
ECCV 2022.
Nataniel Ruiz, Yuanzhen Li, Yuanzhen Li et al,.
Google Research
30 Aug 2022
💡 Key Point
소수의 이미지로 특정 주체를 모델에 '개인화’시키고 고유 식별자를 통해 어떤 맥락에서도 높은 충실도로 해당 주체를 생성할 수 있게 해보자.

1. Motivation
- 기존의 Text-to-Image diffusion 모델은 프롬프트로부터 고품질의 이미지 생성은 잘 하지만, 특정 인스턴스의 Identitiy를 일관되게 유지하는 데에는 한계가 있음
- 특히 few-shot 개인화 환경에서 소수의 데이터로 학습 시 과적합, 다양성 감소, 그리고 language drift문제가 종종 발생
- 이러한 이유는 모델이 class 레벨의 semantic prior에는 강하나, Instance 레벨의 고유한 appearance를 표현하는 매커니즘이 부족하기 때문
- 또한 이미지 기반 편집 방법들은 국소적 수정에는 효과적이지만 완전히 새로운 장면, 맥락, 포즈를 생성하는 데에는 제약이 존재
⇒ 결과적으로 소수의 참조 이미지만을 사용하여 특정 subject의 정체성을 유지하면서 다양한 장면과 포즈로 확장하는 것은 여전히 어려움
2. Insight
1) 확산 모델은 few-shot fine-tuning 환경에서도 prior를 유지가 가능하다
- 대규모 text-to-image diffusion 모델은 소수의 데이터(3–5장)로 fine-tuning하더라도 사전 학습된 시각,언어 prior를 완전히 붕괴시키지 않는다 (기존 GAN 계열과 대비)
- 이는 모델을 완전히 재학습하지 않고도 새로운 시각적 개념을 이해시킬 수 있는 가능성이 있음
2) Subject는 새로운 ‘단어’로 모델의 생성 공간에 편입될 수 있다
- 특정 subject는 단순한 이미지 조건이나 설명 텍스트가 아니라 고유한 identifier token과 결합된 새로운 시각적 개념으로 표현이 가능하다
- 즉, personalization 문제는 입력 조건 설계 문제가 아니라 language와 vision 사이의 dictionary 확장 문제로 해석이 가능함
2.3. Instance-level 정보는 class-level prior와 결합되어야 한다
- 만약 subject를 class로부터 완전히 분리하여 학습할 경우, 학습이 불안정해지고 다양한 포즈,시점,맥락 생성이 어려워진다
- 하지만 class noun을 함께 사용하는 경우 → 모델의 기존 semantic prior를 활용이 가능하고 인스턴스의 외형을 새로운 맥락으로 자연스럽게 확장이 가능하다
⇒ 따라서 subject 개인화는 instance identity를 class semantic prior에 엮어야 함
3. Method
Figure: Fine-tuning
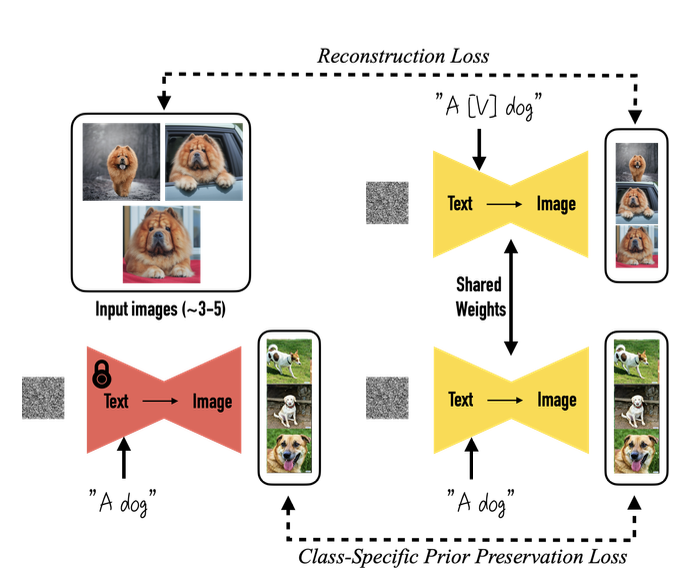
1) Subject를 표현하기 위한 프롬프트 설계
- DreamBooth는 특정 subject를 단순한 이미지 조건이 아닌 텍스트 토큰 수준에서 참조 가능한 개념으로 표현함
- 모든 입력 이미지에 동일한 프롬프트 구조를 적용
- ex) “A [V] dog”
- [V] 는 특정 instance를 가리키는 고유 identifier
- dog은 subject가 속한 class
⇒ class noun을 포함함으로써 1) 모델의 기존 semantic prior를 활용할 수 있고, 2) 새로운 포즈, 시점, 맥락으로의 확장이 가능해짐
2) 희귀 토큰 Identifier 도입
- 일반적인 단어를 identifier로 사용할 경우 → 기존 언어적 의미와 충돌, subject 학습이 불안정해짐
- 이를 피하기 위해 모델 vocabulary 내에서 prior가 약한 rare token을 선택
- token 단위에서 rare한 시퀀스를 구성한 뒤 이를 detokenize하여 identifier 문자열로 사용
⇒ Identifier를 기존 개념과 분리시킬 수 있고 해당 토큰이 순수하게 subject instance를 가리키도록 학습됨
3) 모델 전체 Fine-Tuning 전략
- DreamBooth는 token embedding만 학습하지 않고 diffusion model 전체를 fine-tuning하는 방법
- 이로 인해 subject 정보가 단순 조건이 아니라 모델 출력 공간 자체에 내재화(implant)됨
- diffusion 모델의 특성상 few-shot 환경에서도 비교적 안정적인 fine-tuning이 가능
⇒ Subject는 다양한 프롬프트와 결합되어 새로운 장면,포즈,스타일로 자연스럽게 생성됨
4) Class-specific Prior Preservation Loss 설계
- 하지만 모델 전체 fine-tuning은 language drift와 diversity 감소라는 위험을 동반할 수 있음
- 이를 방지하기 위해 Class-Specific Prior Preservation Loss를 도입
-
사전 학습된 모델이 데이터를 생성
- 조건 벡터:
- 데이터 생성:
-
학습 손실 함수 정의
-
- 이 loss는
- 모델이 주어진 특정 주체의 특징을 학습하고(첫 번째 항)
- 기존의 class semantic prior를 유지한다(두 번째 항)
⇒ subject fidelity와 diversity 간의 균형을 유지한 학습이 가능해짐
4. Experiment Analysis
1) Subject & Prompt Fidelity
- DINO, CLIP-I 기준에서 Textual Inversion 대비 높은 subject fidelity: 특정 instance의 정체성을 더 잘 보존함
- CLIP-T 스코어에서도 우수: Subject를 유지하면서도 프롬프트 조건을 충실히 반영함
- 즉, DreamBooth는 정체성 보존과 프롬프트 반영을 동시에 달성함
2) Comparison with Textual Inversion
- 전반적인 정량 지표에서 DreamBooth가 우수함
- 사용자 평가에서도 subject 유사도와 프롬프트 일치도 모두 DreamBooth 선호
- 즉, token embedding 기반 방법의 표현력 한계를 인지 + full-model fine-tuning의 효과를 입증
3) Effect of Prior Preservation Loss
- 만일 Prior Preservation Loss가 부재 시 language drift 발생 + 생성 다양성 감소
- Loss 적용 시 다양한 포즈,시점,맥락 생성이 가능
- Prior Preservation Loss는 DreamBooth 성능을 좌우하는 핵심 요소
4) Qualitative Results
- 기존 방법 대비 subject의 핵심 외형 특징을 더 잘 보존하고 장면과의 결합이 자연스러움
- 다양한 태스크에서 일관된 결과: recontextualization, view synthesis, style 변환 등
- 의미: 단순 복제가 아닌 semantic generalization이 이루어짐
5. Significance of Paper
1) 클래스의 일반적인 개념(prior) 유지와 subject의 다양성을 동시에 확보한 방법
- 대규모 사전학습으로 형성된 class-level semantic prior를 보존하면서도, 특정 instance의 시각적 정체성을 주입하는 문제를 정식으로 다룸
- Few-shot 환경에서도 과도한 prior 붕괴 없이 새로운 subject를 생성할 수 있음을 보여줌
- 단순한 overfitting이 아닌, prior preservation이라는 관점에서 개인화 문제를 재정의함
2) 효과적인 프롬프트 설계 방식 제안
- 희귀 토큰(identifier)과 클래스 토큰을 결합한 ‘[V] + class’ 구조의 프롬프트 설계를 제안
- 텍스트 프롬프트를 통해 instance identity와 class semantics를 동시에 조건화하는 방법을 제시
- 이후 개인화,커스터마이징 연구들에서 표준으로 채택되는 설계 패턴을 정립함
3) 생성 모델 Personalization 연구를 본격적으로 촉발한 논문
- Text-to-Image 모델에서 개인화를 독립적인 연구 문제로 다룬 첫 대표적 사례
- 이후 등장한 Custom Diffusion, LoRA 등 개인화 기법들에 문제 설정과 비교 기준을 제공
- 일반 생성 모델 → 개인 맞춤형 생성 모델로의 연구 패러다임 전환을 제안한 논문
6. Questions
Prior Preservation Loss의 잠재적 한계에 대한 고찰
- 본 논문에서는 개인화 학습 과정에서 발생할 수 있는 language drift를 방지하기 위해 모델이 스스로 생성한 이미지를 정답으로 사용하는 Class-specific Prior Preservation Loss를 제안한다. 이 손실은 특정 인스턴스를 학습하더라도 해당 클래스의 일반적인 의미 분포를 유지하도록 유도하는 역할을 한다.
- 여기서 들었던 궁금증은, 만약 pre-trained 모델이 이미 특정 클래스(ex. doctor)에 대해 다양성이 부족하거나 편향된 데이터 분포를 가지고 있다면, prior preservation loss가 이러한 편향을 완화하기보다는 오히려 심화하는 방향으로 작용하지 않을까 하는 궁금증이 들었다.
- 실제 편향 현상 예시를 찾아본 결과, “A photo of a doctor” 프롬프트에 대해 stable diffusion v1.4/1.5 계열은 90% 이상이 ‘백인 남성’ 이미지를 생성하는 경향을 보인다는 사례를 찾을 수 있었다.
- 이런 상황에서 사용자가 ‘여성 흑인 의사’라는 구체적인 인스턴스를 학습시킬 경우, prior preservation loss는 모델에게 의사 클래스의 일반적인 분포를 잊지 않도록 계속 안내하고, 그렇게 된다면 학습 과정에서 ‘여성 흑인 의사’를 이상치로 취급해 억지로 백인 남성의 특징을 섞거나 학습을 방해할 가능성도 존재할까 라는 생각이 들었다.
- 이러한 관점에서, prior preservation loss가 편향된 사전 분포를 전제로 할 경우 발생할 수 있는 구조적 한계는 충분히 의미 있는 문제 제기인지, 혹은 이후 연구들에서 이미 인식되어 다른 방식으로 보완되었거나 개선된 설계들이 제안되고 있는지 궁금했다.
7. Future Directions
맥락-외형 얽힘을 완화할 수 있을까?
1) 현재 문제점
- DreamBooth 방법은 종종 프롬프트로 지정된 맥락이 주체의 외형을 의도치 않게 변화시키는 현상이 종종 관찰됨
- ex) 동일한 가방 주체에 대해 서로 다른 맥락을 지정했을 때, 가방의 색상이나 재질이 함께 변형

2) 원인 분석
- 주체를 표현하는 토큰은 주체의 고유 외형 뿐만 아니라 주체가 있는 환경, 학습 데이터에 우연히 붙은 부수적 속성들을 하나의 토큰 임베딩으로 표현함
- 이 토큰은 다른 텍스트 토큰들과 동일한 cross-attnetion 경로를 공유하기 때문에 → context를 나타내는 토큰이 토큰이 형성하는 attention map에 간섭하게 됨
- 즉, context와 appearnace가 구조적으로 분리된 표현 공간을 갖지 못하는 상태
3) 개선 전략: Attention Level에서 분리하기
- 주체 외형과 맥락 정보를 서로 다른 attention 경로에서 처리하도록 분리해보자
- 구체적으로, 프롬프트 내 토큰을 다음과 같이 두 가지로 분류:
- subject 관련 토큰 (ex. V∗, 사물,객체 이름)
- context 관련 토큰 (ex. 배경, 장면, 환경)
- 이후 cross-attention 연산에서 일부 어텐션 헤드는 subject 토큰만 보도록 하고, 다른 어텐션 헤드는 context 토큰에만 보도록 분리하는 구조
- 이를 통해 context 토큰이 주체의 appearance latent에 직접적으로 영향을 주는 경로를 막고 context 변화는 주로 배경, 구성 요소에만 반영되도록 유도할 수 있을까?
4) Pros & Cons
- Pros: 주체 외형과 맥락 간의 얽힘을 구조 차원에서 직접 완화할 수 있음
- Cons: 구현 복잡도 증가, 토큰 분류 기준에 대한 설계까 추가로 필요함
8. Feedback
1️⃣ Prior Preservation Loss와 편향 문제
Prior preservation loss가 편향된 사전 분포를 유지·강화할 가능성에 대해 고민했지만, DreamBooth는 이미 잘 pre-trained된 Stable Diffusion을 전제로 하며, 해당 loss의 목적은 기존 지식을 보존하는 데 있다는 점을 다시 정리하게 되었다.
편향 문제는 DreamBooth 특유의 문제라기보다는 generative model 전반의 이슈이며, customization 과정에서 이를 완화하려는 연구들도 존재한다는 점을 알게 되었다.
2️⃣ Subject–Context 분리 아이디어
주체 외형과 맥락이 얽히는 문제를 attention 수준에서 분리해보자는 아이디어는 흥미로운 방향이라는 피드백을 받았다.
다만 단순 토큰 분리보다는 segmentation 등 추가 정보를 활용해 공간적으로 분리하는 접근이 더 현실적일 수 있으며, 이는 customization 성능 향상을 위한 연구 주제로 확장 가능성이 있어 보인다.
