LiDAR Clustering - RANSAC
RANSAC
- 데이터로부터 모델을 추정하는데 유용한 RANSAC 알고리즘을 학습한다.
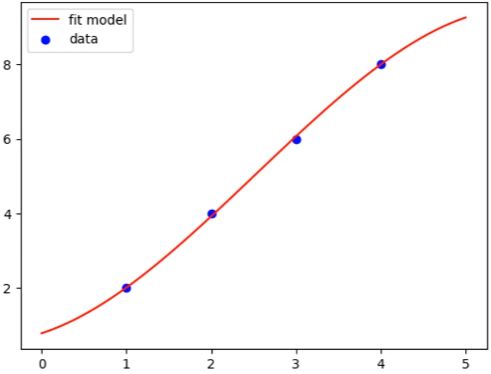
- RANSAC(RANdom SAmple Consensus) 알고리즘은 데이터셋에서 주어진 모델을 추정하는 알고리즘이다.
- 이름에 존재하는 Sample처럼, 주어진 데이터셋에서 임의의 샘플들을 이용해 모델을 추정하고 이를 조정하는 방법을 사용한다.
- RANSAC 알고리즘은 일반적으로 다음과 같은 과정을 따른다.
- 샘플 데이터를 선택하고, 이를 이용해 모델을 추정한다.
- 샘플 데이터 외에 나머지 데이터를 이용해 추정 모델과 일치하는(method) 데이터의 개수를 계산한다.
- 일치하는 데이터의 개수가 일정한 임계치 이상이라면, 이를 최종 추정 모델로 사용한다.
(일정 개수 이상이고 & 직전 최종 값보다 높으면 최종 추정 모델로 갱신한다.)
- 새로운 샘플을 선태가고, 일정 횟수만큼(max_trials)반복한다
- 아래와 같이 임의의 데이터가 존재한다고 하면, 2차원 직선 모델로 하는 RANSAC 알고리즘은 다음과 같이 동작한다.
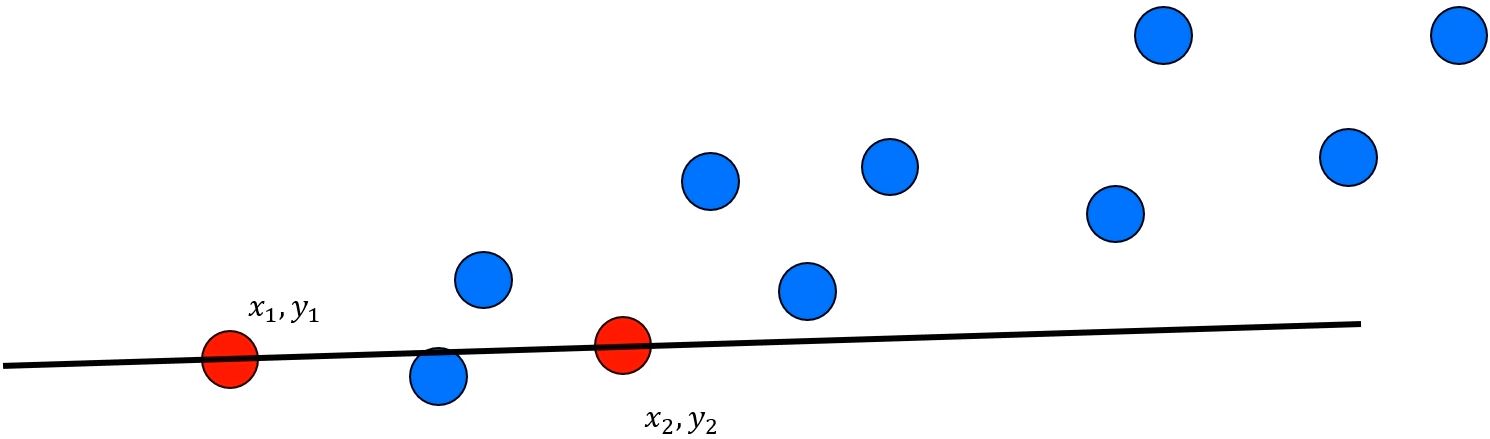
- Step 1. 샘플 데이터를 선택하고, 이를 이용해 모델을 추정한다.
- 두 점을 지나는 직선의 방정식
- y−y1 = x2−x1y2−y1∗(x−x1)
- 일반적으로 모델을 추정하기 위한 최소한의 변수를 min_samples로 한다.
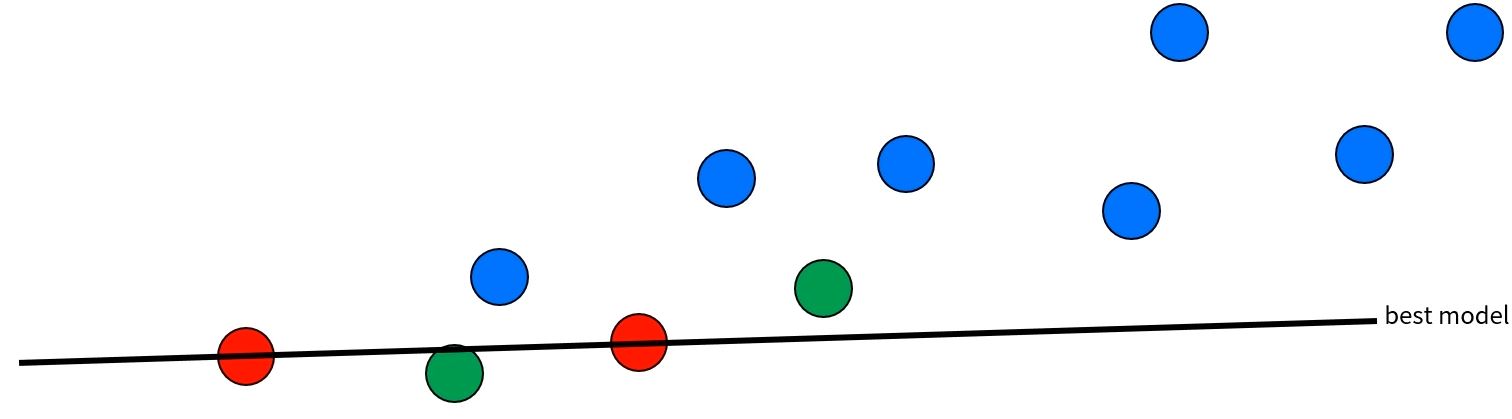
- Step 2. 샘플 데이터외에 나머지 데이터를 이용해 추정 모델과 일치하는(method) 데이터의 개수를 계산한다.
- method: 점과 직선 사이의 거리
- threshold: 일치함을 판단하는 특정 값
- 임의의 점 (x1,y1)과 직선 (ax+by+c=0)사이의 거리 -> d
- d = a2+b2∣ax1+by1+c∣ <= threshold
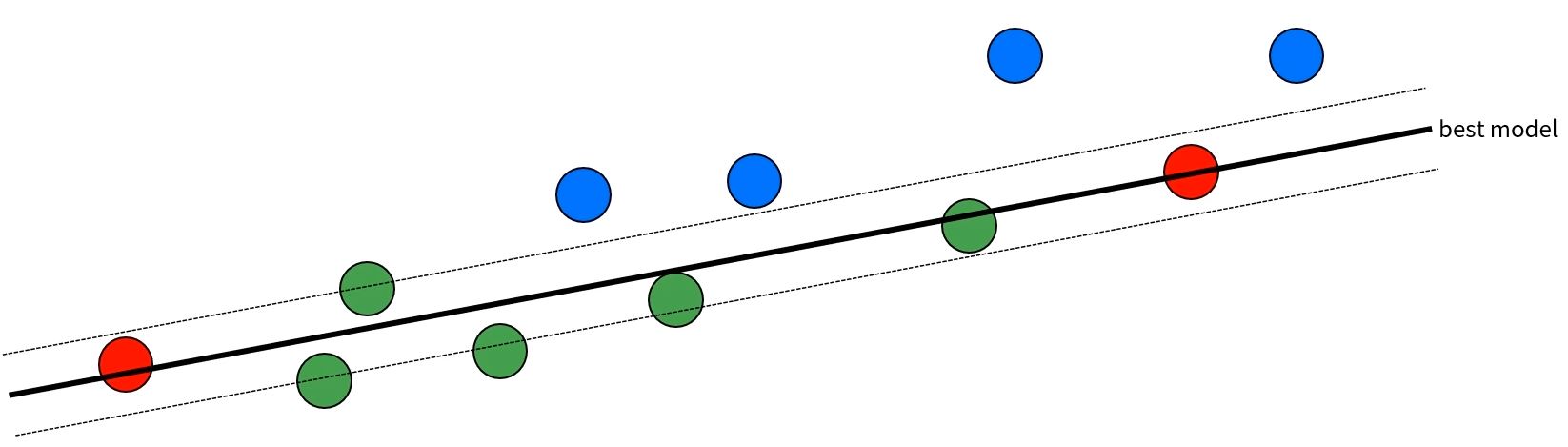
- Step 3. 일치하는 데이터의 개수가 일정한 임계치 이상이라면, 이를 최종 추정 모델로 사용한다.
- Step 4. 새로운 샘플을 선택하고, 일정 횟수만큼(max_trials)반복한다.
- 반복 과정에서 [step 3] 직전 최종 추정 모델보다 일치하는 데이터의 개수가 많으므로, 최종 추정 모델을 갱신한다.
- RANSAC Pseudo-Code

- RANSAC 알고리즘은 다음과 같은 장/단점이 있다.
- 장점:
- 예외(Outlier)를 효과적으로 제거할 수 있다.
- 구현 난이도가 낮고, 다양한 모델에 대해 적용이 가능하다.
- 단점:
- Sampling 결과에 따라 비효율적인 결과를 나타낼 수 있다.
- Prior Sampling을 사용하지 않기 때문에, 매 회 처음부터 다시 시작한다.
- 개선 포인트:
- max_trials을 고정하지 않고 조기에 종료할 수 있는 방법이 없을까?
- 정해진 횟수만큼 반복을 하는데 조건을 잘 만들어서 early stop할 수 있게 만들기
- Sampling 결과를 제한할 수 있는 방법이 없을까 ?
- sampling을 완전한 랜덤으로 하기 보다는 추가적인 정보를 사용해서 범위를 제한한다.
- 1번 sampling만 해도 굉장히 좋은 결과가 나올 수 있게 만들기(boundary를 제한을 하고 충분히 모델이 잘 맞다 라는 베스트 컨디션 조건을 찾아냄)
- e.g) 5회 수행해서 best model을 찾아냄
- best 모델을 boundary로 하는 특정한 영역을 생성해서 outlier를 미리 제거해서 sampling을 제외하는 방법..
