CVPR 2023.
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, Jun-Yan Zhu
Carnegie Mellon University | Tsinghua University | Adobe Research
8 Dec 2022
💡 Key Point
소수의 예시만으로도 모델이 새로운 개념을 빠르게 학습하도록 만들 수 있을까? 나아가, 여러 개의 새로운 개념을 함께 조합해 생성할 수 있을까?
1. Motivation
- 기존의 Text-to-Image 모델은 다양한 객체와 장면에 대해 범용적 생성 능력을 갖추었지만, 개인적, 희귀한 개념 생성에는 한계를 가짐
- 이러한 개념을 소수의 이미지로만 모델에 주입할 경우, 여러 문제가 발생함:
- 기존에 학습된 개념의 의미가 변형되거나 망각되는 문제가 발생
- 소수의 샘플로 인해 overfitting이 발생 → 생성 결과의 다양성이 감소
- 두 개 이상의 새로운 개념을 동시에 조합해 생성하는 것이 어렵고 한 개념을 누락하거나 붕괴된 결과를 종종 생성
- 기존의 transfer learning 방법들은 학습 시간과 연산 비용이 큼
- DreamBooth: 모델 전체의 파라미터를 조정
- Textual Inversion: 새 단어 벡터를 추가&최적화
⇒ 기존 방법들은 ‘단일 개념 커스터마이징’에는 어느정도 대응을 할 수 있지만, ‘효율적&안정적인 다중 개념 조합 문제’에는 적합하지 않음을 인식
2. Insight
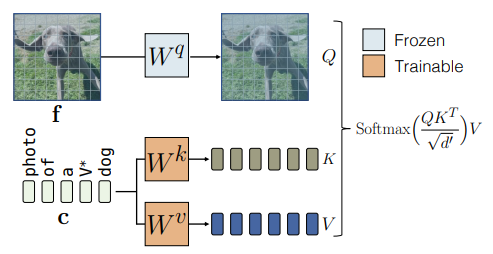
1) Fine-tuning에서 실질적인 변화는 cross-attention에서 발생한다
- 전체 모델을 미세조정했을 때, cross-attention 레이어의 파라미터 변화량이 가장 크게 나타난다
- Cross-attention은 전체 파라미터의 약 5%에 불과하지만, 새로운 개념을 학습하는 과정에서 가장 적극적으로 업데이트되는 지점이다
- 또한 T2I diffusion 모델에서 텍스트 특징은 K,V 투영을 통해서만 적용된다
- 즉, K,V만 업데이트하는 것이 구조적으로 충분하며, 가장 직접적인 개념 주입 방식이다
2) 정규화 과정을 추가해 기존의 학습된 의미를 기억하자
- 타겟 개념 이미지와 텍스트 쌍만으로 미세조정을 수행할 경우, 여러 문제가 발생한다:
- Language Drift (기존 단어 의미 변화)
- 의미 누수 (카테고리 전체가 특정 인스턴스로 붕괴)
- 과적합 & 생성 다양성 감소
- 따라서 유사한 캡션을 가진 실제 이미지 기반 정규화 데이터를 함께 학습함으로써, 기존 단어 의미를 보존할 수 있다
3) 공동 학습 & 최적화된 개념 병합
- Cross-attention의 K,V만 업데이트하면, 각 개념은 텍스트 특징이 latent space으로 매핑되는 방식으로 표현된다.
- 이 매커니즘 덕분에:
- 여러 개념을 공동 학습(joint training)할 수 있고
- 개별로 학습된 개념들을 제약 최적화 문제로 병합할 수 있다
- 즉, 다중 개념 조합을 수식적으로 다룰 수 있어 개념 간 간섭을 컨트롤할 수 있다
3. Method
1) Cross-attention의 , 만 업데이트
- 목적: 주어진 텍스트가 특정 이미지 분포로 잘 매핑되도록 모델을 업데이트 하는 것
- 관찰: 텍스트 feature는 오직 K,V의 투영 행렬(, )을 통해서만 모델에 입력됨
- 이후 cross-attention 연산:
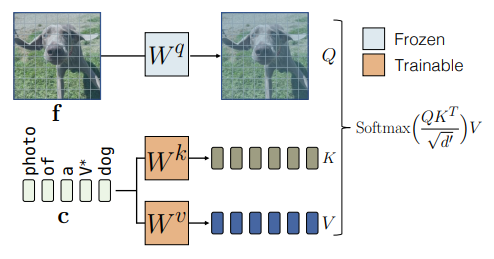
⇒ 빠른 학습 속도와 연산량을 크게 감소시킬 수 있으며, 개념 조합 시 간섭을 최소화시킬 수 있음
2) 텍스트 인코딩 (Text Encoding)
- 타켓 개념 이미지를 학습시키기 위해 텍스트 캡션을 함께 사용
- 개념에 대한 일반적인 단어가 존재할 경우 (ex. moongate) → 그대로 사용
- 개인화된 고유 인스턴스일 경우 (ex. 개인 반려견) → 새로운 modifier 토큰 임베딩 도입
- : 희귀 토큰 임베딩으로 초기화 + , 와 함께 동시에 최적화
⇒ 기존 단어 임베딩 공간을 오염시키지 않고, 새로운 개념을 독립된 식별자로 주입할 수 있다.
3) 정규화 데이터셋 구축
- 타겟 개념 이미지와 텍스트 쌍만으로 미세조정을 수행할 경우, language drift, 의미 누수, 과적합 같은 문제가 발생함.
- 이를 방지하고자 LAION-400M 데이터셋에서 타겟 텍스트와 유사도가 높은 캡션을 가진 실제 이미지 200장을 정규화 데이터셋으로 사용
⇒ 정규화 데이터는 기존 단어의 의미를 기억하고, 카테고리의 경계를 유지하며, 생성의 다양성을 확보할 수 있음
4) 다중 개념에 대한 공동 학습 & 개념 병합을 위한 최적화 전략
-
다중 개념 공동 학습 (Joint Training)
- 각 개별 개념에 대해 구성된 데이터셋을 하나로 결합
- 각 타겟 개념을 구분하기 위해, 서로 다른 modifier 토큰 를 사용
- 서로 다른 희귀 토큰으로 초기화
- , 와 함께 최적화
⇒ 개념 간 간섭 없이 두 개 이상의 새로운 개념을 안정적으로 조합할 수 있음
-
개념 병합을 위한 최적화 (Optimization to merge concepts)
- 이 논문에서는 , 만 업데이트 하기 때문에, 여러 개념 모델을 수식적으로 하나의 모델로 병합할 수 있음
- 개념 병합은 제약된 최소자승 문제로 정식화:
- 타겟 개념에 대해선 fine-tuned 매핑을 정확히 만족시키고,
- 정규화 텍스트에 대해선 pre-trained 모델과 최대한 유사하게 유지시키는 수식
- 이 문제는 닫인 형태(closed-form) 해를 가짐
- 라그랑주 승수법을 통해 약 2초 내로 병합이 가능
⇒ 공동 학습 없이도 다중 개념 조합이 가능하고, 실용적인 배포 및 확장에 유리함
4. Experiment Analysis
1) 단일 개념 미세조정 성능 및 효율성
- Custom Diffusion은 단일 개념 생성에서 DreamBooth와 동등한 수준의 시각적 품질을 달성
- Textual Inversion 대비 더 높은 text–image alignment + 더 정확한 시각적 디테일 보존
- CLIP 기반 정량 지표: 대부분의 데이터셋에서 최상 또는 비슷한 성능
- KID 평가 결과: 타겟 개념에 대한 과적합이 적음 + 기존 관련 개념의 의미 보존 효과 확인
- 계산 효율: 학습 시간 약 6분 + 저장 파라미터 적음 + DreamBooth 대비 5배 이상 빠르고, 저장 용량은 매우 작음
2) 다중 개념 조합 능력 (Compositionality)
- 두 개의 새로운 개념을 하나의 장면에서 조합하는 실험에서 대부분의 설정에서 Custom Diffusion이 가장 안정적인 결과를 생성
- DreamBooth
- 전체 파라미터 업데이트로 인해 개념 간 간섭 발생
- 하나의 개념을 누락하거나 왜곡하는 사례 다수
- Textual Inversion: 표현력 부족으로 조합 성능이 크게 제한
- 순차 학습(sequential fine-tuning): 첫 번째 개념이 사라지는 catastrophic forgetting 발생
⇒ 다중 개념 문제에서는 많은 학습보다 cross-attention의 K, V만 선택적으로 학습하는 구조적 제약이 핵심
3) Human Preference Study 결과
- 단일,다중 개념 모두에서 Custom Diffusion이 기존(DreamBooth, Textual Inversion)보다 높은 선호도
- 즉, 모든 파라미터를 학습한 모델보다 K, V만 학습한 모델이 더 선호된다고 볼 수 있음
⇒ CustomDiffusion은 단순한 근사법이 아니라, 사람이 보기에 더 자연스럽고 텍스트에 충실한 결과를 생성
5. Significance of Paper
1) 개념 커스터마이징 문제를 구조적 관점에서 재정의
- 기존 방법은 모델 전체를 미세조정하거나 새로운 토큰만 학습하는 경험적 방식에 의존하였음
- 본 논문은, 텍스트 의미가 실제로 이미지 생성에 주입되는 위치는 cross-attention뿐이라는 점에 주목
- 파라미터 변화량 분석을 통해 새로운 개념 학습의 핵심이 cross-attention의 K/V 매핑에 있음을 정량적으로 입증
⇒ 개념 커스터마이징을 ‘얼마나 더 학습할 것인가’가 아닌 → ‘어디를 학습해야 하는가’의 문제로 전환했음
2) 성능을 유지하면서도 효율적인 개념 학습이 가능함을 보여줌
- 기존 T2I diffusion 모델은:
- DreamBooth: 성능은 좋지만 학습,저장 비용이 큼
- Textual Inversion: 효율적이지만 표현력이 제한됨
- 하지만 Custom Diffusion은
- 단일 개념에서 DreamBooth와 동등한 품질
- 다중 개념에서 기존 방법보다 안정적인 조합 성능을 동시에 달성함
⇒ 이는 K, V의 선택적 업데이트 + modifier 토큰 + 실제 이미지 기반 정규화가 유기적으로 결합된 결과
3) 다중 개념 조합을 수식적으로 다룰 수 있음을 보여줌
- 이전까지는 여러 새로운 개념을 함께 학습하면 개념 간 간섭, 순차 학습 시 망각(catastrophic forgetting)이 발생했음
- Custom Diffusion 개념을 파라미터 덩어리가 아닌 텍스트–latent 매핑 과정으로 해석
- 이것을 결국 개별적으로 학습된 개념들을 ‘제약 최적화 문제’로 병합했고 닫힌 형태라는 해법까지 제시
⇒ 다중 개념 커스터마이징을 경험,직관의 의존이 아닌 구조적으로 다룰 수 있는 문제로 만들었음
6. Questions
1) 다중 개념 최적화 기반 방법의 이해
- 논문에서는 여러 개의 개념을 하나의 모델로 통합하기 위해 다중 개념 최적화 기반 방법을 제안하고, 이것을 제약 조건이 있는 최소제곱 문제로 풀어낸다.
- 처음 이 수식을 처음 접했을 때, 이 과정이 정확히 어느 시점에 적용되는지 명확히 이해되지 않았다. 처음에는 fine-tuning 과정에서 일어나는 loss 계산과 비슷하다고 생각했다.
- 하지만 전반적인 구조를 떠올리면서 다시 정리해보니 각 개념에 대해 개별적으로 fine-tuning된 결과들을 하나의 모델로 병합하기 위한 목적 함수로 이해하는 것이 더 자연스럽다고 생각했다.
- 즉, 여러 fine-tuned 모델이 만들어낸 결과를 만족하도록 조건을 만족하는 새로운 가중치 를 계산하는 후처리 병합 단계로 이해했고, 이것이 저자의 의도에 대한 올바른 이해인지 궁금했다.
2) 수식 유도 과정의 이해(Appendix B)
-
다중 개념 병합을 위한 최적화 수식을 이해하는 과정에서 1) Frobenius Norm, 2) ‘퇴화되지 않음’ 이라는 개념이 생소하게 느껴졌다.
-
에서의 Frobenius Norm의 의미
- 먼저 Frobenius Norm이란 행렬의 전체적인 크기를 측정하는 방법이다. 이걸 위 개념에 적용해보면, 새 가중치 가 일반적인 텍스트 분포()에 대해 기존 모델 와 얼마나 비슷하게 동작하는지를 한 번에 측정하는 것이라고 이해했다.
- 즉, 특정 단어나 일부 차원에만 집중하는 것이 아닌, 모델의 전체적인 출력 차이를 밸런스 있게 비교하기 위해 Frobenius Norm이 사용되었다고 이해했다.
-
‘가 퇴화되지 않았음을 가정한다’의 의미
-
‘퇴화되지 않음’이라는 개념이 생소해 추가로 찾아보았고, 에 포함된 텍스트 정보들이 충분히 다양하여 서로 중복되거나 정보가 사라진 상태가 아니라는 가정임을 이해했다.
-
논문에서는 단순히 형식 해법
을 제시하면서 가 퇴화되지 않았음을 가정한다. 하지만 위 수식에서 ‘퇴화되지 않음’의 개념을 어떻게 연결해서 이해해야 할지 다소 어려움을 느꼈다.
-
또한 이러한 ‘형식 해법’은 해당 조건이 만족될 때만 유효한데, 만약 가 퇴화(degenerate)될 가능성이 존재한다면 어떤 문제가 발생하는지에 대한 의문도 함께 들었다.
-
7. Future Directions
어려운 조합(composition) 생성의 실패 개선해보기
1) 현재 문제점
- Custom Diffusion은 어려운 조합(composition) 생성 상황에서 성능 저하가 빈번히 관찰됨:
- 개인화된 dog와 cat을 같은 장면에 생성하는 경우
- 세 개 이상의 새로운 개념을 동시에 조합하는 경우

2) 원인 분석
- Attention Map을 분석한 결과, dog 토큰과 cat 토큰의 attention map이 latent 공간에서 유사하거나 크게 겹친다는 사실이 확인된다
- 이는 Custom Diffusion의 문제라기보다, 사전 학습된(pre-trained) diffusion 모델이 이미 해당 조합에 약하고, fine-tuned 모델이 이러한 한계를 그대로 상속(inherit) 한 결과로 해석할 수 있다
- 즉, 기존 T2I diffusion 모델은 여러 개체를 명확히 분리하여 이해하고 배치하는 능력이 구조적으로 부족한 상태이다

3) 개선 전략: Object-level 중간 표현 도입
- 현재 구조는 dog와 cat 토큰이 공간적으로 분리된 개체로 인식되지 못하고 있는 것 처럼 보였다
- 이를 개선하기 위해 object 단위의 중간 표현을 도입하는 방향을 고민해보았음
- 기존 구조: object token → image latent
- 제안 구조: object token → object latent → image latent
- 각 개체를 담당하는 object 레벨의 latent 공간을 먼저 구성해서 이들을 통합하여 최종 이미지 latent를 생성하도록 하게 하는 방법
- 즉, 각 개체를 위한 일시적인 저장 공간, 전용 슬롯 역할을 도입해볼 수 있을까? → 이를 통해 dog와 cat의 객체나 세 개 이상의 객체들이 이미지 생성 이전 단계서부터 서로 구분된 상태로 유지되게 할 수 있을까?
4) Pros & Cons
- Pros: 기존 diffusion 모델의 근본적 한계(compositional bottleneck)를 직접 완화할 수 있음, 수식이나 구조의 큰 변경 없이 개선해볼 수 있음
- Cons: 추가적인 모듈이 필요함에 따라 모델 구조가 다소 복잡하고 무거워질 수 있음, 학습 안정성에 대한 검토가 필요함
8. Feedback
1️⃣ 다중 개념 최적화 식은 '학습(loss)'이 아니라 '병합(merge)' 단계
처음엔 저 식이 fine-tuning 과정에서 쓰이는 loss처럼 보여서 헷갈렸는데, 교수님 피드백에 따르면 fine-tuning이 아니라 여러 fine-tuned 모델(개념)을 하나로 합치는 병합 단계에서 사용하는 목적식이라고 한다.
즉, 내가 “개별로 튜닝된 결과들을 만족하는 새로운 𝑊를 후처리로 계산하는 단계”로 이해했던 방향이 맞는 것 같다.
2️⃣ Frobenius norm / non-degenerate 가정에 대한 이해
Frobenius norm은 특별한 의미가 있다기보다는, 행렬 수준의 L2 norm 정도로 보면 된다고 한다. 결국 목적은 결과가 와 전체 단어들에 대해 전반적으로 유사하게 동작하도록 만들려는 것이라고 이해하면 될 것 같다.
또한 non-degenerate는 한 마디로 데이터가 충분히 다양해서 정보가 겹치거나 사라지지 않는 상태를 의미한다고 한다. 일반적으로 빅데이터 환경에서는 특수한 경우가 아니면 이 다양성이 충분하다고 가정할 수 있고, 딥러닝에서 “배치에 다 똑같은 샘플만 들어갈 확률이 거의 없다”는 직관과 비슷하다고 이해하면 될 것 같다.
반대로 이 가정이 깨지면(퇴화되면) 같은 항이 안정적으로 역행렬/해를 갖기 어려워져서, 논문에서 제시한 closed-form solution을 그대로 따르기 힘들다고 보면 된다고 정리했다.
3️⃣ 조합(composition) 실패 개선 아이디어에 대한 피드백
내가 제안한 “object latent를 따로 두고 object token → object latent → image latent로 가자”는 방향은, 교수님 입장에서는 개념이 아직 모호하게 느껴질 수 있다는 피드백이었다.
사실 object token의 벡터 자체를 object latent라고 부를 수도 있기 때문에, 내가 말한 “추가적인 object latent”가 기존 token embedding과 어떤 점에서 다르고 어떤 형태를 가질 수 있는지 더 구체화가 필요하다는 의미로 이해했다.
다만, 여러 객체의 attention map이 서로 겹쳐서 조합 생성이 깨지는 문제 자체는 실제로 자주 관찰되는 현상이고, 이를 해결하려는 연구들도 존재한다고 한다. 참고할 만한 관련 연구로 아래 논문을 추천받았다.
- Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment (NeurIPS 2023)
