CVPR 2025.
SeungJu Cha, Kwanyoung Lee, Ye-Chan Kim, Hyunwoo Oh, Dong-Jin Kim
Hanyang University, South Korea
10 Jun 2025
💡 Key Point
상호작용 단어 ↔ 객체 간의 편향(bias)를 완화시켜 상호작용 이해 능력을 향상시키는 text-to-image diffusion 모델을 만들어보자!
1. Motivation
- 최근 text-to-image diffusion model은 사람 ↔ 객체 상호작용(verb) 표현이 부정확함
- <원인>
- CLIP Object Bias: 객체 중심으로 해석하는 경향 → 동사의 의미는 상대적으로 약하게 반영
- 기존 방법(InteractDiffusion, GLIGEN 등)은 bbox 같은 추가 조건에 의존
- 공간 정보는 제공하지만 동사 간 의미 차이를 이해하지는 못한다
- bbox가 비슷해지면 서로 다른 동사도 동일하게 표현되는 문제가 발생한다
⇒ 텍스트 단일 입력에서는 동사의 의미가 제대로 반영되지 않아 상호작용 표현이 낮은 상황
2. Insight
2.1. 사람-객체 쌍에서 anchor verb 편향이 발견된다
- 특정 human–object 조합은 특정 verb가 매우 높은 빈도로 등장
- ex) person – backpack 쌍에서는 → ‘wearing’이 높은 빈도
- 모델은 prompt verb보다 데이터의 빈도 패턴을 따라가려는 경향을 보임
- 입력 verb를 올바르게 반영하려면 anchor verb로부터 의미를 분리(disentangle) 해야 함
2.2. Cross-Attention Map은 상호작용의 영역을 포착한다
- StableDiffusion의 cross-attention map은 <h, r, o> 토큰이 가리키는 지역적 영역을 드러냄
- 토큰 attention의 centroid는 상호작용이 일어나는 실제 local region과 일치하는 경향
- 즉, bbox 없이도 상호작용 영역을 자동 추출할 수가 있음
- 이 통찰이 추후 소개될 IDG 모듈의 기반이 됨
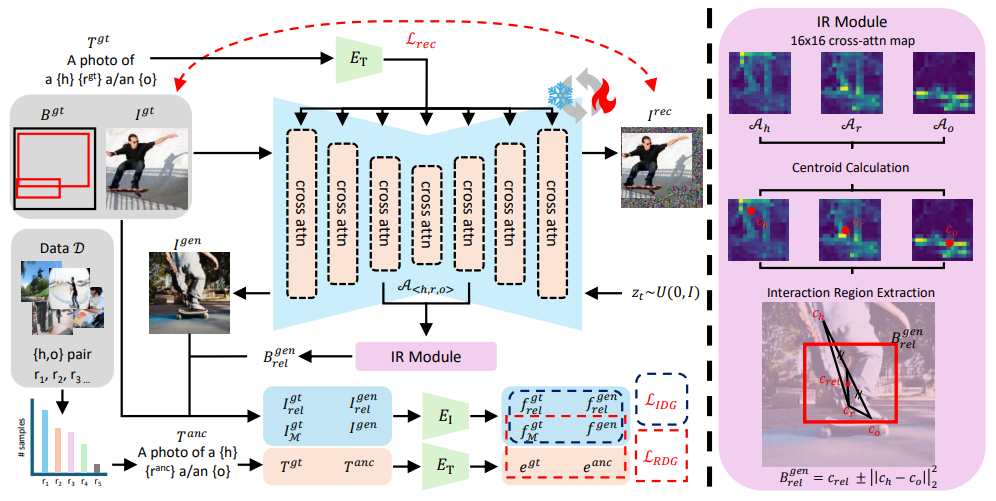
3. Method
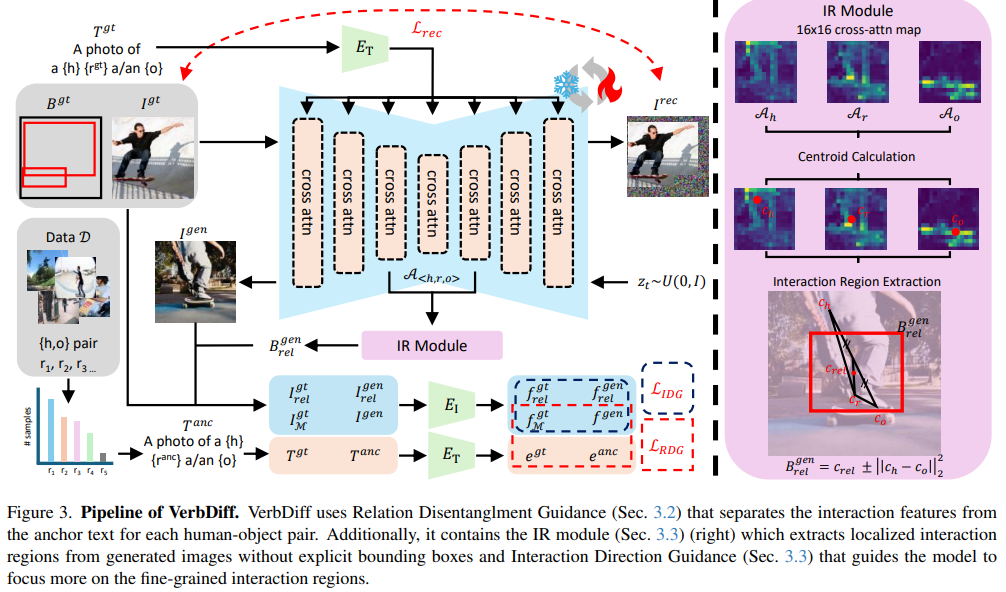
VerbDIff는 두 가지 핵심 아이디어로 동작함
1. RDG (Relation Disentanglement Guidance)
상호작용 동사의 의미적 차이를 제대로 학습하게 해주는 모듈
2. IDG (Interaction Direction Guidance)
모델이 이미지 속 상호작용이 실제로 일어나는 영역에 집중하도록 해주는 모듈
⇒ RDG로 텍스트의 의미를 명확히 반영하고 + IDG로 상호작용의 영역을 지정하는 구조
3.1. RDG: 상호작용 의미를 분리하고 편향을 줄이는 모듈
- 발단: 사람-객체 쌍은 특정 동사가 너무 많이 등장하는(long-tail) 경향이 있음, 모델도 이런 분포를
그대로 따라 가며 편향된 상호작용 이미지를 생성. - 아이디어: 모델이 정답 동사는 가까이 + 앵커 동사는 멀리 인식하도록 학습 (3가지 요소 적용)
-
Triplet Loss: 정답 동사 vs 앵커 동사 의미의 분리
-
Image Align Loss: 이미지 수준에서도 정답 상호작용과 가까워지도록 설계
-
Adaptive Scaling: 샘플 수가 적은 동사도 동등하게 학습되도록 스케일을 조정
-
- 최종 RDG Loss =
- 효과: 모델이 동사의 의미적 차이를 확실히 구분 + 텍스트 입력만으로 더 정확한 상호작용을 생성
3.2. IR Module: 상호작용 영역을 자동으로 찾아내는 모듈
- 발단: IDG를 적용하려면 사람, 객체, 둘이 상용하는 위치를 알아야함. but, 생성 이미지에는 bbox가
없어 자동으로 찾아야하는 문제가 발생 - 아이디어: cross-attention map이 각 토큰에 대응하는 객체(사람)의 위치를 포착한다는 사실을 발견
- 토큰 별 cross-attention map: 사람–객체 사이의 상호작용 영역을 추출
- 중심점 c 계산: 기존 맵은 연속적인 확률 분포 → 대표 지점을 추출해 정확한 상호작용 지점을 획득
- 토큰 별 cross-attention map: 사람–객체 사이의 상호작용 영역을 추출
- 효과: GT 이미지 / 생성 이미지 모두에서 사람이 객체와 상호작용하는 실제 위치를 얻을 수 있음
3.3. IDG: 모델이 상호작용 영역에 집중하도록 유도하는 모듈
- 발단: 모델이 이미지 전체를 수정하게 되면 상호작용이 의도치 않은 부분에 표현될 위험이 존재
→ 상호작용이 일어나는 지역에만 집중시켜야 함 - 아이디어: 실제 상호작용 영역 특징 ↔ 생성 상호작용 영역 특징의 방향 차이를 계산, 생성 이미지의 전체 수정 방향을 이 영역 기반 방향에 맞추도록 유도
- 최종 상호작용 영역: 사람, 객체, 상호작용 동사 centroid를 조합해 계산
- 편향된 상호작용 방향: 실제 상호작용 영역 특징 - 생성 상호작용 영역 특징
- 최종 상호작용 영역: 사람, 객체, 상호작용 동사 centroid를 조합해 계산
- 최종 IDG Loss =
- 효과: 모델이 ‘상호작용 부분’만 정확히 수정, 디테일한 차이가 더욱 잘 반영됨
3.4. 전체 Loss 결합
- Masked Reconstruction Loss: 특정 사람-객체 상호작용만 학습하게 함
- 최종 Loss =
- 왜 cross-attention만 학습? → 상호작용 정보는 cross-attention에서 잘 포착됨 + UNet 전체를 학습하는 것보다 더 효율적이고 안정적.
4. Experiment Analysis
1. Similarity Metrics
- S-BERT에서 모든 모델 중 최우수 → 동사의 의미를 더 명확히 학습했다는 의미
- VQA-Score에서도 SD보다 우수 → 복잡한 상호작용 문장도 정확히 해석 가능
- bbox 추가 조건을 사용하는 GLIGEN / InteractDiffusion 보다 더 뛰어난 성능
2. HOI Classification Accuracy
- 상호작용 인식 정확도가 모든 지표(Def/KO, Full/Rare)에서 최고
- 특히 Rare class에서 큰 폭으로 개선 → 다양한 verb도 robust하게 학습함을 의미
- 추가 조건을 쓰는 InteractDiffusion보다도 더 높은 정확도
3. Qualitative Results
- 기존 모델 대비 더욱 세밀한 상호작용 표현을 보여줌 + GT와 가깝게 생성해냄
- 대규모 T2I 모델인 DALL·E 3 수준과 비슷한 고품질 이미지를 생성함
- 복잡한 프롬프트(ex. jumping+throwing+blocking)에서도 각 토큰이 이미지에 명확하게 반영
5. Significance of Paper
1. 텍스트만으로 정확한 상호작용 이해 능력을 향상시킴
- 기존 모델들은 bbox, pose 등 추가 조건에 의존해야 상호작용을 표현할 수 있었음
- VerbDiff는 text-only 조건에서 verb의 미묘한 동작 차이를 정확히 생성
- 이는 ‘텍스트 기반 상호작용 이해’가 실제로 가능하다는 것을 보여준 논문
2. 기존의 Object Bias를 해소한 사례
- 기존 문제: CLIP이 객체 중심으로 학습되어 verb semantics가 약함
- VerbDiff는
- 빈도 기반 anchor verb를 정의
- anchor 의미와 입력 verb 의미를 tirplet + alignment로 구조적으로 분리
- 이것은 bias를 직접 조절한 접근 방식으로 text-to-image에서 verb 이해 문제를 해결하였음
3. Cross-Attention 맵을 상호작용 세부 지역 지정에 활용
- 기존 연구는 interaction region을 얻기 위해 bbox나 pose 정보가 필요
- VerbDiff는 cross-attention의 <h, r, o> token 중심점만으로 실제 상호작용이 발생하는 지역적 영역을 자동 추출
- 이는 cross-attention 자체가 상호작용의 공간적 단서를 충분히 담고 있다는 것을 증명
6. Questions
1. CLIP의 Object-Bias에 대한 고찰
- 논문을 읽어보면, Stable Diffusion의 텍스트 인코더인 CLIP은 프롬프트에서 ‘객체’에 집중하고 ‘동사’는 간과하려는 경향인 object-bias가 존재한다.
- 여기서 떠오른 궁금증은, 왜 CLIP은 동사를 약하게 처리하고 객체에 집중하는가에 대한 근본적인 이유(아키텍처 때문인지, 데이터 구성 때문인지)가 궁금했다. 이를 확인하기 위해 CLIP을 다시 리뷰해보았고, 스스로 추론해보았던 점은 CLIP 학습에 사용된 웹 텍스트의 구성이 대부분 ‘pepper the aussie pup’, ‘a person with a hat’같이 동사의 포함 정도가 빈약했던 이유라고 생각했다.
- 여기서 생각을 확장하여, 만약 기존 CLIP을 훈련할 때 단순한 객체 묘사 문장이 아닌, 인간–사물 간 상호작용이 명확히 포함된 이미지-텍스트 쌍으로 학습한다면 동사 이해 능력을 강화할 수 있지 않을까?(이미 이런 연구가 있지 않을까?) 라는 의문이 생겼다. 그리고 동사 이해력이 개선된 CLIP 텍스트 인코더를 Stable Diffusion에 결합하여 VerbDiff와 비교한다면, 상호작용 표현력에서 어떠한 성능적 차이가 나타날지도 함께 궁금해졌다.
2. LDM과 VerbDiff의 어텐션 맵의 차이점
- Stable Diffusion과 VerbDiff는 모두 텍스트 조건을 이미지에 반영하기 위해 cross-attention 기반의 조건화 방식을 사용한다.
- 여기서 떠오른 궁금증은, VerbDiff가 기존 Stable Diffusion보다 동사 정보에 대해 얼마나 더 효과적인 attention 가중치를 학습했는가였다. 즉, 두 모델의 cross-attention map을 비교해보면, 어떤 텍스트 토큰(명사 vs 동사)이 UNet 내부 attention에서 더 큰 영향력을 가졌는지 직관적으로 이해할 수 있었을 것 같았다.
- 따라서 VerbDiff가 기존 T2I 모델의 조건화 방식을 얼마나 효율적이고 선택적으로 개선했는지, 그 변화가 attention map 차원에서 어떻게 나타나는지에 대한 평가를 시도해본다면, 모델의 구조를 이해하는 데 도움이 될 것이라고 생각했다.
7. Future Directions
1. 객체-객체간의 정확한 상호작용 표현도 개선할 수 있을까?
1.1. 논문에서의 개선 포인트
- VerbDiff는 human - verb - object 구조의 상호작용 표현을 향상하는데 집중
- 상호작용 이해는 사람 중심으로 설계
- 관계 표현은 human-object pair의 동작(holding, pushing, riding 등)에 최적화
1.2. 방향성의 확장
- 사람에 종속되지 않은 일반적인 관계 모델로 확장하는 아이디어
- 객체끼리의 관계인 object - verb - object 구조를 추가
- 충돌, 밀기, 흔들리기 같은 객체 간의 동적 움직임까지 포함하는 general한 모델로 발전 가능
1.3. 아이디어 포인트
- 객체-객체 쌍의 높은 빈도 verb를 앵커로 재설정
- IR 모듈을 <o, r, o> 토큰에 맞춰 일반화
- 기존 방법과 비슷하게, cross-attention map에서 두 객체 중심과 작용 중심을 추출
1.4. Pros & Cons
- Pros: 사람 중심의 상호작용을 넘어서 더 일반적인 상호작용 장면을 이해할 수 있음 / 로봇,물체,자연요소 등 다양한 상호작용 생성으로 확장이 가능
- Cons: HICO-DET처럼 적합한 평가 데이터셋의 유무의 불확실성 / object-object에서는 상호작용 표현이 이미 현재 수준에서 잘 이루어지는지 확인이 필요
2. 부사(adverb)가 포함된 텍스트도 이미지에 정확히 표현할 수 있을까?
2.1. 논문에서의 개선 포인트
- VerbDiff는 상호작용하는 ‘동사’를 정확하게 이미지에 표현하려고 한 시도
- 동사 간의 차이는 정확히 구분해내지만, 부사 표현이 붙은 디테일한 차이에 대해서는 불명확
2.2. 방향성의 확장
- 동사 level의 상호작용을 넘어 동적의 강도, 스타일, 속도, 분위기까지 반영해보자
- pushing forcefully / carefully carrying / twisting hard 같이 (부사+동사) 텍스트의 정확한 상호작용을 모델링해보는 것
2.3. 아이디어 포인트
- 동사와 부사를 따로 이해하도록 텍스트 표현을 분리해서, ‘무엇을 하는지(동사)’와 ‘어떻게 하는지(부사)’를 독립적으로 이해하도록 만들기
- cross-attention에서 부사적 표현이 더 잘 드러나도록 가중치를 조정
- Sentence-BERT처럼 의미 차이를 잘 구분하는 텍스트 모델을 활용해 carry와 carefully carry의 의미적 차이를 모델이 알 수 있게 하는 구조
2.4. Pros & Cons
- Pros: 단일 동사보다 더 풍부한 행동 스타일을 표현할 수 있음 / 기존 VerbDiff를 fine-grained한 모델로 향상시킬 수 있음
- Cons: 정적 이미지에서 ‘부사 표현’ 이라는 것은 모호할 수 있음(시작적 신호가 부족함) / modifier별 ground-truth를 수집할 수 있는지 불명확
8. Feedback
1️⃣ CLIP의 Object-Bias와 동사 이해 문제
CLIP의 동사 이해를 근본적으로 개선하려면 동사 중심 데이터로 재학습하는 것이 가장 직접적인 방법일 것 같지만, CLIP의 대규모 학습 비용을 고려하면 현실적으로 부담이 크다는 점을 다시 생각하게 되었다.
결국 중요한 질문은, CLIP을 다시 학습하지 않고 동사 이해 능력을 어떻게 보완할 수 있을 것인가로 정리될 수 있을 것 같다. 구조 변경보다는 조건화 방식이나 표현 수준에서의 보완이 더 현실적인 접근일 수 있다는 생각이 들었다.
2️⃣ 상호작용 표현의 확장: 객체 관계와 부사 이해
객체-객체 상호작용 확장과 부사(adverb) 이해 문제는 모두 상호작용 표현의 정밀도를 높이는 문제로 볼 수 있을 것 같다.
다만 객체-객체 확장은 독립적인 기여로 보기에는 다소 제한적일 수 있으며, 기존 모델의 확장 실험 형태가 더 적절해 보인다.
부사 이해 문제는 아직 충분히 해결되지 않은 어려운 과제로, 단순한 구조 변경보다는 자연어 의미 표현 능력과 연결된 문제라는 점을 다시 정리하게 되었다.
