : 새로운 규칙 or 변수에 맞춰 계속 규칙을 넣어야 한다.
- 머신러닝 프로그램 : 자동으로 학습하며 분류한다.
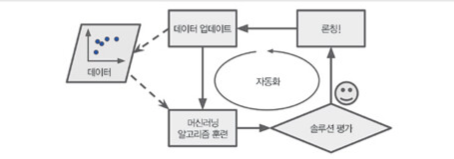
머신러닝의 특징
- 머신러닝 알고리즘을 학습시킬 뿐만 아니라 머신러닝을 통해 배울 수 있다. 즉, 머신러닝 알고리즘이 학습한 것을 조사할 수 있다. (단, 어떤 것은 안된다.)
-> 가끔 예상치 못한 연관관계나 새로운 추세가 발견되기도 해서 해당 문제를 더 잘 이해하도록 도와준다.
즉, 머신러닝 기술을 적용해서 대용량의 데이터를 분석하면 겉으로는 보이지 않던 패턴을 발견할 수 있다.
=> 이를 데이터 마이닝이라고 한다.
머신러닝이 뛰어난 분야
- 기존 솔루션으로는 많은 수동조정과 규칙이 필요한 문제
- 전통적인 방식으로는 해결 방법이 없는 복잡한 문제
- 유동적인 환경
- 복잡한 문제와 대량의 데이터에서 통찰을 얻는 경우
1.3 애플리케이션 사례
* 이미지 분류 작업 : 합성곱 신경망 (CNN)을 사용
* 뇌를 스캔하여 종양 진단하기 : 시맨틱 분할 작업이다. 일반적으로 CNN을 사용해 이미지의 각 픽셀을 분류한다.
* 자동으로 뉴스 기사를 분류 : 자연어처리(NLP) 작업이다. 구체적으론 텍스트 분류이다. 순환신경망(RNN), CNN, 트랜스포머를 사용해 해결할수 있다.
* 토론 포럼에서 부정적인 코멘트를 자동으로 분류 : NLP 작업
* 긴 문서를 자동으로 요약하기 : 텍스트 요약이라 불리는 NLP의 한 분야
* 챗봇 또는 개인 비서 만들기 : 자연어 이해 (NLU) 와 질문-대답 모듈을 포함해 여러가지 NLP 컴포넌트가 필요하다.
* 다양한 성능 지표를 기반으로 회사의 내년도 수익을 예측 : 회귀 작업, 지난 성능 지표의 시퀀스를 고려한다면 RNN, CNN 또는 트랜스포머를 사용할 수 있다.
* 음성 명령에 반응하는 앱을 만들기 : 음성 인식 작업이다. 오디오 샘플을 처리해야한다. 일반적으로 RNN, CNN 또는 트랜스포머를 사용한다.
* 신용카드 부정 거래 감지하기 : 이상치 탐색 작업이다.
* 구매 이력을 기반으로 고객을 나누고 각 집합마다 다른 마케팅 전략을 계획하기 : 군집작업
* 고차원의 복잡한 데이터셋을 명확하고 의미있는 그래프로 표현하기 : 데이터 시각화 작업, 차원 축소 기법을 많이 사용
* 과거 구매 이력을 기반으로 고객이 관심을 가질 수 있는 상품 추천하기 : 추천시스템이다. 이곤 신경망 사용
* 지능형 게임 봇 만들기 : 포통 강화 학습(RL)으로 해결한다.1.4 머신러닝 시스템의 종류
- 사람의 감독하에 훈련하는 여부에 따라
지도, 비지도, 준지도, 강화학습 - 실시간으로 점진적인 학습을 하는지 여부에 따라
온라인 학습, 배치학습 - 단순하게 알고있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 과학자들이 하는 것처럼 훈련 데이터셋에서 패턴을 발견해서 예측 모델을 만드는지
사례기반학습과 모델기반학습
1.4.1 지도학습과 비지도 학습
학습하는 동안의 감독 형태나 정보량에 따라 지도학습, 비지도학습, 준지도학습, 강화학습 등 네가지 주요 범주가 있다.
1) 지도학습
-
지도학습에는 알고리즘에 주입하는 훈련데이터에
레이블이라는 원하는 답이 포함된다.
레이블 : 레이블의 범주를 클래스라고 부른다. -
분류가 전형적인 지도학습
+ ex) 스팸 필터는 많은 메일 샘플과 소속정보 (스팸인지, 아닌지)로 훈련되어야 하며 어떻게 새 메일을 분류할지 학습해야 한다.
-
또다른 지도학습 (회귀)
=> 예측변수라 부르는 특성(주행거리, 연식, 브랜드 등)을 사용해 중고차 각겨 같은 타겟 수치를 예측하는 것.
-> 시스템을 훈련하려면 예측변수와 레이블(중고차 가격)이 포함된 중고차 데이터가 많이 필요하다.
일부 회귀 알고리즘을 분류에 사용할 수 있다. 방대로 일부 분류 알고리즘을 회귀에 사용할 수 있다.
Note_
- 머신러닝에서 속성(attribute)은 데이터 타입을 말한다. ex_) 주행거리
- 특성은 문맥에 따라 다르지만 일반적으로 속성과 값이 합쳐진 것을 의미한다. 데이터의 열 또는 변수를 의미한다.
ex_) 주행거리 = 15000- 지도학습 알고리즘의 종류 (책에서 모두 다룬다.)
- K-nearest neighbors (K-최근접 이웃)
- Linear Regression (선형 회귀)
- Support Vector Machin (SVM, 서포트 벡터 머신)
- Decision Tree, Random Forest
- Neural Networks (신경망)
2) 비지도 학습
훈련데이터에 레이블이 없다. 시스템이 아무 도움없이 학습해야 한다.
- 비지도 학습 알고리즘의 종류 (대부분 다룬다.)
-
Clustering : 각 그룹을 더 작은 그룹으로 세분화 할 수 있다.
- K-means
- DBSCAN
- hierarchical cluster analysis (계층 군집 분석 , HCA)
- outlier detection , novelty detection (특이치 탐색)
novelty dection : 훈련세트에 있는 모든 샘플과 달라보이는 새로운 샘플을 탐지하는 것이 목적 - one-class SVM
- isolation forest
-
Visualiztion :
레이블이 없는 대규모의 고차원 데이터를 넣으면 도식화가 가능한 2D나 3D표현으로 만들어 준다
dimensionality reduction :
너무 많은 정보를 잃지 않으면서 데이터를 간소화 할 수 있다.Tip : (지도 학습 알고리즘 같은) 머신러닝 알고리즘에 데이터를 주입하기 전에 차원 축소 알고리즘을 사용하여 훈련 데이터의 차원을 줄이는 것이 유용할 때가 많다. 실행 속도가 훨씬 빨라지고 디스크와 메모리를 차지하는 공간도 줄고, 경우에 따라 성능이 좋아지기도 한다.- Principal Component Analysis (PCA, 주성분 분석)
- Kernel PCA
- Locally- Linear Embedding (LLE)
- T-SNE
-
association rule learning (연관 규칙 학습)
- Apriori
- Eclat
3) 준 지도 학습
일부만 레이블이 있는 데이터를 다루는 것
데이터에 레이블을 다는 것은 일반적으로 시간과 비용이 많이 들기 때문에 레이블이 없는 샘플이 많고 레이블된 샘플은 적은 경우가 많습니다.
- 대부분의 준 지도 학습 알고리즘은 지도학습과 비지도 학습의 조합으로 이루어져 있다.
- 예를 들어 심층 신뢰 신경망 (deep belief network, DBN) 은 여러 겹으로 쌓은 제한된 볼츠만 머신 (restricted boltzman machin, RBM)이라 불리는 비지도 학습에 기초한다.
=> RBM이 비지도 학습 방식으로 순차적으로 훈련된 다음 전체 시스템이 지도 학습 방식으로 세밀하게 조정된다.
4) 강화학습
- 학습하는 시스템을
에이전트라고 부르며,환경을 관찰해서행동을 실행하고 그 결과로보상(또는 부정적인 보상에 해당하는벌점)을 받습니다.
-> 시간이 지나면서 가장 큰 보상을 얻기 위해정책이라고 부르는 최상의 전략을 스스로 학습합니다.
정책(policy)은 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의한다.1.4.2 배치학습과 온라인 학습
분류하는데 사용하는 다른 기준은 입력 데이터의 스트림(stream)으로 부터 점진적으로 학습할 수 있는지 여부
1) 배치학습
시스템이 점진적으로 학습할 수 없으며, 가용한 데이터를 모두 사용하여 훈련시켜야 한다.
보통 이 방법은 시간과 자원을 많이 소모하므로 보통 오프라인에서 수행한다.
❗ 학습한 것을 단지 적용만 한다. 이를 오프라인 학습이라고 한다.
-
새로운 데이터에 대해 학습하는 법
-> 전체데이터 (기존 데이터 + 새로운 데이터)를 사용하여 새로운 버전을 처음부터 다시 훈련해야한다.
-> 그런다음 시스템을 중지시키고 새 시스템으로 교체한다. -
배치학습은 간단하고 잘 작동하지만 전체 데이터 셋을 사용해 훈련하는데 몇 시간이 소요될 수 있다.
=> 보통 24시간마다 또는 매주 시스템을 훈련시킨다. (빠르게 데이터에 적용해야 할땐 부적합) -
많은 컴퓨팅 자원이 필요하고, 대량의 데이터를 가지고 있는데 매일 처음부터 새로 훈련시키도록 자동화를 할 경우 큰 비용이 발생한다. 또한 데이터의 양이 아주 많을 경우 배치 알고리즘을 사용하는게 불가능 할 수도 있다.
-
자원이 제한된 시스템 (스마트폰 또는 화성탐사로버)이 스스로 학습해야 할때 많은 자원을 사용하면 문제가 발생한다.
⭕ 이럴 경우 점진적인 알고리즘을 사용하는 것이 낫다.
2) 온라인 학습
데이터를 순차적으로 한개씩 또는 미니배치라 부르는 잒은 묶음 단위로 주입하여 시스템을 훈련시킨다.
=> 매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 즉시 학습가능하다.
- 연속적으로 데이터를 받고 빠른 변화에 스스로 적응해야 하는 시스템에 적합
- 컴퓨팅 자원이 제한된 경우 적합
- 새로운 데이터 샘플을 학습하면 학습이 끝난 데이터는 더는 필요하지 않으므로 버리면 된다.
-> 많은 공간을 절약할 수 있다. - 컴퓨터 한 대의 메인 메모리에 들어갈 수 없는 아주 큰 데이터 셋을 학습하는 시스템에도 온라인 학습 알고리즘을 사용할 수 있다. (이를 외부 메모리 학습이라고 한다.)
외부 메모리 학습은 보통 오프라인으로 실행된다 (즉 실시간 시스템에서 수행되는 것이 아니다.) => 점진적 학습이라고 생각해라
<처리과정>
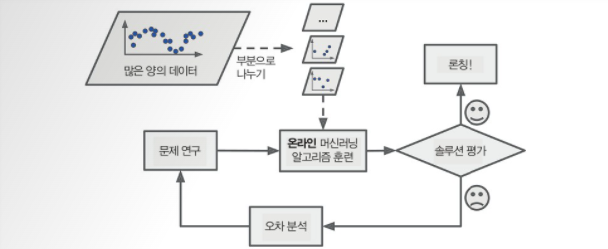
-
학습률 (learning rate) : 변화하는 데이터에 얼마나 빠르게 적응할 것인지
=> 학습률을 높게하면 시스템이 데이터에 빠르게 적응하지만 예전 데이터를 금방 잊어버릴 것이다. 반다로 학습률이 낮으면 시스템의 관성이 더 커져서 더 느리게 학습한다. 하지만 새로운 데이터에 있는 잡음이나 대표성 없는 데이터 포이트에 덜 민감해진다. -
온라인 학습의 가장 큰 문제점
=> 시스템에 나쁜 데이터가 주입되었을 때 시스템 성능이 점진적으로 감소한다는 점이다.
(운영중인 시스템이면 고객이 눈치챌 수 있다.)
Ex_) 로봇의 오작동 센서, 검색엔진을 속여 상위에 노출시키려는 누군가로 부터 나쁜데이터가 올 수 있다.
=> 이를 방지하기 위해 시스템을 면밀히 모니터링하고 성능감소가 감지되면 즉각 학습을 중지시켜야 한다. 혹은
입력 데이터를 모니터링 해서 비정상 데이터를 잡아낼 수 있다.1.4.3 사례 기반 학습과 모델 기반 학습
어떻게 일반화 되는가(좋은 예측을 만드는가)에 따라 분류한다.
- 일반화를 위한 두가지 접근법
- 사례 기반 학습 :
- 시스템이 훈련 샘플을 기억함으로써 학습한다. 유사도 측정을 사용해 새로운 데이터와 학습한 샘플을 (또는 학습한 샘플 중 일부를) 비교하는 식으로 일반화
Ex_) 스팸 메일과 매우 유사한 메일을 구분하도록 스팸 필터를 프로그래밍 하는 경우, 두 메일 사이의 유사도를 측정해야한다. 예를 들면 공통으로 포함되는 단어의 수를 세는 것 - 모델 기반 학습
샘플들의 모델을 만들어 예측에 사용하는 것
- 예를 들어 돈이 사람을 행복하게 만드는지 알아본다고 가정하자
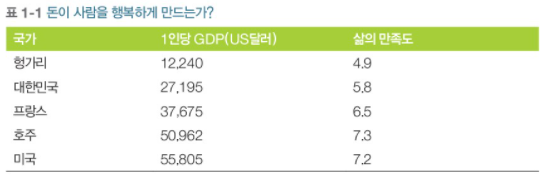
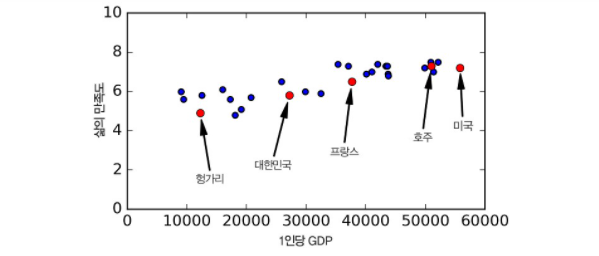
✔ 위의 그래프를 통해 데이터가 흩어져 있지만 (즉, 어느정도 무작위성이 있지만) 삶의 만족도는 국가의 1인당 GDP가 증가할 수록 거의 선형으로 올라간다.
✔ 그러므로 1인당 GDP의 선형 함수로 삶의 만족도를 모델링 한다. => 모델 선택
- 1인당 GDP라는 특성 하나를 가진 삶의 만족도에 대한 선형 모델이다.-> 이 모델은 두개의 모델 파라미터 과 을 가진다.
-> 이 파라미터를 조정하여 어떤 선형 함수를 표현하는 모델을 얻을 수 있다.
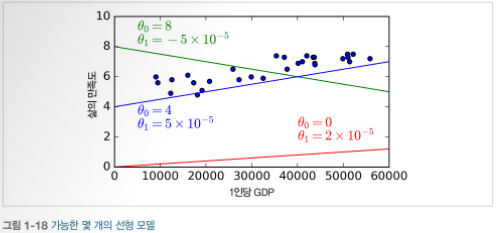
- 측정 지표
- 모델이 얼마나좋은지측정하는효용함수(또는적합도 함수)
- 모델이 얼마나나쁜지측정하는비용함수
선형 회귀에서는 보통 선형 모델의 예측과 훈련 데이터 사이의 거리르 재는 비용 함수를 사용한다. 이 거리를 최소화 하는 것이 목표이다.
모델이라는 단어는모델의 종류나완전히 정의된 모델 구조나 예측에 사용하기 위해 준비된훈련된 최종 모델을 의미 할 수 있다.모델 선택은 모델의 종류나 완전ㄴ히 정의된 모델 구조를 선택하는 것이다.모델 훈련은 훈련 데이터에 가장 잘 맞는 (그리고 새로운 데이터에 좋은 예측을 만드는) 모델 파라미터를 찾기 위해 알고리즘을 실행하는 것을 의미한다.
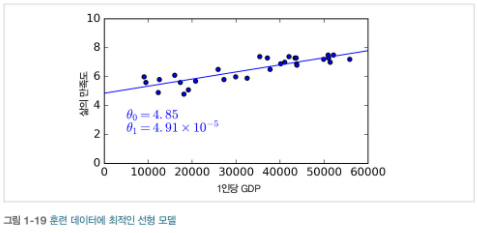
- 이 모델을 사용하여 예측 할 수 있다.
- 예를 들어 OECD 데이터에 없는 키프로스 사람ㄷ르이 얼마나 행복한지 알아보려면
키프로스의 1인당 GDP를 보면 22,587달러 이므로 이를 모델에 적용해과 같이 삶의 만족도를 계산한다.
선형모델 훈련 및 예측 코드
import matplotlib.python as plt
import numpy as np
import pandas as pd
import sklearn.linear_model
# 데이터 적제
oecd_bli = pd.read_csv('oecd_bli_2015.csv', thousands = ',')
gdp_per_capita = pd.read_csv('gdp_per_capita.cav',thousands=',',delimiter ='\t', encoding = 'latin1', na_value = 'n/a')
# 데이터 준비
country_stat = prepare_country_stats(oecd_bli,gdp_per_capita)
X = np.c_[country_stats['GDP per capita']]
y = np.c_[country_stats['Life satisfaction']]
# 데이터 시각화
country_stats.plot(kind='scatter',x='GDP per capita',y = 'Life satisfaction')
plt.show()
# 선형 모델 선택
model = sklearn.linear_model.LinearRegression()
# 모델 훈련
model.fit(X,y)
# 키프로스에 대한 예측 만들기
X_new = [[22587]] # 키프로스 1인당 GDP
print(model.predict(X_new)) ## 결과 [[5.96242338]]-
Note : K-최근접 이웃 회귀
사례 기반의 학습 알고리즘을 사용한다면 먼저 1인당 GDP가 키프로스와 가장 가까운슬로베니아(20,732달러)를 찾습니다. OECD 데이터에 있는 슬로베니아의 삶의 만족도가5.7이므로 키브로스의 삶의 만족도를5.7로 예측합니다. 조금 더 확대해서 그 다음으로 가까운 두 나라를 더 고려하면 삶의 만족도가5.4과6.5인포르투갈과스페인이 있습니다.
이 세 값을 평균하면 모델 기반의 예측과 매우 비슷한5.77이 된다. 이것을K-최근접 이웃이라고 한다. -
k-최근접 이웃 회귀로 바꾸려면 아래 두줄을
import sklearn.linear_model
model = sklearn.linear_model.LinearRegression()다음과 같이 바꾸면 된다.
import sklearn.neighbors
model = sklearn.neighbors.KNeighborsRegressor(n_neighbors = 3)1.4.4 요약
- 데이터를 분석한다.
- 모델을 선택한다.
- 훈련 데이터로 모델을 훈련시킨다ㅏ. (즉, 학습 알고리즘이 비용 함수를 최소화하는 모델 파라미터를 찾는다.)
- 마지막으로 새로운 데이터에 모델을 적용해 예측을 하고 (이를
추론이라고한다.), 이 모델이 잘 일반화 되길 기대한다.
(2021.12.14. 추가)
1.5 머신러닝의 주요 도전 과제
- 머신러닝에서 문제가 될 수 있는 두가지에는
1) 나쁜 알고리즘,2) 나쁜 데이터가 있다.
나쁜 데이터의 사례
1.5.1 충분하지 않은 양의 훈련 데이터
- 아주 간단한 문제에서조차도 수천 개의 데이터가 필요하고 이미지나 음성 인식 같은 복잡한 문제라면 수백만 개가 필요할지도 모른다. (이미 만들어진 모델을 재사용할 수 없다고 한다면)
2001년에 발표한 유명한 논문에서 미셸 반코와 에릭 브릴은 아주 간단한 모델을 포함하여 여러 다른 머신러닝 알고리즘에 충분한 데이터가 주어지면 복잡한 자연어 중의성 해소 문제를 거의 비슷하게 잘 처리한다는 것을 잘 보였다.
-> 이 결과가 제시하는 것은 시간과 돈을 알고리즘 개발에 쓰는 것과 말뭉치 개발에 스는 것 사이의 트레이드오프에 대해 다시 생각해봐야 한다는 것이다.
1.5.2 대표성 없는 훈련 데이터
일반화가 잘 되려면 우리가 일반화하기 원하는 새로운 사례를 훈련 데이터가 잘 대표하는 것이 중요하다.
- 일반화하려는 사례들ㅇ르 대표하는 훈련 세트를 사용하는 것이 매우 중요하지만, 이것은 어렵다.
-> 샘플이 작으면샘플링 잡음 : 우연에 의한 대표성이 없는 데이터가 생기고,샘플링 편향 : 매우 큰 샘플도 표본추출 방식이 잘못되면 대표성을 띄지 못한다.이 생길 수 있다.
1.5.3 낮은 품질의 데이터
훈련 데이터가 에러, 이상치, 잡음(예를 들어 성능이 낮은 측정장치 때문에)으로 가득하다면 머신러닝 시스템이 내재된 패턴을 찾기 어려워 잘 작동하지 않을 것이다.
✔ 즉, 데이터 정제를 자 해야 한다.
- 데이터 정제가 필요한 경우
- 일부 샘플이 이상치라는게 명확하면 간단히 그것들을 무시하거나 수동으로 잘못된 것을 고치는 것이 좋다.
- 일부 샘플에 특성 몇개가 빠져 있다면, 이 특성을 모두 무시할지, 이 샘플을 무시할지, 빠진 값을 채울지 또는 이 특성을 넣은 모델과 제외한 모델을 따로 훈련시킬 것인지를 결정해야 한다.
1.5.4 관련 없는 특성
훈련 데이터에 관련 없는 특성이 적고 관련 있는 특성이 충분해야 시스템이 학습할 수 있을 것이다.
- 특성공학 : 훈련에 사용할 좋은 특성들을 찾는 과정
- 특성 선택 : 가지고 있는 특성 중에서 훈련에 가장 유용한 특성을 선택합니다.
- 특성 추출 : 특성을 결합하여 더 유용한 특성을 만듭니다.
- 새로운 데이터를 수집해 새 특성을 만든다.
나쁜 알고리즘의 사례
1.5.5 훈련 데이터 과대적합
- 과대적합 (over fitting) : 모델이 훈련 데이터에 너무 잘 맞지만 일반성이 떨이지는 경우
❗
과대 적합은 훈련 데이터에 있는 잡음의 양에 비해 모델이 너무 복잡할 때 일어난다.
- 해결방법
1. 파라미터 수가 적은 모델을 선택하거나 (ex_ 고차원 다항모델보다 선형모델 선택),
훈련 데이터에 있는 특성 수를 줄이거나, 모델에 제약을 가하여 단순화 시킨다.
2. 훈련 데이터를 더 많이 모은다.
3. 훈련 데이터의 잡음을 줄인다. (예를 들어 오류 데이터 수정과 이상치 제거)-
규제 : 모델을 단순하게 하고 과대적합의 위험을 감소시키기 위해 모델에 제약을 가하는 것
=>데이터에 완벽히 맞추는 것과일반화를 위해 단순한 모델을 유지하는 것사이의 올바른 균형을 찾는 것이 좋다. -
학습하는 동안 적용할 규제이 양은
하이퍼파라미터가 결정한다. -
하이퍼 파라미터 : 모델이 아닌
학습 알고리즘의 파라미터이다. 그래서 학습 알고리즘으로부터 영향을 받지 않으며, 훈련전에 미리 지정되고, 훈련하는 동안에는 상수로 남아 있는다.
=> 규제 하이퍼파라미터를 매우 큰 값으로 지정하면 거의 평편한 모델을 얻게된다. 그러면 학습알고리즘이 훈련 데이터에 과대적합될 가능성은 거의 없지만 좋은 모델을 찾지 못한다.
따라서 머신러닝 시스템을 구축할 때 하이퍼파라미터 튜닝은 매우 중요한 과정이다
1.5.6 훈련 데이터 과소 적합
모델이 너무 단순해서 데이터의 내제된 구조를 학습하지 못할때 일어난다
- 해결방안
- 모델 파라미터가 더 많은 강력한 모델을 선택한다.
- 학습 알고리즘에 더 좋은 특성을 제공한다. (특성 공학)
- 모델 제약을 줄입니다. (예를 들면 규제 하이퍼파라미터를 감소시킨다.)
1.6 테스트와 검증
모델이 새로운 샘플에 얼마나 잘 일반화될지 알기 위해 훈련데이터를 훈련세트 : 모델을 훈련하는 세트, 테스트 세트 : 모델을 테스트 하는 세트로 나눈다.
- 새로운 샘플에 대한 오류 비율을
일반화 오차 (generalization error, 또는 외부 샘플 오차)라고 하며, 테스트 세트에서 모델을 평가함으로써 이 오차에 대한 추정값을 얻는다.
=> 이 값은 이전에 본 적이 없는 새로운 샘플에에 모델이 얼마난 잘 작동할지 알려준다.
훈련 오차가 낮지만 (즉, 훈련 세트에서 모델의 오차가 적음) 일반화 오차가 높다면 이는 모델이 훈련 데이터에 과대적합되었다는 뜻입니다.
Tip : 보통 데이터의 80%를 훈련에 사용하고 20%는 테스트 용으로 떼놓는다. 하지만 이는 데이터셋 크기에 따라 다르다. 만약 샘플이 천만 개 있다면 1%를 떼놓으면 테스트 세트에 샘플이 100,00개 있다는 의미이므로 아마도 일반화 오차를 추정하는데 충분한 크기일 것이다.
1.6.1 하이퍼파라미터 튜닝과 모델 선택
Q) 과대 적합을 피하기 위해 규제를 적용하려고 한다 이때 하이퍼 파라미터 값을 선택하는 방법은?
=> 해결법
-
holdout validation :
간단하게 훈련 세트의 일부를 떼어내어 여러 후보 모델을 평가하고 가장 좋은 하나를 서택하여 이 새로운 홀드아웃 세트를검증세트(validation set)라고 부른다.
=> 즉 줄어든 훈련세트 에서 다양한 하이퍼파라미터 값을 가진 여러 모델을 훈련한 다음 검증세트에서 가장 높은 성능을 내는 모델을 선택한다.
=> 홀드아웃 검증 과정이 끝나면 이 최선의 모델을 전체훈련세트에서 다시 훈련하여 최종 모델을 만든다. 마지막으로 최종 모델을 테스트 세트에서 평가하여 일반화 오차를 추정한다. -
holdout validation 문제점
- 검증 세트가 너무 작으면 모델이 정확하게 평가되지 않음 즉, 최적이 아닌 모델을 잘못 선택할 수 있다.
- 검증 세트가 너무 크면 남은 훈련 세트가 전체 훈련세트보다 너무 작아진다.
=> 이를 해결하는 한가지 방법은 작은 검증 세트 여러 개를 사용해 반복적인 cross-validation을 수행하는 것
검증 세트마다 나머지 데이터 에서 훈련한 모델을 해당 검증 세트에서 평가하여 나온 모든 모델의 평가를 평균하면 훨씬 정확한 성능을 측정할 수 있다.
단점 : 훈련시간이 검증세트의 개수에 비례하여 늘어난다.
주의) 100개의 하이퍼파라미터 값으로 100개의 다른 모델을 훈련 시키는 방법이 있다. 이때 일반화 오차가 가장 낮은 모델(5% 라 하자)을 만드는 최적의 파라미터를 찾았다고 가정하자, 이제 이 모델을 실제 서비스에 투입하면, 성능이 예상보다 좋지않고 오차를 15%나 만든다.
=> 그 이유는 일반화 오차를 테스트 세트에서 여러번 측정했으므로 모델과 하이퍼파라미터가 테스트 세트에 최적화된 모델을 만들었기 때문이다. 즉, 모델이 새로운 데이터에 잘 작동하지 않을 수 있다.
- 데이터 불일치
어떤 경우에는 쉽게 많은 양의 훈련 데이터를 얻을 수 있지만 이 데이터가 실제 제품에 사용될 데이터를 완벽하게 대표하지 못할 수 있다.
최대한 이 경우를 막기 위해 검증세트와 테스트 세트가 실전에서 기대하는 데이터를 가능한 잘 대표해야 한다는 것이다. 따라서 검증세트와 테스트 세트에 대표 데이터가 배타적으로 포함되어야 한다.
훈련-개발 세트가 한가지 방법이다.
모델을 (훈련-개발 세트가 아닌) 훈련세트에서 훈련한 다음 훈련-개발 세트에서 평가한다.
=> 모델이 잘 작동될 경우 훈련세트에 과대적합이 된 것이 아니고,
=> 모델이 검증세트에서 나쁜 성능을 낸다면 이 문제는 데이터 불일치에서 오는 것이기 때문에, 새롭게 전 처리를 하여 불일치를 해결해야만 하고
=> 모델이 훔련-개발 세트에서 잘 작동하지 않는다면 이는 훈련세트에 과대적합된 것이므로 모델을 규제하거나 더 많은 훈련데이터를 모으거나 훈련 데이터 정제를 시도해야한다.
1996년에 발표한 유명한 논문에서 데이비드 월퍼트는 데이터에 관해 완벽하게 어떤 가정도 하지 않으면 한 모델을 다른 모델보다 선호할 근거가 없음을 보였다. 이를 공짜 점심 없음 (NFL) 이론이라 한다. 어떤 것을 경험하기 전에는 더 잘맞을 거라고 보장할 수 있는 모델은 없으며, 어떤 모델이 최선인지 확실히 아는 유일한 방법은 모든 모델을 평가해보는 것뿐이다. 이것이 불가능하기 때문에 실전에서는 데이터에 관해 타당한 가정을 하고 적잘한 모델 몇 가지만 평가한다.
Chapter 1 THE END!!
