CVPR 2025.
Zhendong Wang, Jianmin Bao, Shuyang Gu, Dong Chen, Wengang Zhou, Houqiang Li
University of Science and Technology of China (USTC) | Microsoft Research Asia
3 Mar 2025
💡 Key Point
‘디자인 이미지’ 생성에서, 시각적으로 렌더링되는 텍스트의 정확성을 보장하면서, 전체 이미지의 스타일과 레이아웃 일관성을 유지하는 것이 가능할까?
1. Motivation
※ ‘디자인 이미지’ 생성 Task란?
→ 텍스트 설명으로부터 정확한 시각적 텍스트와 일관된 스타일,색감,구성을 갖는 디자인 이미지 (포스터, 로고, 광고 등)를 생성하는 작업
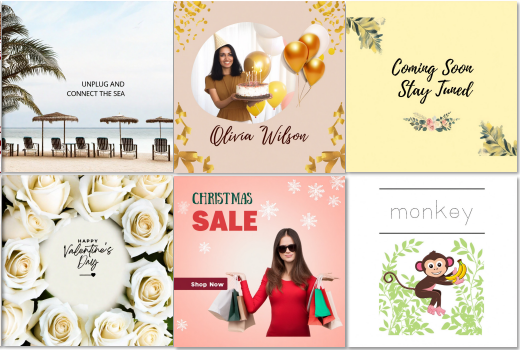
<기존 연구와 한계점>
기존 연구들은 공통적으로 텍스트와 이미지를 분리된 요소로 취급했기 때문에, 여러 한계를 가졌음
1) 기존 연구: 텍스트와 이미지를 분리해서 생성하는 접근법 (Two-stage 방식)
- 텍스트를 미리 정해진 영역에만 생성 → 자유도, 창의성 제한
- 이미지 생성 후, 텍스트를 후처리로 추가 → 텍스트의 공간 부재, 시각적 충돌
- 이미지와 텍스트의 스타일이 일치하지 않는 현상 발생
2) 대안 연구: 레이아웃 및 텍스트 영역을 사전에 정의하는 방식
- 프롬프트로 레이아웃, 텍스트 영역을 미리 학습하는 방식
- 고정된 레이아웃에 의존 → 자유도가 떨어지며 시각적으로 매력성,일관성이 떨어짐
⇒ 기존 연구들은 텍스트와 이미지를 end-to-end로 함께 생성하지 못하고, 정확한 텍스트 삽입과 시각적
조화를 동시에 달성하지 못하는 상태
2. Insight
1) 이미지 내 텍스트의 불안정성은 ‘단어 단위’ 토큰화에서 비롯된다
- 시각적으로 렌더링되는 텍스트는 글자(문자) 단위로 정확해야하는 것이 매우 중요
- 기존 모델은? 텍스트(이미지에 삽입될) 토큰화 과정에서 대부분의 단어를 ‘단일’ 토큰으로 처리하는 방 → 일부 문자가 무시될 수 있고 문자 왜곡이 쉽게 발생함
⇒ 문자(letter)단위로 임베딩하는 방식이라면, 정확한 시각적 텍스트 렌더링이 가능해질 것이다
2) 디자인 이미지에 적합한 새로운 Loss와 Fine-tuning이 필요하다
- 디자인 이미지의 텍스트는 스타일, 크기, 레이아웃이 다양해 시각적 텍스트 모델링의 복잡성을 증가시킴
- 통찰 1: 훈련 중에 각 문자 토큰이 실제로 해당 문자가 그려진 위치에만 집중하도록 지도하자
- 통찰 2: 사람이 만든 진짜 디자인 이미지와는 가깝게, 샘플에서 품질이 낮은 이미지와는 멀게 유도하자
⇒ 디자인 이미지 특성에 맞는 loss 설계와 fine-tuning으로 정확하고 고품질의 결과를 만들 수 있다
3) 텍스트와 이미지는 end-to-end & one-stage로 함께 생성할 수 있다
- 기존 방식은 텍스트 생성과 이미지 생성을 분리된 단계로 처리한다
- 텍스트를 후처리로 삽입하거나
- 사람이 레이아웃을 미리 정의하는 방식
- 하지만 디자인 이미지는 ‘텍스트와 이미지가 동시에 구성되는’ 하나의 결과물로써 제공되는 것이 목표
⇒ 텍스트를 이미지 생성 과정 내부에서 함께 생성해야 시각적 조화를 자연스럽게 유지할 수 있다
3. Method
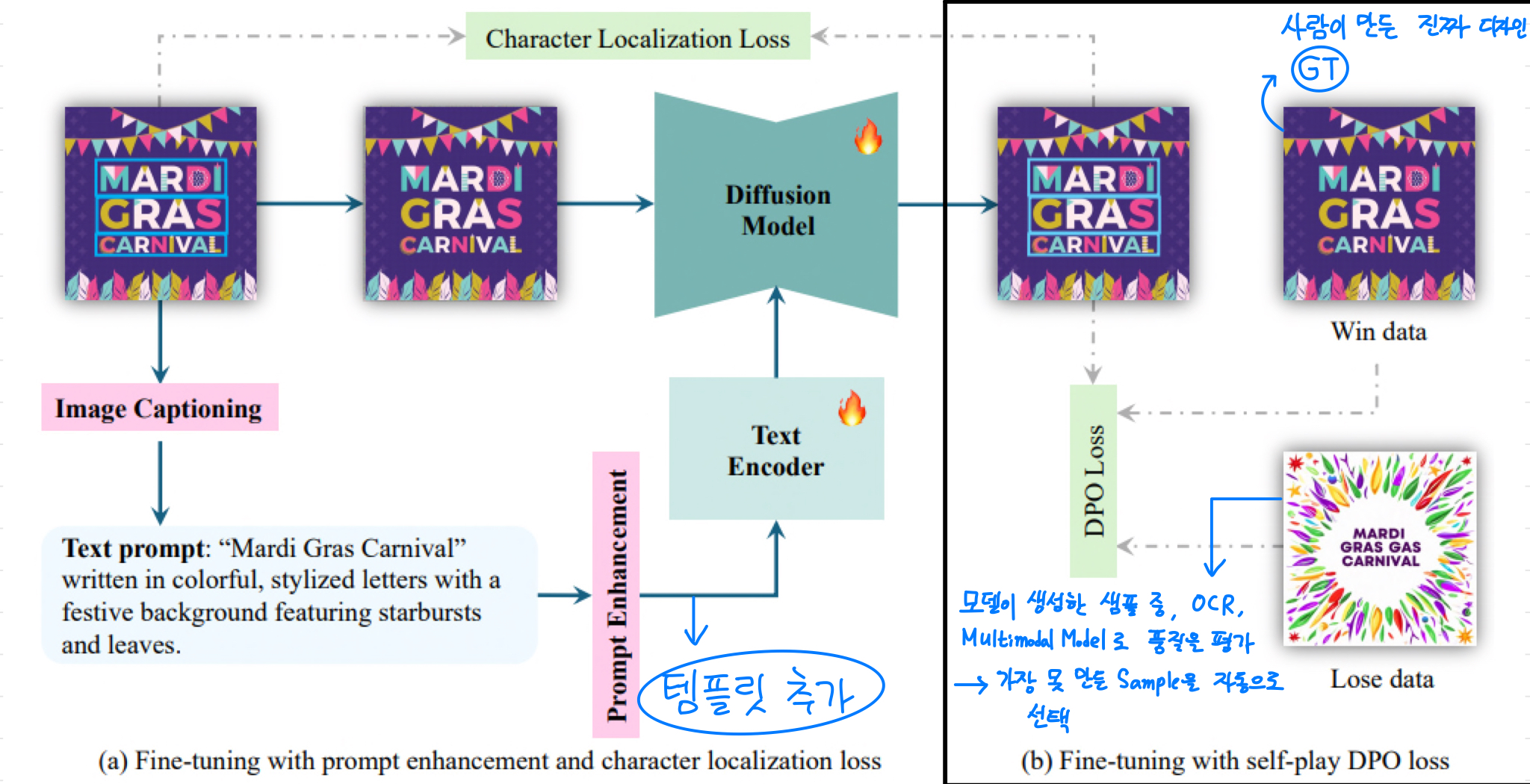
1) 정확한 텍스트 인코딩을 위한 ‘프롬프트 템플릿 추가’
- 발단: 기존의 텍스트 토큰화 방식은 ‘단어’를 단일 토큰으로 처리해 일부 문자가 생략되고 왜곡되었음
- 아이디어: CLIP 텍스트 인코더에 문자 단위 토큰을 병렬로 추가하자
- CLIP 텍스트 인코더의 입력 프롬프트에 특수한 템플릿을 적용하는 것
- 템플릿: “Rendered characters: <|startofchar|> · · · <|endofchar|>”
- Ex) “Mardi” → “<|startofchar|> <|M|> <|a|> <|r|> <|d|> <|i|><|endofchar|>” (‘ | ’로 감싸진 문자는 새로 도입된 학습 가능한 토큰)
- 이 증강된 프롬프트는 UNet이 미리 정의된 레이아웃에 의존하지 않고 이미지에 텍스트를 원활하게 통합할 수 있도록 함
⇒ 텍스트와 이미지를 분리된 단계로 처리하던 방식에서 벗어나, 하나의 생성 과정으로 통합함
2) 문자 분할 마스크를 이용한 Cross-Attention Map 지역화
-
발단: 디자인 이미지 내 텍스트는 스타일, 크기, 색상이 다양하여 텍스트 모델링의 복잡성이 높았음
-
아이디어: 각 문자 토큰이 이미지 내에서 자기 문자에 해당하는 위치만 집중하도록 지도하자
- Cross-Attention 맵은 어떤 이미지 위치가 어떤 텍스트 토큰을 참고하는지를 결정
- = cross-attention map / = 문자의 영역 마스크(실제 존재 위치=1, 나머지 영역=0)
- = 문자 토큰이 자기 글자 위치를 얼마나 잘 보고 있는지
- = 문자 토큰이 관련 없는 영역을 얼마나 보고 있는지
- Cross-Attention 맵은 어떤 이미지 위치가 어떤 텍스트 토큰을 참고하는지를 결정
-
의미: 올바른 위치에 대한 어텐션은 강화 + 잘못된 위치에 대한 어텐션은 억제 + 모든 문자에 평균적으로 적용
⇒ 각 문자 토큰이 자기 위치에만 집중하도록 해, 문자 단위의 정확한 시각적 텍스트 생성을 가능하게 함
3) 더 정확한 텍스트 렌더링을 위한 Fine-tuning 방법
선행 개념: DPO(Direct Preference Optimization)란?
- 강화 학습과 보상 모델 없이, ‘이게 더 좋다’는 선호 비교만으로 모델을 직접 학습하는 방법
그럼 DesignDiffusion에서 왜 DPO가 필요할까?
- 본 논문의 목표는 디자인 이미지에서 글자가 정확히 읽히고, 시각적으로 자연스럽게 배치되는 것
- 일반적인 diffusion loss는 ‘이미지처럼 보이는가’는 잘 보지만, ‘글자가 정확한가’는 잘 못 봄
- 디지인 이미지의 품질은 사람의 선호(글자가 하나라도 틀리거나, 어색한 배치 등)와 강하게 연결됨
논문이 선택한 전략: Self-Play DPO
- 사람이 만든 진짜 디자인 이미지를 GT 디자인 이미지(무조건 좋은 샘플)로 지정하고, 모델이 생성한 여러 샘플을 OCR, 멀티모달 모델로 평가해 가장 최악인 샘플을 자동으로 지정
- Winning Data = GT 이미지(사람이 만든 디자인 이미지)
- Losing Data = 텍스트 렌더링이 가장 나쁜 생성 이미지
- 이 winner-loser 쌍을 이용해 DPO loss로 fine-tuning을 진행한다
⇒ 사람의 개입(RLHF, 인간 피드백 기반 강화학습) 없이도, 사람의 선호(텍스트 정확성)에 부합하도록 모델을 정렬함
4. Experiment Analysis
1) SOTA 모델과의 정량적&정성적 비교
- Quantitative Results
- FID를 비롯해 Text Precision, Recall, F-score, Accuracy 전 지표에서 최고 성능 달성
- Qualitative Results
- SOTA 모델들은 시각적으로는 매력적인 이미지를 생성했지만, 정확한 텍스트 생성에는 여전히 불완전한 샘플들(누락, 왜곡)이 많이 관찰됨
2) User Study 결과
- 이미지 미학성, 텍스트 품질, 레이아웃 미학성, 텍스트-이미지 매칭이라는 지표에서 높은 선호도 달성
- 이미지 미학성 항목의 경우 SDXL 파인튜닝의 영향으로 경쟁 모델과의 차이는 상대적으로 제한적
3) Ablation Study
- Fine-tuning: 디자인 이미지를 사용하여 SDXL을 파인튜닝하면 FID에서 상당한 개선이 이루어지는 것을 관찰
- Prompt Enhancement: 5개의 모든 지표에서 상당한 개선, 특히 시각적 텍스트 정확도에서 큰 향상
- Loss 함수: 마찬가지로 모든 지표에서 개선, cross-attention 맵을 문자 영역으로 국소화하는 것의 효과 확인
- SP-DPO: FID를 제외한 4개의 지표에서 개선, FID는 win-lose 데이터 선택에 크게 좌우됨
5. Significance of Paper
1) 디자인 이미지 생성을 독립적인 문제로 명확히 정의한 논문
- 기존 Text-to-Image, 시각적 텍스트 렌더링 문제를 그대로 확장하지 않고 ‘디자인 이미지 생성’이라는 별도의 문제를 제시
- 텍스트를 부가 조건이 아닌, 이미지처럼 ‘핵심적인 시각 요소’로 다루었음
- 디자인 이미지 도메인에 특화된 메트릭과 실험을 통해 문제의 현실성을 보여주었음
2) 문자 단위 정확성과 시각적 조화를 동시에 달성한 최초의 end-to-end 접근
- 단어 단위 토큰화의 한계를 인지하고 character 레벨의 프롬프트 증강을 도입한 방법
- cross-attention 기반 문자 위치 감독과 결합해 정확한 텍스트 렌더링과 이미지 품질을 동시에 확보
- 사전에 정의된 레이아웃이나 glyph 조건 없이 one-stage + end-to-end 생성 구조를 실현함
3) 사람 선호를 반영한 diffusion fine-tuning 전략 제시
- 미세조정 과정에서, 디자인 이미지 품질이 사람 판단과 밀접하다는 점에 집중하였음
- 강화학습(RLHF) 없이, 새롭게 Self-Play DPO를 정의해 텍스트 품질 중심의 선호를 효과적으로 반영함
6. Future Directions
1) 폰트 스타일 & 브랜드 정체성도 반영해보는 아이디어
DesignDiffusion이 가능한 영역
- 프롬프트에 따라 텍스트의 스타일(색상, 곡률 등)을 자동으로 결정하고, 적합한 이미지를 그려넣음
- 사용자가 만약 특정 브랜드의 폰트나 고유 색상 적용을 원한다면, 잘 반영하지는 못하는 상태
⇒ DesignDiffusion이 가진 디자인 이미지 생성 능력을 → 실무 수준의 브랜드 디자인 도구로 진화시켜보자
아이디어 1: 폰트 스타일의 임베딩 도입
- 기존 모델이 문자 내용 학습에만 집중한것에 더해, ‘글꼴의 시각적 특징’을 벡터화해 입력하는 것
- 특정 폰트의 ‘A~Z’이미지를 입력받아 스타일을 추출하는 별도의 작은 인코더를 도입
- 내용을 담당하는 ‘캐릭터 임베딩’과 외형을 담당하는 ‘폰트 임베딩’을 분리해 사용자가 원하는 폰트로 스타일로 고정할 수 있게 하는 방법
아이디어 2: 브랜드 가이드라인 제공
- 특정 브랜드의 느낌이 나는 디자인 이미지를 원할 때, 브랜드의 정체성을 학습시키는 방법
- 브랜드 지정 색상(스타벅스의 그린, 한양대의 블루)을 입력으로 받아 생성된 텍스트가 해당 색상을 크게 벗어나지 않도록 규제하는 loss를 만들어보기
- 디자인 내에서 브랜드 로고가 들어갈 위치를 단독으로 처리해, 텍스트가 로고를 가리거나 디자인의 균형이 깨지지 않도록 기존의 Character Localization Loss를 확장 응용
아이디어 3: 프롬프트 템플릿 확장
- 본 논문에서 사용한 특수 템플릿을 확장해서, 사용자가 직접 텍스트 스타일을 지정할 수 있도록 하기
- Ex: "A luxury perfume logo of “gold” + "font: Arial" + "color: gold" + "Rendered characters: <|G|> <|O|> <|L|> <|D|> "
Pros & Cons
- Pros: 특정 글씨체와 브랜드의 정체성을 구현할 수 있어 시각적 통일성 향상, 별도의 후보정 작업 없이 실용적으로 바로 활용이 가능
- Cons: 다양한 폰트와 브랜드 규격을 엄밀하게 지키기 위해 더 복잡한 모델 구조나 많은 고품질 학습 데이터가 필요할 것으로 생각됨
2) 새로운 도메인 탐색: 기능적 정확성이 요구되는 이미지 생성 Task
개선할 만한 또 다른 도메인이 있을까?
- DesignDiffusion을 읽은 뒤, ‘디자인 이미지’ 도메인 외에도 현재 개선이 필요한 분야, 잘 생성하지 못하는 영역이 무엇인지 찾아보았고, 실제 활용 가능성이 중요한 이미지 도메인에 주목해보았다
- 결과적으로 제조업/물류업/유통업 등 다양한 산업 분야에서 교육/제조/DIY/요리 등의 목적으로 활용되는 ‘작업 매뉴얼 이미지’, ‘공정 교육 이미지’와 같이 기능적 정확성이 요구되는 이미지 생성이 아직 개선이 필요하다는 점을 확인했다
아이디어
- 일관성 있는 단계별 이미지 생성
- 조립, 작업 공정의 전,중,후 단계가 논리적으로 연결된 이미지 순서를 생성하는 방향을 연구
- 물체 정체성 유지: 1단계에서 사용한 부품이 이후 단계에서도 같은 형태와 크기로 등장하도록 유도
- 논리적인 동작 유지: 기존 비디오 생성 또는 멀티프레임 생성을 참고해, 여러 이미지를 생성할 때 이전 단계의 피처맵 등을 활용해보기?
- 도구-객체 상호작용 표현
- 사람의 손이나 도구가 객체를 조작하는 '접점'을 정확하게 보여주는 생성 방식을 연구
- 현재 모델은 '도구를 잡고 있는 손'을 생성할 때 도구가 손과 겹쳐있거나, 위치가 어색한 경우가 종종 발생
- 조작 부위에 대한 마스크나 도구를 사용하는 포즈 가이드 활용, 물리적 충돌이 없이 생성되는 방향 탐색해보기
Pros & Cons
- Pros: 공정 전체를 한눈에 볼 수 있는 일관된 작업 매뉴얼 이미지 생성 가능, 기존에 사람이 직접 제작해야 했던 이미지 제작 비용과 노동력 감소
- Cons: 초기에 오류가 생기면 이후 단계에 누적되어 이미지가 왜곡될 가능성, 도구나 손의 각도에 대한 정밀한 상호작용 데이터셋이 필요할 것으로 보임
※ 또 다른 도메인: 다이어그램 / 인포그래픽 이미지 생성
- 학부생 시절, 논리적인 흐름이나 개념 간 관계를 시각적으로 표현할 때, 우리가 개발한 서비스의 아키텍처를 시각화할때 아이어그램이나 인포그래픽 이미지 생성을 여러번 시도한 경험이 있다
- 하지만 화살표의 방향이 다르게 연결. 박스 간의 계층 구조 불일치, 텍스트의 깨짐, 어색한 아이콘이 포함된 경우를 상당히 많이 겪어 현재 이미지 생성 모델이 이를 충분히 잘 처리하지 못하고 있다는 인상을 받았다
- 다만 이 분야는 이미 일정 수준 이상의 연구가 진행되었을지도 모르기 때문에, 기존 연구와 한계점을 조사한 뒤 추가적인 개선 여지가 있는지 확인해봐야할 것 같다
