
Light Weight Deep Learning
헬스맨들이 좋아하는 Right weight 이 아니다, 딥러닝 경량화라는 것이다.
딥러닝 경량화란 딥러닝의 층 수가 깊어지고, 하이퍼 파라미터의 갯수가 많아지면서
방대해진 연산량을 줄이기 위한 연구입니다.
경량화를 하는 이유는 딥러닝을 real time으로 작동시키기 위한 목적이 큽니다.
또한 메모리를 많이 차지하기 때문에 필요 메모리 양을 줄여, 메모리가 적은
환경에서도 작동되도록 메모리를 줄이는 이유도 있습니다.
이렇게 딥러닝 경량화 연구를 통해 GPU환경이 아닌 모바일, 엣지 디바이스,
클라우드 등에서도 딥러닝 모델을 사용하는 방법을 찾고 있습니다.
이러한 이유들 때문에 최근 발표된 논문들은 평가 척도에 모델 효율성이 반영되기 시작했습니다.
더는 정확도, 속도만이 중요한 것이 아니라 효율성도 중요해진 것입니다.
방법론
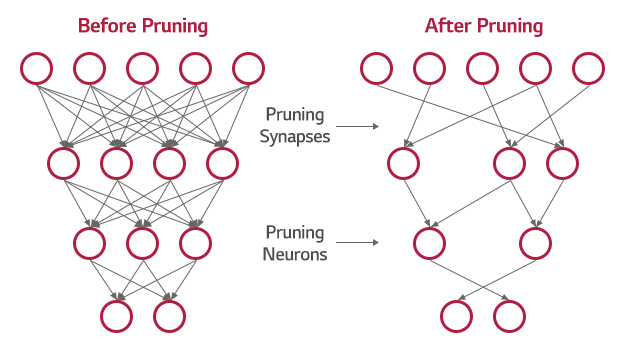
1. 가지치기(Prunning)
신경망은 수많은 노드와 가중치의 연산을 통해 다음 노드로 전달되는 형태로 구성되어있다.
그럼 과연 그 모든 노드가 필수적일까?
그렇지 않기 때문에 가지치기라는 방법론이 존재한다.
신경망 학습에 중요성이 낮은 노드를 제거하고 재학습하는 과정을 통해 모델의 크기를 줄이는 방법론이다.
2. 지식 증류(Knowledge Diostillation)
기존에 학습이 잘 된 아주 큰 딥러닝 모델과 학습하기 전의 작은 모델이 있다면,
큰 딥러닝 모델은 작은 모델에게 학습에 도움을 줄 수 있지 않을까 라는 생각에서 출발합니다.
큰 모델을 Teacher 모델, 작은 모델을 Student 모델이라고 부를때,
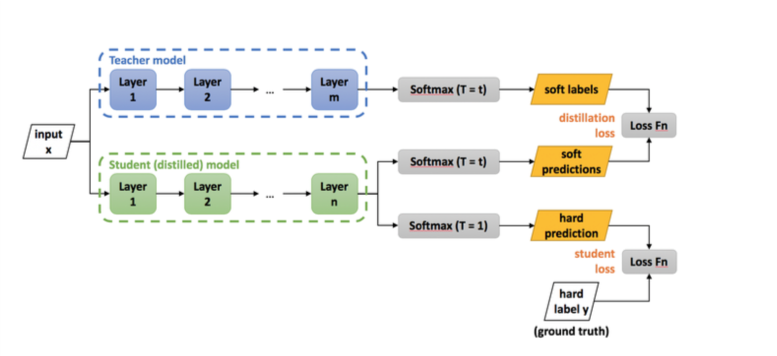
위 그림에서 입력으로 들어온 이미지를 Teacher 모델과 Student 모델이 동시에 입력으로 받으면 Teacher모델은 아주 잘 예측하고 Student 모델은 그렇지 않을 것입니다.
이 때, Teacher 모델의 softmax 함수로부터 휙득한 확률들을 정답으로 확정하고, Student 모델에서 얻은 확률들과 비교하여 Loss를 구합니다.
이러한 방식을 Soft Label이라고 부르고, 사람이 정해놓은 정답을 Hard Label이라고 부릅니다.
Soft Label은 확률 값들이고, Hard Label은 0과 1로 이루어졌다는 차이점이 있습니다.
특이하게도, MNIST(숫자 손글씨 데이터)에 대해서 진행된 지식증류 실험에서는
숫자 7, 8 만을 학습한 Student모델이 한번도 보지 못했던 1, 2, 3, 4, 5, 6, 9 를 87퍼센트의 정확도로 예측했습니다.
이런 점에서 Soft Label 방식의 지식 증류 기법은 굉장히 효율적으로 느껴지는데,
Object Detection 의 경우에서는 단순 분류가 아니라 Bounding Box에 대해서도 추정을 해주어야 해서 방법이 매우 복잡해집니다.
이러한 점 때문에 다른 경량화 방법들에 비해서 지식증류 기법은 연구 속도가 더딘편이며 주로 데이터셋을 합성하는 방향으로 발전되는 추세라고 합니다.
3. 양자화(Quantiztion)
신경망 모델에서 사용하는 파라미터는 모두 완전 정밀도 타입(FP32)를 사용한다
FP32란 Floating Point 32의 약자로, 32 bit로 표현하는 방식입니다.
이렇게 큰 비트로 표현하는 파라미터는 연산량이 클 수밖에 없습니다.
이러한 변수를 int 8bit로 바꿔주게 되면 기존의 모델의 4분의1배로 줄일 수 있습니다.
이렇게 되면 기존에 모델을 사용할 수 없었던 디바이스에 양자화한 모델을 넣을 수 있습니다.
연산 자체의 속도도 줄어들고 8비트만 지원하는 하드웨어에서도 사용이 가능합니다.
양자화에서도 종류가 분류되는데, QAT와 PTQ 두 가지 방법이 있습니다.
Quantization Aware Training(QAT)
학습 시에 양자화를 하는 방법. 학습 시에 실제로 int 8이 되는 것이 아니라, Quantization 수식을 사용하여 float 32 타입의 변수를 임의로 int 8 변수의 값이 되도록 매핑해서 학습을 진행하는 방식입니다.
학습 할 때 일부러 int 8과 같은 효과를 적용하면 이 환경에 맞추어서 학습이 되기 때문에 성능 방지 효과를 더 누릴 수 있습니다.
Post Training Quantization(PTQ)
Pretrained 모델을 바로 양자화 하는 방법으로, QAT보다 성능이 떨어지지만 PTQ를 하면서도 성능 방지를 하는 방법이 연구되고 있습니다.
