NeurIPS 2024.
Yupeng Zhou, Daquan Zhou2, Ming-Ming Cheng, Jiashi Feng
VCIP & TMCC, CS, Nankai University | ByteDance Inc | NKIARI, Futian, Shenzhen
2 May 2024
💡 Key Point
이미지의 피사체 Identitiy를 일관되게 생성할 수 있을까? 나아가, 이러한 생성된 이미지를 기반으로, long-range한 비디오 생성으로 확장할 수 있을까?
1. Motivation
- 기존 Text-to-Image 확산 모델은 단일 이미지/짧은 비디오 생성 퀄리티는 우수하지만, 여러 장면에 걸쳐 피사체의 일관성을 유지하는 것에는 한계가 있음
- 이를 완화하기 위한 기존 방법들은 trade-off를 가짐:
- IP-Adapter: 피사체 일관성은 비교적 우수하나(참조 이미지 때문에), 강한 가이드로 인해 콘텐츠의 제어 가능성이 감소
- InstantID / PhotoMaker: 콘텐츠 제어 가능성은 높지만, 여러 장면에서 피사체의 일관성은 떨어짐
⇒ 기존 방법들은 피사체 일관성 유지와 텍스트 제어 가능성 사이의 trade-off를 극복하지 못하며, 연속적인 이미지/비디오 생성에는 적합하지 않음
2. Insight
1) 훈련 없이도 Self-Attention을 통해 일관성을 유지할 수 있다
- 기존 확산 모델에서 피사체 불일관성은 파라미터 부족이 아니라 이미지 간 attention 상호작용이 부족하다는 구조적 한계에서 발생
- Self-Attention은 이미지의 전역 구조와 세부 속성을 결정하는 핵심 메커니즘 → 이를 조정하면 다중 이미지 간 피사체 특성 공유가 가능함
- 따라서 fine-tuning 없이도 self-attention 단계에서 이미지 간 연결을 유도하는 방식으로 일관성을 확보할 수 있다.
2) Latent 공간이 아닌 Semantic 공간에서 안정적인 비디오 생성이 가능하다
- 기존 비디오 생성 방식은 latent 공간에서 프레임 간 전이를 예측하지만, 큰 동작 변화나 long-range 수준에서는 불안정함
- Semantic 공간은 객체의 의미적,공간적 정보를 압축적으로 표현하므로, 큰 상태 변화에 대해 더 안정적인 전이 예측이 가능함
- 이미지 semantic embedding을 기반으로 모션을 예측하면, 물리적으로 자연스럽고 일관된 장면 전환 비디오 생성이 가능함
3) 스토리 생성을 위한 통합적인 프레임워크를 구축할 수 있다
- Consistent self-attention과 안정적인 프레임 전이(Semantic Motion Prediction)를 결합하면, 단일 모델로 스토리 전개가 가능함
- 텍스트 기반 장면 분할 → 일관된 이미지 생성 → 부드러운 비디오 전이라는 구조를 통해 스토리 단위의 이미지 생성이 가능해짐
- 단순 이미지/비디오 생성이 아닌 → 이야기의 구조를 갖는 이미지 생성으로의 확장 가능성을 가짐
3. Method
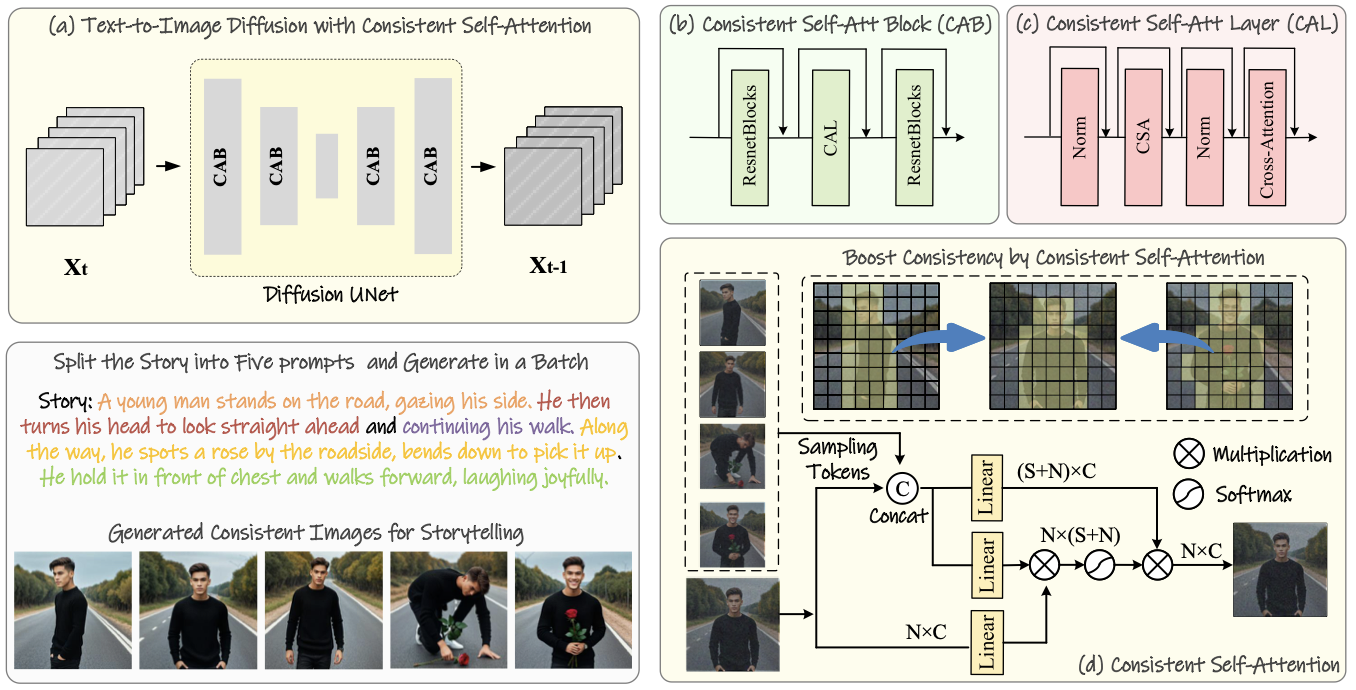
1) Cosistent Self-Attention: 배치 레벨의 셀프 어텐션
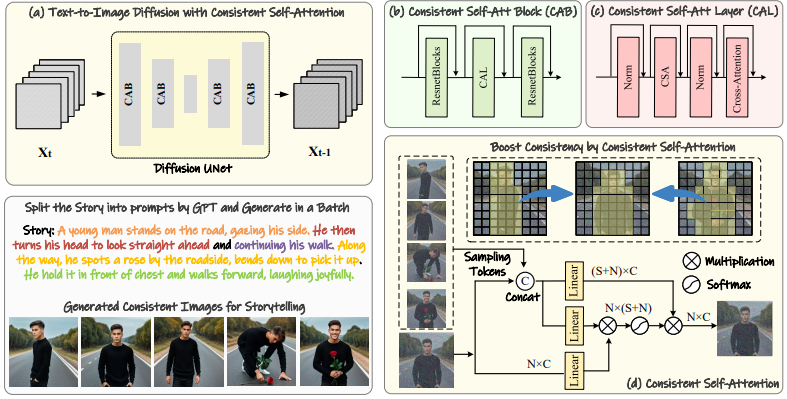
- 현재 이미지 외에, 같은 batch에 있는 다른 이미지들로부터 일부 토큰을 랜덤 샘플링한다
- 샘플링된 토큰 와 현재 이미지의 토큰 을 결합해 새로운 토큰 집합을 구성:
- Attention 계산 시 Q는 그대로 유지, K/V는 다른 이미지의 정보가 포함되도록 self-attention 수행
- Q/K/V의 투영 행렬은 기존 self-attention과 동일한 weight 재사용
- 추가적인 파라미터 학습이나
- Fine-tuning은 필요하지 않음
⇒ 여러 이미지가 서로를 참고하면서 생성되어 피사체의 identity 정보가 자연스럽게 유지됨. 동시에 프롬프트는 다르기 때문에 포즈, 행동, 장면은 다양성을 유지할 수 있음
2) Semantic Motion Predictor: 일관된 이미지를 자연스러운 비디오로 확장
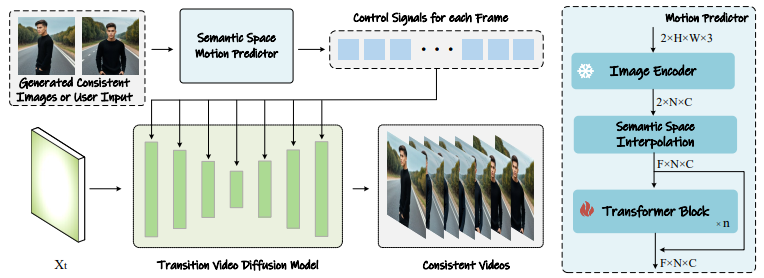
- 위 CSA 과정을 통해 생성된 일관된 이미지 시퀀스를 비디오로 확장하는 모듈
- CLIP의 이미지 인코더를 사용해 이미지를 semantic 공간으로 인코딩
- latent space 대비 공간 구조와 의미적 정보를 함께 보존함
- Transformer 구조를 사용해 중간 프레임들의 semantic 임베딩을 예측해 시작-끝 사이 프레임들을 선형적으로 보간(linear interpoolation)
- 예측된 semantic 임베딩들은 cross-attention의 control 신호로 사용해 각 프레임의 생성을 condition으로 사용
- 학습 과정:
- AnimateDiff 기반의 temporal module을 fine-tuning하여 시간적 일관성을 강화
⇒ 모션을 latent가 아닌 semantic 공간에서 예측함으로써, 큰 움직임이나 장거리(long-range) 전이에서도 robust하게 전환이 가능
4. Experiment Analysis
1) Consistent Image Generation 비교
- 추가 학습 없이 consistent self-attention만 적용했음에도 높은 피사체 일관성과 텍스트 제어성을 달성
- IP-Adapter: 텍스트 제어력 ↓ / 피사체 일관성 ↑
- PhotoMaker: 텍스트 제어력 ↑ / 피사체 일관성 ↓
- 정량 평가(CLIP 기만 유사도)와 정성 평가 모두 정체성 유지와 제어성의 균형을 가장 잘 만족함
2) Transition Video Generation 비교
- 기존 방법들은 latent 공간에서의 시간적 예측에 의존해, 중간 프레임의 붕괴가 종종 발생함
- SEINE: 중간 프레임 손상 및 최종 프레임으로 직접 점프하는 현상
- SparseCtrl: 연속성에서는 괜찮으나 여전히 중간 프레임에 손상 및 노이즈가 발생
- StoryDiffusion은 공간 구조와 의미를 보존한 상태로 자연스러운 장면 전환을 보임
- LPIPS, CLIP similarity, FVD/FID 등 모든 정량 지표에서 기존 방법들보다 뛰어남
3) Ablation Study & User Study
- Consistent Self-Attention의 샘플링 비율(0.3~0.9)
-
낮으면? → 정체성 유지가 약해짐
-
높으면? → 텍스트 제어력이 감소
⇒ 0.5 정도가 적당 = 일관성 유지 ↔ 텍스트 제어성 사이의 trade off
-
- 랜덤 샘플링은 grid 샘플링 대비 텍스트 제어력을 더 잘 유지하면서 충분한 일관성을 제공
- Consistent Self-Attention은 PhotoMaker와 같은 identity 제어 방식과도 결합이 가능
- plug & play 모듈로서의 확장이 가능
- 사용자 평가에서도 StoryDiffusion은 기존 방법 대비 매우 높은 비율로 선호됨
5. Significance of Paper
1) 피사체의 일관성 + 텍스트의 제어성을 모두 갖춘 T2I 생성 모델
- 기존 T2I 확산 모델이 피할 수 없었던 피사체 일관성 유지 ↔ 텍스트 제어성 보존 사이의 trade off를 추가 학습이 필요 없는 consistent self-attention으로 완화시킨 논문
- Identitiy를 토큰이나 참조 이미지에 강하게 고정하지 않고, 배치 수준의 self-attention을 통해 자연스럽게 수렴시키는 새로운 방법을 제시
- 추가 학습이나 파라미터 증가 없이도 높은 일관성 성능을 보여줌으로써, 경량&플러그형 구조를 제안함
2) 새로운 접근을 통한 이미지-비디오 생성의 자연스러운 연결을 마련
- 기존 transition video 생성이 latent 공간에서의 시간적 모듈에만 의존하던 한계를 극복 → semantic 공간에서의 모션 예측이라는 새로운 접근 제시
- CLIP 기반의 semantic 임베딩을 활용해, 큰 움직임이나 long-range 전환에서도 안정적인 비디오 생성이 가능함을 증명함
- 단일 이미지 생성에 머무르지 않고 스토리 기반 이미지들을 자연스러운 동영상으로 확장할 수 있는 통합적인 프레임워크를 제안했다는 점이 중요
6. Questions
1. Consistent Self-Attention의 토큰 샘플링 과정에 대한 고찰
- 논문에서는 Consistent Self-Attention을 위해 이미지 배치 내 다른 이미지들로부터 일부 토큰을 무작위로 샘플링하고, 이것을 현재 이미지의 토큰과 결합해 여러 이미지가 서로를 참고하며 생성하도록 돕는다.

- 나는 이 과정에서 사용되는 무작위 토큰 샘플링 방식에 대해 조금 궁금증이 생겼는데, 무작위로 선택된 토큰에는 피사체의 중요한 정보가 담긴 토큰 뿐만 아니라 배경이나 주체와 직접적인 관련이 없는 주변 요소, 노이즈가 포함될 가능성도 존재하기 때문이다.
- 만일 몇몇의 토큰 샘플링 과정에서 피사체의 일관성 정보는 적게 포함되고 불필요한 배경 정보나 노이즈가 과도하게 포함된다면, 이후 self-attention이 연산될 때, 생성 결과의 품질이나 텍스트 제어력에 어떤 영향을 미칠지 궁금했다. 그래서 무작위 샘플링 대신 피사체나 중요한 객체에 더 집중할 수 있도록 토큰을 선택하는 기법이나 모듈을 도입한다면 성능 향상이 이루어질까에 대한 생각이 들었다.
- 또한 이러한 궁금증은 논문의 ablation study에서 언급된 샘플링 비율(0.3, 0.5, 0.7)과 어떤 관련이 있을지 궁금했다. 샘플링 비율 조정이 어느 정도까지 노이즈 ↔ 일관성 간의 균형을 조절할 수 있는 지, 근본적으로는 ‘무엇을 샘플링하는가’에 대한 설계가 더 중요할 수도 있다고 생각했다.
7. Future Directions
큰 이미지 차이에서의 비디오 생성 한계를 개선해볼 수 있을까?
1) 현재 문제점(Appendix B.)
- Appendix B에서, StoryDiffusoin은 두 이미지 사이의 시각적 차이가 너무 큰 경우 이를 자연스럽게 연결하는 것에 아직 한계를 가지고 있다고 언급함
- 동작이 변화가 비약적으로 커질 수 있고
- 중간 프레임이 불안정하게 생성되는 문제
- 현재 방법론에는 비디오 전체를 아우르는 전역적인 정보 교환(global information exchange) 메커니즘이 없기 때문에, 아주 긴 영상을 완벽하게 생성하기에는 아직 부족함이 있음
- ex) ‘침실(시작) → 해변(끝)’ 같이 의미적 차이가 큰 쌍이 주어지면 어색한 영상이 생성될 수 있음
2) 개선 아이디어: LLM으로 중간 과정을 여러 스토리로 쪼개기
- 큰 변환을 한 번에 처리하는 대신 LLM(GPT 등)을 사용해 스토리를 여러 개의 중간 장면으로 분해해서 각 장면을 순서대로 자연스럽게 연결하는 방식
- 텍스트 분해 단계
- LLM을 이용해 스토리를 시간적으로 자연스러운 여러 중간 장면으로 분해하는 것
- 입력 프롬프트: 전체 스토리(장면 설명)
- 출력: 시간적, 의미적으로 자연스러운 중간 장면 시퀀스
- ex) 입력: "침실에서 일어나 해변으로 간다”
출력: “침대에서 일어난다 → 창문으로 걸어간다 → 문을 연다 → 밖으로 걷는다 → 해변에 도착한다”
- 이후 중간 장면의 semantic 임베딩을 생성함. 각 중간 씬을 CLIP semantic 공간으로 변환해 중간 장면들의 semantic 거리를 작게 유지함 → 자연스러운 장면 연결 가능
- 중간의 각 연속된 장면들에 대해서는 기존의 Semantic Motion Predictor를 그대로 사용해 여러 개의 짧고 안정적인 시퀀스를 순차적으로 연결해 구성
3) Pros & Cons
- Pros: 전이 안정성이 크게 향상될 수 있음, 부재했던 전역적인 정보 교환 메커니즘을 간접적으로나마 완화
- Cons: LLM의 결과(성능)에 따라 동영상 품질이 좌우된다는 점, 중간 스토리를 분해하는 추론 시간이 증가한다는 점
8. Feedback
1️⃣ Consistent Self-Attention의 랜덤 토큰 샘플링에 대해
랜덤 토큰 샘플링이 피사체와 무관한 배경 정보나 노이즈를 포함할 가능성에 대해 우려했지만, 교수님 피드백에 따르면 이 샘플링은 attention의 Key/Value를 구성하는 단계이며, 이후 self-attention 과정에서 주제와 관련 있는 토큰에 자연스럽게 attention이 집중되기 때문에 배경 영향은 상당 부분 완화될 수 있다고 한다.
또한 샘플링을 극단적으로 적게 하지 않는 이상, 주제 관련 토큰이 전혀 포함되지 않을 가능성은 크게 걱정하지 않아도 될 것 같다는 점도 정리하게 되었다.
결국 “무엇을 샘플링할 것인가”를 정교하게 설계하는 문제는 생각보다 덜 중요할 수 있으며, 계산량에 무리가 가지 않는 범위에서 충분히 샘플링한 뒤 self-attention이 필요한 정보를 걸러내도록 두는 접근이 더 합리적일 수 있다는 생각이 들었다.
2️⃣ LLM 기반 중간 장면 분해 아이디어에 대해
큰 시각적 차이를 가지는 장면 사이를 자연스럽게 연결하기 위해 LLM을 활용해 중간 장면을 생성하는 아이디어는 흥미로운 방향이라는 피드백을 받았다.
중간 장면을 생성해주면, 의미적 차이가 큰 두 장면 사이에서도 보다 점진적인 변화를 유도할 수 있고, 결과적으로 영상의 전이 안정성을 높일 수 있을 가능성이 있다.
아직 유사한 아이디어의 선행 연구가 명확히 떠오르지는 않지만, 충분히 탐구해볼 만한 방향이라는 점에서 향후 연구 주제로 발전시킬 수 있을 것 같다는 생각이 들었다.
