CVPR 2022.
Robin Rombach, Andreas Blattmann, Dominik Lorenz et al,.
Heidelberg University
20 Dec 2021
💡 Key Point
기존의 pixel 공간에서 고비용으로 돌리던 Diffusion을 오토인코더 latent 공간으로 옮겨서, 이미지 합성을 저비용+유연하게 만드는 방법을 제안한 논문
1. Pixel-Space Diffusion vs Latent Diffusion Model (LDM)
| 구분 | Pixel-Space Diffusion | Latent Diffusion Model |
|---|---|---|
| 동작 Space | - 이미지 pixel space에서 직접 noise 추가/제거 - 모든 픽셀을 반복 업데이트 → 공간 차원 매우 큼 | - 오토인코더로 압축된 latent space에서 noise 추가/제거 - perceptual 중요하지 않은 고주파 정보 제거 후 diffusion 수행 - 더 의미 있는 representation 공간에서 학습 |
| 계산 비용 | - 해상도 증가할수록 연산량 급증 - 고해상도 학습·샘플링 시 수백 GPU 필요 | - latent space는 pixel space보다 훨씬 작음 - 연산량 대폭 감소 → 고해상도 처리 시 GPU 부담 감소 |
| 처리하는 정보 | - pixel likelihood 기반: 모든 서브 픽셀 분포 학습 - 고주파 noise까지 학습 → 비효율적 & semantic 집중 어려움 | - 고주파 요소는 오토인코더가 처리 - diffusion은 semantic 내용·구조·구성에 집중 - 정보 밀도 높은 공간에서 학습 |
| 학습/샘플링 속도 | - timestep마다 full-resolution U-Net forward/backward 수행 - 샘플링도 full resolution 반복 → 매우 느림 | - latent resolution이 작아 학습 훨씬 빠름 - diffusion 후 decoder 한 번만 통과 → 속도 향상 |
| 확장성 | - perceptual compression 단계 없음 - semantic + noise를 동시에 처리 - 두 단계 모델링이 분리되지 않음 | - 압축(perceptual)과 생성(semantic) 분리 - 2D Conv U-Net 구조 유지하며 latent feature map 위에서 diffusion 수행 |
| Condition 유연성 | - 텍스트, 레이아웃 등 condition 추가 시 복잡한 구조 필요 - 확장성 낮음 | - Cross-Attention을 U-Net에 삽입해 다양한 condition 통합 가능 - 텍스트·레이아웃·저해상도 이미지 등을 동일 방식으로 처리 - 하나의 프레임워크에서 통합적 확장 가능 |
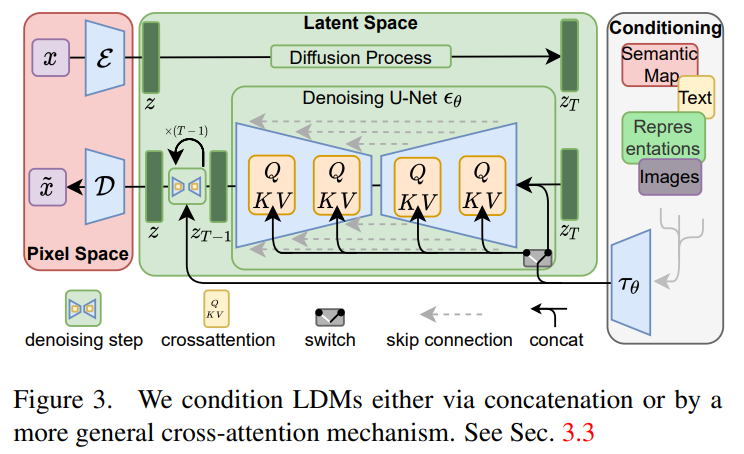
2. LDM’s Mechanism(3-Step)
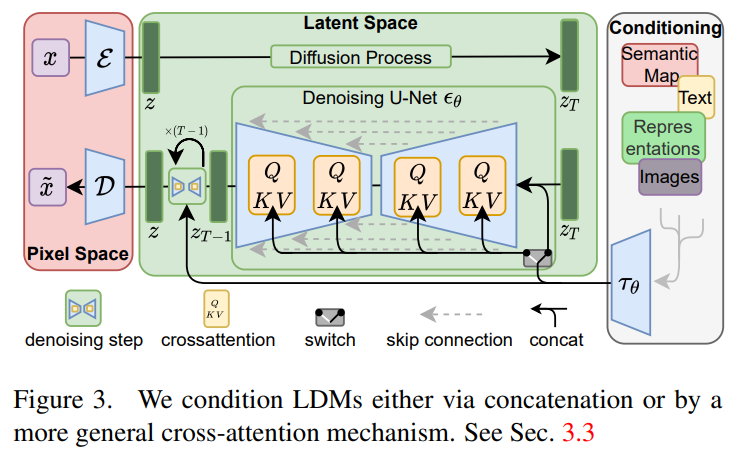
1. Perceptual 오토인코더로 이미지 → Latent 공간 압축
- 이미지 x를 Encoder E가 downsampling factor f= 4로 줄인 latent z로 변환 → (h × w × c) 형태의 압축된 표현 생성
- Encoder는 perceptual loss + patch-based discriminator로 훈련되어 사람이 거의 인지하지 못하는 고주파,저가치 정보 제거
- Decoder D는 latent → 이미지 재구성 x̄ = D(E(x))
- 즉, 시각적으로 중요한 정보만 남긴 latent 공간을 만드는 과정 → diffusion이 semantic 중심으로 학습할 수 있는 공간 생성
2. Latent 공간에서 Diffusion 수행 (Noise 예측 모델: UNet)
- 기존 DDPM/ADM과 동일한 방식의 likelihood 기반 diffusion 과정을 latent에서 수행
- UNet 가 노이즈 ϵ을 예측하는 형태의 loss로 학습
- Pixel-space diffusion과 동일하지만, latent 공간이 작아서 연산량 대폭 감소
- Diffusion은 오토인코더가 정리한 후 남아 있는 의미적 정보를 중심으로 학습
3. Cross-Attention 기반으로 condition 결합
- Condition 입력 y(텍스트, segmentation map, layout, low-res 이미지 등)를 별도 전용 encoder τθ(y)로 임베딩
- UNet 내부 여러 블록의 feature에 cross-attention 형태로 주입
-
Query: U-Net feature
-
Key/Value: condition 임베딩
-
- 이 구조 하나로 text-to-image / layout-to-image / super-resolution 같은 다양한 조합을 모두 처리
- Stable Diffusion도 이 구조를 활용 → 하나의 diffusion backbone으로 모든 조건부 합성 문제 처리
3. Experiment Analysis
1. Downsampling Factor f 의 최적 값은?
- 설정: f ∈ {1, 2, 4, 8, 16, 32}의 성능을 비교 (f=1: pixel diffusion, 나머지 조건 동일)
- f가 작을 때 (LDM-1,2): 학습 진행 속도가 매우 느림, 연산량 낭비
- f가 클 때 (LDM-32): 오토인코더 단계에서 정보 손실 → FID의 정체, 품질의 한계
- f가 적정 값일 때 (LDM-4,8): 빠른 학습 + 안정적인 FID
2. Sampling 속도 & 성능 비교
- Sampling steps {10, 20, 50, 100, 200}에서 LDM-4 / LDM-8:
-
적은 sampling step에서도 높은 FID 성능 유지
-
Pixel DM보다 수배 빠른 sampling 가능
⇒ 고품질 이미지를 훨씬 적은 sampling step으로 생성 가능
-
- Unconditional generation 성능 비교
-
CelebA-HQ: 기존 likelihood 모델/많은 GAN들보다 우수
-
여러 데이터셋에서 Precision/Recall이 좋게 나오며 mode-covering 특성이 보존됨
⇒ latent space에서 processing해도 품질이 떨어지지 않음 → 연산량를 줄이면서도 SOTA급 성능을 낼 수 있음
-
3. 다양한 Condition의 적용이 잘 이루어지는가?
- Text-to-Image
- COCO val에서 AR 기반 DALL-E, CogView, GAN 기반 Lafite보다 FID, IS 측면에서 우수
- classifier-free guidance를 적용하면 품질 더 크게 향상
- Layout-to-Image
- semantic map을 조건으로 하는 landscape synthesis 등에서 잘 작동
- High-Resolution
- semantic synthesis 모델을 256²로 학습→ 512×1024 같은 메가픽셀급 이미지도 convolutional 방식으로 합성 가능
- high-res, conditional 이미지 편집/생성에 공통적으로 쓸 수 있는 backbone
4. Significance of Paper
1. Diffusion 모델의 전반적인 오버헤드를 해결한 방법
- Diffusion 수행 과정을 pixel 공간에서 → latent 공간으로 변경
- 차원 축소를 통해 연산량이 대폭 감소
- 기존 diffusion 모델이 필요로 하는 100~1000 GPU-days를 대폭 절감
- 학습 속도 및 추론 속도를 크게 향상
- pixel 기반 모델 대비 약 3배 이상 빠른 training
- pixel 기반 모델 대비 수십 배 빠른 샘플링
2. 최적화된 압축/생성이 분리된 구조를 구축
- LDM은 압축 과정을 두 단계로 분리해 기존 diffusion 모델의 비효율을 해결
-
Perceptual Compression: 오토인코더에서 불필요한 디테일을 제거
-
Semantic Compression: LDM이 수행, 저차원 공간 = 연산량 절감 + 효율 증가
⇒ 더 빠르고 + 가볍고 + 고해상도로 확장이 가능하고 + 품질 보존이 가능해짐
-
- VQ-VAE와 달리 너무 큰 다운샘플링을 적용하지 않고, 적당한 압축 지점(f=4,8)을 채택해 trade off 상에서 디테일과 효율의 최적점을 발견
- 이후 Stable Diffusion으로 이어지는 텍스트 기반 conditional LDM의 시발점
3. Conditioning 매커니즘을 성공적으로 적용한 사례
- 기존 diffusion 모델은 condition을 추가하려면 복잡한 중간 구조나 별도 모델이 필요
- LDM은 U-Net 내부에 cross-attention 기법으로 condition을 적용시킨 것 → 다양한 모달리티를 같이 활용한 확장성 높은 diffusion 모델을 구축하는데 성공함
- 오늘날 Text-to-Image, Inpainting, Semantic Synthesis 같은 Stable Diffusion 계열의 모든 제어 가능한 기능의 근본 구조를 확립
5. Questions
1. Prior 모델의 downsampling factor f 값 세팅에 대한 의문점 (DALL-E, VQGAN)
- Figrue 1을 보던 중, DALL-E와 VQGAN 모델은 다운샘플링 비율 f를 8,16처럼 높게 세팅한 부분을 발견했다.
- 논문을 읽으면서 f값은 trade-off 구조를 따르는 것을 발견했고, 그래서 적절한 f값을 찾는 것은 꽤 중요한 과정이라고 생각했다.
- f가 낮으면? → 압축률이 낮아 정보 손실은 낮지만, 연산량에서 개선이 적음
- f가 높으면? → 압축률이 높아 연산량은 낮아지지만, 정보 손실률이 큼
- 이전 모델에서는, f=8, 16처럼 높은 값을 채택해 모델을 훈련했고, 그렇다면 정보 손실률이 커 모델의 퀄리티가 비교적 낮았을 거라 생각했다. 이전 모델들도 LDM 논문처럼 여러 시행착오(실험)들을 겪으면서 최적의 f=4값을 찾아낼 수 있지 않았을까? 라는 생각을 했지만 그럼에도 높은 값을 채택한 이유에는 1) 훈련 오버헤드가 줄어드니까, 가볍고 빠른 모델에 집중, 2) 이전의 아키텍처에서는 저압축 구조의 부담이 커서? 정도로 이해했다.
2. Latent Space의 정규화 기법
- LDM 논문에서는, latent space가 비정상적으로 넓어지는 것을 방지하기 위해 두 가지 정규화 기법을 적용한다.
- KL-regularization: VAE에서 사용하는 것 처럼, 잠재 z가 표준 정규분포에 가깝도록 작은 KL Penalty를 부여
- VQ-reqularization: Vector Quantization 레이어를 인코더 쪽이 아닌(VQGAN과 달리) 디코더 내부에 삽입한 것
- 여기서 이 두 정규화 개념이 생소해서 조금 어렵게 느껴졌다. 즉, KL은 연속적이지만 살짝 정규화된 latent 공간을 만드는데 필요한 요소라고 생각했고, VQ는 약간의 양자화를 통해 더 부드러운 latent를 만드는데 필요한 요소 정도라고 이해했다.
- 또한 Vector Quantization이라는 개념을 처음 접해 학습을 조금 해 보았고, ‘계속 변하는 벡터 대신, 정해진 몇개의 대표 벡터 중에서 하나를 선택하는 것’ 정도로 이해했다. 이 기법을 사용하는 이유는, 1) latent 공간을 더 안정적이고 구조적으로 정돈하기 위해서, 2) 대표 벡터로 끊어주기 때문에 diffusion 모델이 학습하기 쉽기 때문이라고 이해한 뒤, LDM의 압축 과정을 읽어 나갔다.
6. Future Directions
1. Conditioning 매커니즘에서 도메인 인코더를 개선할 수 있을까?
1.1. 기존 텍스트 인코더의 구조(‘4.3.1 Transformer Encoders for LDMs’)
- “We employ the BERT-tokenizer [14] and implement τθ as a transformer [94] to infer a latent code which is mapped into the UNet via cross-attention.”
- 즉 LDM의 텍스트 인코더(τθ) = BERT 토크나이저 + 자체 학습 Transformer encoder
1.2. 이 구조의 한계점?
- 이미지와 함께 Joint로 학습되는 조건 인코더이기 때문에, 대규모로 pre-trained 된 언어 모델보다 복잡한 문장 구조, 디테일한 표현 등을 상대적으로 잘 이해하지 못할 가능성이 존재
1.3. 개선할 수 있는 Point
- 기존 텍스트 인코더 대신, 최신 pre-trained 된 텍스트 인코더를 적용해 UNet을 재학습
- BLIP-2, SigLIP 같은 모델을 사용해 텍트스를 임베딩 해보는 것. U-Net cross-attention의 K,V로 사용. 나머지 diffusion 구조는 유지
1.4. Pros & Cons
- Pros: 기존 구조를 크게 변경하지 않고 인코더를 교체하는 식으로 실험이 가능하다
- Cons: 조금 단순한 아이디어, 이미 학계에서 연구가 많이 되었을 수도 있을 것이라는 생각
2. 오토인코더의 학습 과정을 개선해 Latent의 품질을 올릴 수 있을까?
2.1. 기존 LDM의 오토인코더 구조(’3.1. Perceptual Image Compression’)
- ”consists of an autoencoder trained by combination of a perceptual loss [102] and a patch-based [32] adversarial objective [20, 23, 99].”
- 즉, perceptual loss + patch-based adversarial loss 구조로 학습해 원본 이미지와 지각적으로 유사한 재구성이 가능하도록 설계함
2.2. 이 구조의 한계점?
- 이러한 loss 구조는 질감과 현실감 있는 디테일을 재구성하는데에는 강할 수 있으나, 객체의 경계나 의미적 일관성과 같은 시멘틱한 정보까지 반영하기 어려울 수 있음
- 즉, 시각적 유사성은 잘 보존할 수 있지만, ‘의미적 유사성’의 보존 관점에서는 조금 떨어질 수 있음
2.3. 개선할 수 있는 Point
- 오토인코더 학습 과정에 시멘틱 정보를 보존하도록 하는 추가적인 Semantic Loss를 추가해 latent 공간 자체를 더 의미적으로 풍부한 표현으로 만들자
- 생각해본 Semantic Loss: 원본 이미지와 복원 이미지의 CLIP embedding을 가깝게 만드는 방식과 기존 Segmentation 모델(SAM 등)에서 사용하는 Segmentation Loss 정도를 생각해봤습니다.
2.4. Pros & Cons
- Pros: 더 구조적으로 안정된 분포를 학습, 모델 구조와 f=4/8을 변경하지 않고도 LDM의 품질 향상시킬 수 있을 것 같다.
- Cons: 추가 네트워크가 필요해서 모델이 무거워질 수 있음, loss가 많아지므로 학습 과정이 불안정해질 수 있을 가능성
※ 논문 p.4의 간략한 수식 이해

7. Feedback
1️⃣ Downsampling factor f에 대한 질문
Prior 모델에서 높은 downsampling factor(f=8,16)를 사용한 이유에 대한 질문에 대해서는, 내가 예상했던 방향이 크게 틀리지 않았다고 말씀해주셨다.
결국 f는 명확한 trade-off 구조를 가지며, 연산량 감소, 훈련 오버헤드 완화, 모델 경량화 같은 현실적인 이유들이 주요 고려 사항이었을 가능성이 높다는 점을 다시 확인하였다.
즉, 단순히 “최적의 f를 몰라서 높은 값을 쓴 것”이라기보다는 당시의 아키텍처 구조와 계산 자원 제약 속에서 합리적인 선택이었을 가능성이 크다고 이해하게 되었다.
2️⃣ AutoEncoder와 Semantic Loss 아이디어에 대한 피드백
오토인코더의 학습 과정에 semantic loss를 추가해 latent의 의미적 품질을 높이자는 아이디어에 대해, segmentation mask 등을 활용해 diffusion 모델의 spatial 특성을 가이드하는 연구는 이미 많이 존재한다고 말씀해주셨다.
다만 중요한 포인트는,대부분의 연구는 AutoEncoder를 직접 수정하기보다는 latent diffusion 단계에서 가이드를 주는 방향을 채택한다는 점이었다.
즉, AutoEncoder의 역할은 diffusion의 연산 오버헤드를 줄이기 위해 image를 latent로 매핑해주는 연결 고리의 성격이 강하며, semantic한 제어는 diffusion 단계에서 수행하는 것이 일반적이라는 점을 다시 생각하게 되었다.
이 부분에서 내가 처음에는 “latent 자체를 더 의미적으로 풍부하게 만들면 diffusion이 더 좋아지지 않을까?”라고 접근했지만, 실제 연구 흐름에서는 diffusion 쪽을 조정하는 방향이 더 효율적이라는 점을 알게 되었다.
