CVPR Workshop 2025.
Manuel Schwonberg, Hanno Gottschalk
TU Berlin, Mathematical Modeling of Industrial Life Cycles Group
3 Oct 2025
💡 Key Point
40개 이상의 도메인 일반화 세그멘테이션 연구를 종합적으로 분석해, 연구의 흐름이 foundation 모델로 이동하고 있음을 보여주는 survey 논문
1. Motivation
1) 연구 배경
기존 딥러닝 모델의 한계: Domain Shift(도메인 이동)
DNN(심층 신경망)은 semantic segmentation과 같은 vision 분야에서 큰 발전을 이루었으며 자율주행, 의료 영상 분석 등 다양한 분야에서 핵심적인 역할을 해왔다.
하지만 모델 학습에 사용된 도메인과 실제 추론이 수행되는 도메인이 다를 경우 모델의 성능이 크게 떨어지는 “Domain Shift” 현상을 해결하는 것은 아직까지도 오래된 과제로 남아있다.
기존 해결책: Unsupervised Domain Adaptation(UDA)
이 Shift 문제를 완화하기 위해, 초기에는 label이 없는 타겟 데이터를 활용하는 비지도 도메인 적응(UDA)방식이 널리 연구되었다.
하지만 현실에서는, 1) 레이블이 없는 타겟 데이터를 항상 확보할 수 있는 것이 아닐 뿐더러, 2) 실제 환경에서는 매우 다양한 도메인이 존재하기 때문에 모델을 특정 도메인에 일일이 적응시키는 UDA 방식은 한계를 가질 수 밖에 없다.
2) ‘도메인 일반화’의 등장
이러한 UDA의 한계를 극복하고자, 타겟 도메인 데이터에 대한 접근이나 지식 없이, 오직 소스 도메인(학습 데이터)만 학습하여 미지의 여러 타겟 도메인에 범용적으로 일반화를 하는 “Domain Generalization” 방법이 등장하였다.
3) 본 논문의 목적
- 광범위한 방법론 리뷰: 합성 데이터에서 실제 데이터로 이동하는 semantic segmentation 도메인 일반화 방법들을 수집하고 세밀하게 분류한다.
- 패러다임의 이동 소개: traditional 도메인 일반화 접근 방식 → foundation 모델을 활용하는 새로운 방식으로 바뀌는 연구 패러다임을 소개하고 분석한다.
- 성능 비교: 평가된 모든 접근법에 대한 심층적인 성능 비교를 제공하고, 특히 foundation 모델이 도메인 일반화에 미치는 영향을 입증하고 연구 방향을 제시한다.
2. Categorize
Mindmap of Domain Generalization
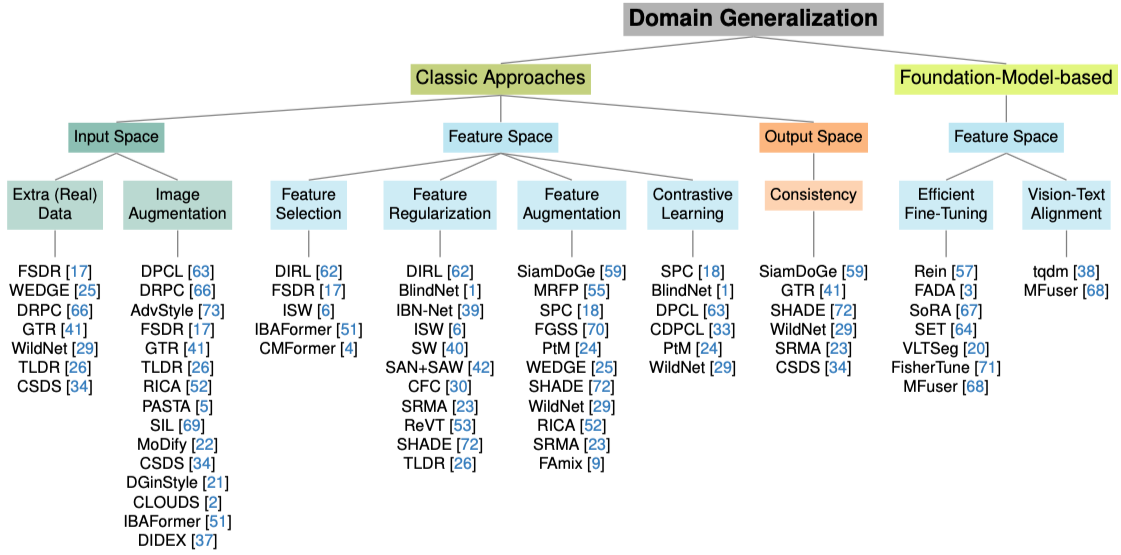
1) Classic Approaches
Input Space
네트워크의 입력 데이터를 변환해 모델의 일반화 능력을 키우는 방식이다. 원본 내용은 유지하면서 형태나 스타일만 바꾸기 때문에, “도메인 무작위화” 라고도 불린다.
여기서는 크게 1)Image Augmentation과 2)Extra Data 방법으로 나눌 수 있는데, 먼저 1)Image Augmentation 방법부터 살펴보자.
1.1. 색상 및 채널 기반 이미지 변환(Image Transformatinos)
가장 직관적이고 단순한 형태의 증강 기법이다. 이미지의 픽셀 통계값을 직접 변형하는 방법이다. (ex. RICA: 이미지의 색상 값 무작위 변경, MoDiFy: 무작위로 RGB 채널을 섞음)
1.2. 주파수 및 형태 증강(Frequency & Shape Augmentation)
공간 도메인이 아닌 주파수 도메인에서 변형을 가하거나 객체의 구조적 형태 학습을 강제하는 방식이다. (ex. PASTA: RGB 이미지를 주파수 공간으로 넘겼던 시도, FSDR: 주파수 도메인에서 스타일을 전송)
1.3. 스타일 전송(Style Transfer)
타겟 도메인 데이터 없이 소스 도메인의 스타일을 무작위로 바꾸기 위해 주로 적응형 인스턴스 정규화(AdaIN)와 같은 기법을 활용하는 방식이다. (ex. DPCL: 기본 증강 이미지에 AdaIN을 적용한 뒤 원본 복원 손실을 통해 학습, AdvStyle: 적대적 학습을 통해 AdaIN의 통계값을 조작하여 이미지 증강)
1.4. 생성형 확산 모델 활용(Diffusion Models)
최근 주목받는 T2I 확산 모델을 활용해, 타겟 도메인 데이터 없이도 사진처럼 사실적인 실사 이미지를 생성해 훈련 데이터셋을 크게 확장하는 방식이다. (CLOUDS: LLM과 SD을 이용해 교통 상황 실사 이미지를 합성하고 의사 라벨로 학습, DGinStyle: 확산 모델의 사전 지식을 보존하면서 원본과 합성 이미지를 섞은 데이터셋을 구축)
이제 2)Extra (Real) Data 방법을 살펴보자.
2. Extra Real Data: 외부 실제 데이터 활용과 쟁점
위에서 소개한 이미지 증강 방법 외에도 일부 method들은 타겟 도메인 대신 ImageNet, 예술 작품, 웹 크롤링 데이터 등 외부의 실제 데이터를 훈련에 적극적으로 이용한다.
이의 장점으로는 훈련 과정에서 현실 세계의 스타일과 패턴이 반영되므로 모델의 일반화 성능을 비약적으로 높일 수 있다.
반면에 한계점도 있는데, 엄밀히 따지자면 ‘타겟 데이터 없이 소스 도메인만으로 일반화한다’는 도메인 일반화의 본래의 문제 정의를 우회하는 것이기 때문에, 외부 데이터를 쓰지 않는 다른 method들과의 과학적이고 공정한 성능 비교를 어렵게 만든다는 단점도 있다.
Feature Space
네트워크 내부의 특성 맵(Feature Map) 단계에 개입하여 도메인에 흔들리지 않는 불변(Domain-invariant) 표현을 학습하는 방식이다.
여기서는 크게 Feature Selection / Feature Regularization / Feature Augmentation / Contrastive Learning
네 가지 방법으로 나눌 수 있다.
1. Feature Selection
네트워크가 도메인에 종속적인(민감한) 특징과 독립적인(불변의) 특징을 구분해 각각 다르게 처리하도록 유도하는 방식이다.
예를 들면 covariance 행렬에 k-평균 clustering을 적용해 스타일에 민감한 특징 식별을 한다거나(ISW), ViT의 아키텍처를 활용해 배치 내 여러 이미지 간 cross-attention을 적용해 불변적인 특징을 선택하는 방법(IBAFormer) 등이 있다.
2. Feature Regularization
모델 training 시 특성 맵에 특정한 수학적, 구조적 제약을 가하여 네트워크가 도메인 불변 특징에만 집중하도록 강제하는 방식이다. 스타일에 민감한 정보가 담긴 채널 간 공분산을 비상관화하거나, ImageNet 같은 외부 사전 지식을 정규화의 기준으로 삼기도 한다.
예를 들면 얕은 레이어엔 스타일을 제거하는 모듈을, 깊은 레이어엔 콘텐츠를 보존하는 모듈을 배치하거나(IBN-Net), 사전 학습된 ImageNet 모델의 특징과 훈련 모델 특징 간에 L2-Loss를 적용하는 방법(SHADE) 등이 있다.
3. Feature Augmentation
Input Space에서 이미지를 직접 증강했던 것과 마찬가지로, 네트워크 내부의 특징 맵 통계값(평균 및 분산) 자체를 섞거나 무작위로 조작하는 방식이다.
예를 들면 여러 스타일을 모은 메모리 뱅크를 구축하고 현재 특징과 가중 융합하여 증강하거나(SPC), CLIP 텍스트 인코더와 프롬프트를 활용해 다채로운 스타일 뱅크를 수집하고 특징 증강에 활용하는 방식(FAmix) 등이 있다.
4. Contrastive Learning
CLIP에서 배웠던 것 처럼, 비슷한 데이터(Positive pair) 특징은 가깝게 뭉치고, 다른 데이터(Negative pair) 특징은 멀어지도록 밀어내는 학습법이다. 타겟 데이터가 없는 한계를 극복하기 위해 이미지 증강이나 스타일 전이로 여러 쌍을 만들어 학습을 수행한다.
예를 들면 스타일이 다른 두 이미지에서 동일한 위치의 픽셀은 가깝게, 다른 위치의 픽셀은 서로 밀어내도록 대조한다거나(WildNet), WildNet의 기준에 더해 모델이 잘못 예측한 픽셀까지 음성 샘플로 간주해 밀어내는 방법(BlindNet) 등이 있다.
Output Space
모델이 최종적으로 내놓는 결과물(예측값) 단계에서 일반화 성능을 높이는 방식이다.
이 출력 공간의 핵심은 Consistency Learning(일관성 학습)으로, 이미지의 외관(스타일이나 텍스처)가 어떻게 변하든지 원본 내용이 같다면 네트워크는 무조건 동일한 예측을 해야 한다는 원리에 기반한다. 이를 수행하려면 앞서 다룬 이미지 증강이나 스타일 전이를 통해 내용만 같고 스타일이 다른 이미지 쌍을 얻어내는 과정이 필수적이다.
출력값이 서로 똑같아지도록 강제하기 위해 어떤 Loss를 사용하는지에 따라 크게 1) L1 손실 기반과 2) 통계적 발산 지표 기반 방법으로 나눌 수 있다.
1. L1 Loss-based Consistency
가장 직관적인 방법으로, 두 예측값 간의 ‘절대적인 차이’를 줄여 일관성을 맞추는 방식이다.
원본 이미지를 globally, locally하게 무작위해 스타일을 바꾼 뒤, 두 결과물에 대한 예측값 사이의 L1 Loss를 최소화하도록 학습하는 방식(GTR)이 있다.
2. Divergence-based Consistency
네트워크의 결과물을 단순한 값이 아닌 확률 분포로 보고, 두 예측 분포 사이의 거리를 측정하는 통계학적 지표들을 활용하는 방식이다.
두 입력 이미지에 대한 예측 일관성을 맞추기 위해 정보량 차이를 측정하는 KL-divergence 지표를 활용하거나, 서로 다른 스타일 이미지들 사이의 촘촘한 예측 일관성을 강제하기 위해 젠슨-섀넌 발산(Jensen-Shannon divergence)을 활용하기도 한다.
2) Foundation Model Based
Foundation 모델이 웹에서 학습한 압도적이고 범용적인 지식을 훼손하지 않고 자율주행 등의 세그멘테이션 task에 맞춰 영리하게 활용하는 새로운 패러다임이다.
Efficient Fine-tuning
※들어가기 전: 왜 ‘효율적’ 미세조정일까?
foundation 모델은 대규모 이미지+텍스트로 사전학습되어 다양한 환경에서도 잘 작동하는 강한 일반화 능력을 가진다. 하지만 이를 시맨틱 세그멘테이션 같은 특정 작업에 적용하려면 미세조정이 필요하다.
이때 전체 모델을 다시 학습하면 기존의 일반화 능력을 잃는 망각 현상이 발생할 수 있다. 이를 해결하기 위해 모델의 기존 파라미터는 고정하고, 작은 추가 모듈인 어댑터만 학습하는 효율적 미세조정 방식이 사용된다. 이는 LoRA에서 영감을 받은 접근이다.
1. 토큰을 활용한 번역기 역할을 넣기: Rein
Rein은 이 분야의 초기 접근법 중 하나이다. 파운데이션 모델이 이미 추출해 놓은 훌륭한 이미지 특징들과, 우리가 최종적으로 찾아내야 할 '세그멘테이션 객체(예: 자동차, 도로, 사람)' 사이에는 간극이 존재한다.
그래서 Rein은 이 둘을 연결해 주는 학습 가능한 토큰들의 집합을 중간에 끼워 넣는다. 이 토큰들은 얼려진 foundation 모델의 특징들과 새 과제 사이의 '유사도 행렬’을 계산하며, 일종의 통역사 역할을 하여 원래 지식을 보존하면서도 세그멘테이션을 잘 수행하도록 돕는다.
2. 주파수 공간에서 어댑터 끼워넣기: FADA, SET
이 두 논문은 앞서 고전적 방식에서 다루었던 ‘도메인의 외관(스타일)는 주로 특정 주파수 대역에 몰려있다’는 힌트를 파운데이션 모델에 결합한 것이다. 즉, foundation 모델에서 나온 특징을 주파수 공간으로 변환해 분석하는 방법으로 이해하면 된다.
FADA: 특징을 Haar wavelet transform으로 저주파와 고주파로 분해한다. 이때 도메인에 민감한 스타일 정보는 주로 고주파에 포함되므로, 고주파 스트림에만 인스턴스 정규화를 적용해 불필요한 스타일을 억제한다.
SET: 특징을 위상(형태)과 진폭(스타일)로 분해한 뒤, 진폭 스트림에만 인스턴스 정규화를 적용하여 도메인 종속적인 정보를 제거한다.
3. Segmentation 맞춤형 LoRA: SoRA
SoRA는 흥미로운 사실의 발견으로부터 만들어진 모델인데, foundation 모델의 특징을 선형대수학의 특이값 분해(SVD)라는 수학적 도구를 통해 쪼개보았더니, 특징이 '큰 덩어리(Major singular components)'와 '작은 덩어리(Minor singular components)'로 나뉜다는 걸 알아내었다.
- 큰 덩어리: 윤곽선이나 객체의 핵심 같은 '일반화된 범용 지식'
- 작은 덩어리: 특정 도메인(날씨, 카메라 렌즈 등)에 얽매인 '종속적인 정보'
그래서 SoRA는 기존 지식(큰 덩어리)은 절대 건드리지 않고 놔둔 채, 오직 도메인 특이적인 '작은 덩어리' 부분만 살짝 미세조정하여 모델을 새로운 환경에 완벽하게 적응시킨다.
4. 얼리지 않고 미세조정하기: VLTSeg, FisherTune
대부분이 파운데이션 모델을 얼리는 방식을 택하지만, 이 두 모델은 다르게 접근한다.
VLTSeg: 아주 심플하게, 가중치를 고정하지 않고 파운데이션 모델 전체를 통째로 훈련시켜 보는 단순하지만 강력한 베이스라인(기준점)을 제시한다.
FisherTune: 피셔 정보 행렬을 활용해 도메인 변화에 민감한 파라미터를 식별한다. 전체를 학습하는 대신, 민감도가 높은 일부 파라미터만 선택적으로 미세조정하여 성능 저하를 방지한다.
Vision-Language Alignment
※ 들어가기 전: 왜 굳이 '언어(텍스트)'를 쓸까?
CLIP과 같은 VLM은 이미지와 텍스트를 함께 학습해 두 정보를 정렬한 모델이다. 도메인 일반화에서는 변하지 않는 텍스트 개념이 안정적인 기준(Anchor) 역할을 한다.
하지만 기존 연구들은 학습 후 텍스트 인코더를 활용하지 않는 한계가 있었고, 이를 극복해 언어 정보를 끝까지 활용하는 모델로 tqdm과 MFuser가 제안되었다.
1. 단어의 의미로 픽셀을 채우기: tqdm
tqdm은 CLIP의 텍스트 인코더를 활용해 클래스 이름을 쿼리로 변환하고, 교차 어텐션을 통해 각 픽셀과 텍스트 간의 관련성을 계산한다. 이를 통해 단어 의미를 반영하여 픽셀 특징을 정교하게 업데이트하고, 다양한 정렬 손실로 성능을 강화한다.
2. 최신 아키텍처로 두 영역 섞기: MFuser
MFuser는 시각 인코더와 텍스트 인코더를 함께 활용하며, 시각-텍스트 정렬 모듈과 Mamba 블록을 통해 두 정보를 효율적으로 결합한다. 이를 통해 도메인 변화에도 강건한 정렬을 수행한다.
3. Performance Analysis
다양한 도메인 일반화 모델들이 실제로 얼마나 성능 차이를 보이는지 분석한 결과이다. 공정한 비교를 위해 모든 모델은 합성 데이터(GTA5, Synthia)로만 학습한 뒤, 실제 주행 데이터(Cityscapes, BDD100k, Mapillary)에서 얼마나 잘 맞추는지(mIoU) 평가되었다.
백본의 영향력
파운데이션 모델의 승리 어떤 기본 네트워크를 썼느냐에 따라 성능의 체급이 크게 달라진다.
- 고전 모델 (ResNet-101): ImageNet으로 초기화된 기존 모델들의 최고 성능은 평균 48% 정도에 머무른다.
- 새로운 아키텍처 (MiT-B5): 트랜스포머 기반의 SegFormer(MiT-B5)를 사용하면 최고 성능이 57%로 크게 뛴다.
- 파운데이션 모델 (ViT 등): 대규모 사전 학습을 거친 파운데이션 모델이 등장하면서 DG 성능은 크게 상승한다. 최신 파운데이션 모델 기반 접근법인 SoRA는 68%라는 압도적인 성능을 보여준다.
소스 데이터셋의 한계
GTA5 vs Synthia 어떤 합성 데이터로 공부했느냐에 따라 실제 환경에서의 적응력이 크게 달라진다.
- Synthia에서 일반화의 어려움: GTA5를 소스로 썼을 때의 최고 성능은 68.3%인 반면, Synthia를 썼을 때의 최고 성능은 55.1%에 불과한다. 최신 파운데이션 모델들조차 Synthia로 학습할 때는 성능 하락을 겪는다.
- 그 이유는? Synthia의 데이터 크기(9,400장)가 GTA5(24,499장)보다 훨씬 작을 뿐만 아니라, 카메라의 시점이 실제 데이터와 다르고 렌더링 품질 자체도 상대적으로 낮기 때문.
고전 접근법의 성능 정체
오래된 백본(ResNet-101)을 사용하는 기존 고전적 방식들은 현재 성능 발전이 거의 멈춘 상태이다.
대부분의 고전적 방법론들이 비슷한 성능 범위 안에서 비슷비슷한 결과를 내고 있으며, 결국 최근의 획기적인 성능 돌파구는 방법론의 조작보다는 파운데이션 모델과 같은 '새로운 아키텍처의 도입'에서 비롯되었음을 알 수 있다.
