
크롤링?
사실 이 게시글을 보러 들어온 사람이라면 대부분 크롤링 이 뭔지 이미 알고있을 것이라고 생각된다.
크롤링이란 무수히 많은 컴퓨터에 분산 저장되어 있는 문서를 수집하여 검색 대상의 색인으로 포함시키는 기술. 어느 부류의 기술을 얼마나 빨리 검색 대상에 포함시키냐 하는 것이 우위를 결정하는 요소로서 최근 웹 검색의 중요성에 따라 발전되고 있다.
출처 - (IT용어사전, 한국정보통신기술협회)
가장 익숙한 방식으로는 Python 과 Selenium 을 이용해서 데이터를 수집하는 방식이다.
데이터 분석이나 머신러닝 학습을 하기 위해서는 데이터가 필요하다 그것도 대량의 데이터가.
이러한 데이터는 사실 학부생 입장에서는 공공 데이터 포털 같은 사이트나 캐글의 데이터셋을 이용하는 방법 외에는 찾기 힘들다. 그래서 직접 크롤러를 짜서 데이터를 크롤링하여 직접 전처리 후 분석하는 과정을 통해 학습하는 것이 좋다고 생각한다.
필요한 것은 Python 개발 환경, selenium설치, chromedriver이다
chromedriver 설치는
https://blog.naver.com/stochastic73/221682782447
위 링크를 참조하시길 바랍니다
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
import urllib.request
import time
driver = webdriver.Chrome("chromedriver.exe")#chromedriver를 사용하기위한 webdriver함수 사용
keyword = str(input("insert keyword for searching : "))#get keyword to search
driver.get("https://www.google.co.kr/imghp?hl=ko&authuser=0&ogbl")##open google image search page
driver.maximize_window()##웹브라우저 창 화면 최대화
time.sleep(2)
driver.find_element_by_css_selector("input.gLFyf").send_keys(keyword) #send keyword
driver.find_element_by_css_selector("input.gLFyf").send_keys(Keys.RETURN)##send Keys.RETURN
last_height = driver.execute_script("return document.body.scrollHeight") #initialize standard of height first
while True: #break가 일어날 때 까지 계속 반복
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") #페이지 스크롤 시키기
time.sleep(1)
new_height = driver.execute_script("return document.body.scrollHeight") ## update new_height
if new_height == last_height:#이전 스크롤 길이와 현재의 스크롤 길이를 비교
try:
driver.find_element_by_css_selector(".mye4qd").click() ## click more button 더보기 버튼이 있을 경우 클릭
except:
break # 더보기 버튼이 없을 경우는 더 이상 나올 정보가 없다는 의미이므로 반복문을 break
last_height = new_height ##last_height update
i=0
list = driver.find_elements_by_css_selector("img.rg_i.Q4LuWd")##thumnails list
print(len(list)) #print number of thumnails
address = str(input("insert your address : "))# 파일을 저장할 주소를 입력받기
for img in list:
i += 1
try:
imgurl = img.get_attribute("src") # get thumnails address list
time.sleep(1)
urllib.request.urlretrieve(imgurl,address+"/"+str(keyword)+str(i)+".jpg") # download images in address folder
except: #저장이 불가능할경우 그냥 pass
pass
먼저 전체 코드입니다
크롬 드라이버를 해당 프로젝트 폴더 안에 위치시켜주시고
driver = webdriver.Chrome("chromedriver.exe")코드를 사용하면 크롬드라이버를 사용할 수 있게됩니다.
웹드라이버를 driver라는 변수에 저장을 해주고,
keyword라는 변수에 검색하고싶은 검색어를 키보드로 입력받아서 저장합니다!
(input함수는 키보드를 통해 정보를 입력받는 함수입니다)
그리고 webdriver의 get메소드를 사용해서 원하는 페이지로 이동해줍니다.
get메소드는 인자로 str형태의 주소를 넘겨받아 그 주소로 웹페이지를 이동시킵니다!
driver.get("https://www.google.co.kr/imghp?hl=ko&authuser=0&ogbl")현재 get안에 들어있는 주소는 구글 이미지 검색의 주소입니다 해당 코드를 실행시키면
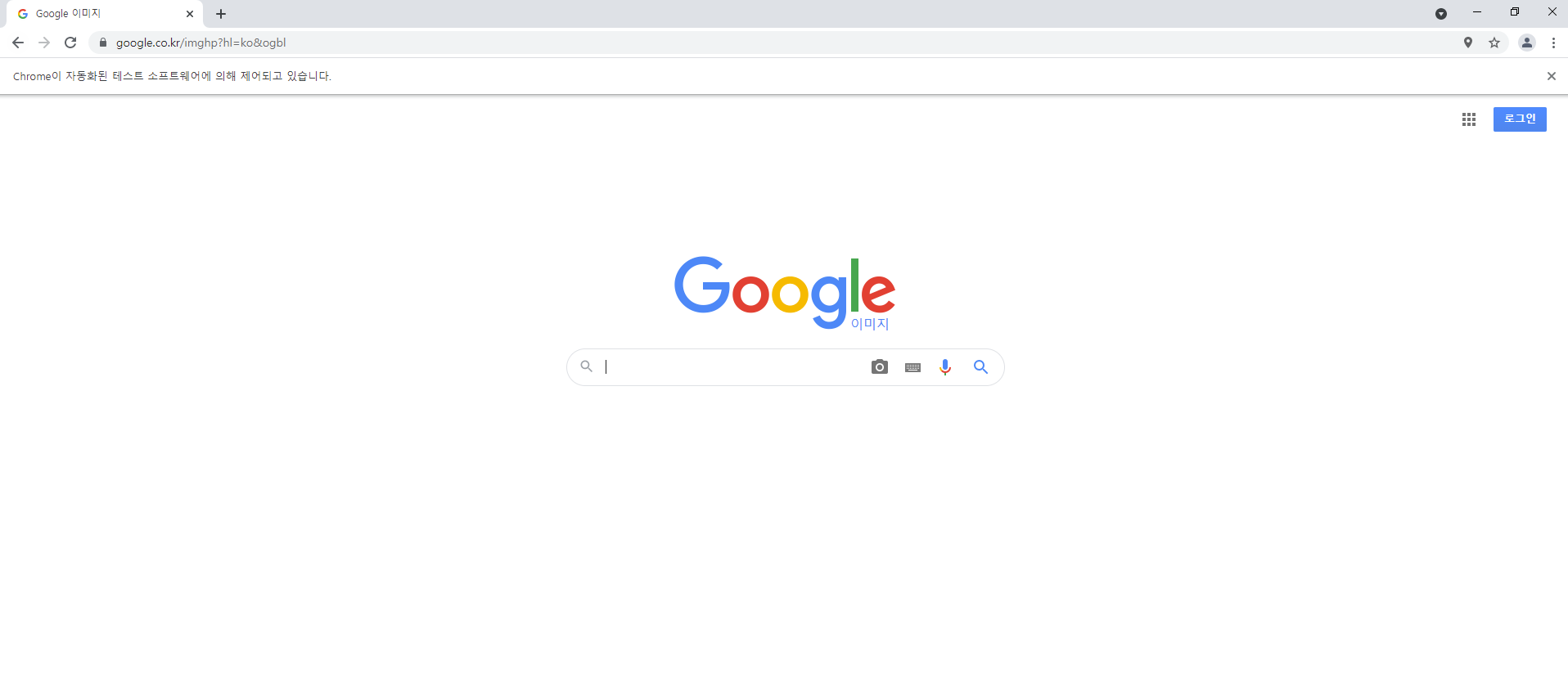
크롬이 실행되면서 구글 이미지 검색 페이지로 이동됩니다.
(주소창 밑에 chrome의 자동화된 테스트 소프트웨어의 의해 제어되고 있습니다. 라는 문구를 통해 chrome드라이버가 잘 작동중인 것을 알 수 있습니다.)
그렇다면 이제 driver의 다른 함수를 통해
페이지를 조작하는 방법을 알아볼 차례입니다!
Webdriver의 메소드들을 통해 현재 페이지의 html요소를 이용하여 웹 구성요소를 선택하고, 클릭하고, 입력하고, 구성요소중 특정 속성만 가져오는 등의 여러가지 행동을 할 수 있습니다.
그 중에서 css요소를 이용해서 특정 페이지 구성요소를 선택하는 방식이 있습니다.
find_element_by_css_selector()
사실 어느 개발언어를 사용하던지 대부분의 메소드는 이름을 통해서 기능을 유추할 수 있습니다.위 함수 또한 대~충 보면 css를 이용해서 구성요소를 찾는다는 이야기겠지 라고 생각할 수 있습니다.
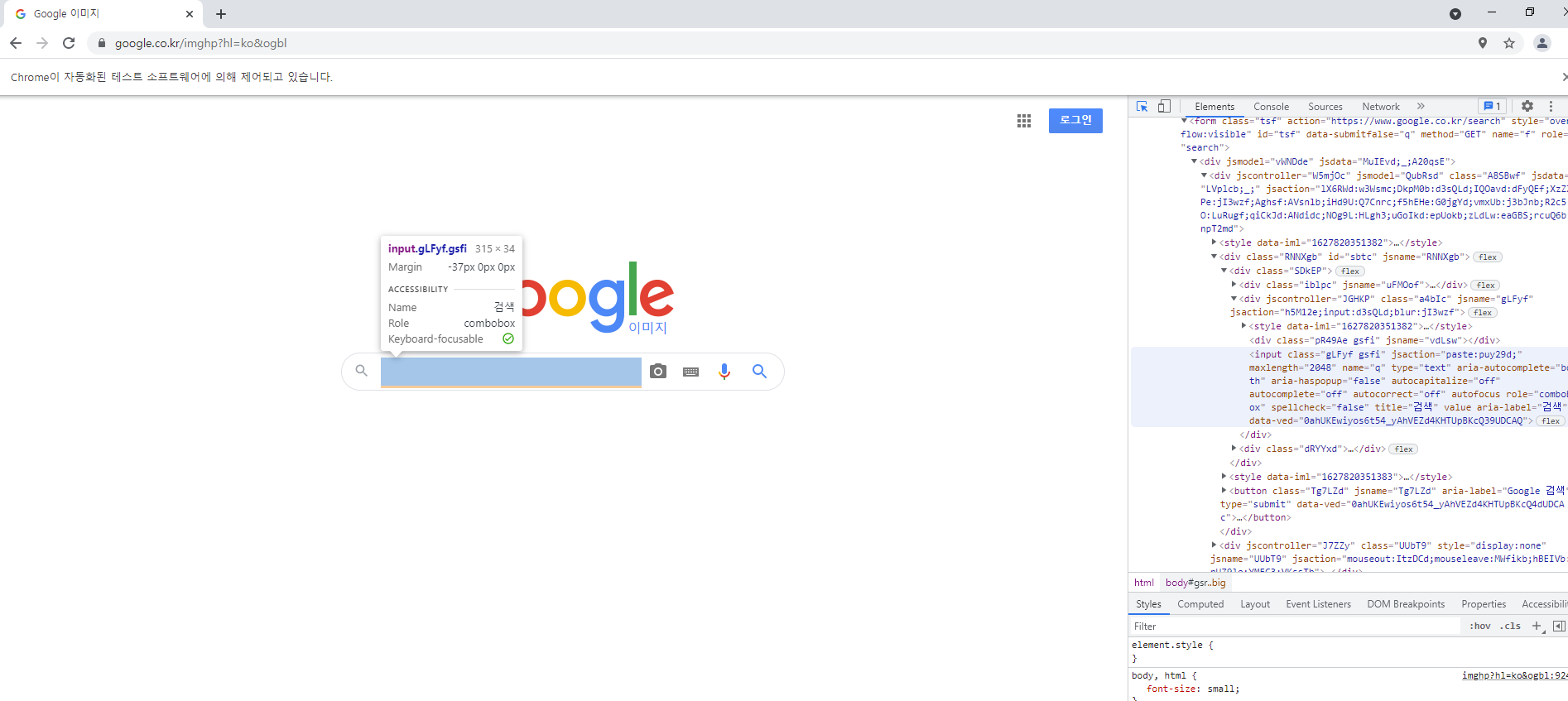
(아래 사진을 보면 f12버튼을 누르면 나오는 개발자모드에서 구성요소를 찾아서 해당 요소의 태그명과 class 혹은 id명을 찾을 수 있다!)
driver.find_element_by_css_selector("input.gLFyf").send_keys(keyword) #send keyword
driver.find_element_by_css_selector("input.gLFyf").send_keys(Keys.RETURN)컴퓨터가 구성요소를 찾기 위해서 내가 페이지에서 구성요소를 찾아서 컴퓨터에게 알려주는 것이다!
컴퓨터는 만능이지만 한번 떠 먹는 방법을 알려줘야지 앞으로 나중에 알아서 떠 먹을 수 있게 되는 것이라고 생각하시면 됩니다.
아무튼 이렇게 찾은 css요소들을 인자로 넘겨주어서 메소드를 호출하고 그 메소드들 속에 또 메소드
메소드속의 메소드속의 메소드속의 메소드를 이용하는 마트료시카 메소드들도 존재합니다
아무튼 send_keys()함수는 find 메소드를 이용하여 찾은 구성요소에게 key값을 보내주는 함수라고 이해하시면 되시겠읍니다.
css_selector를 통해 찾은 입력창에 keyword를 입력해주고 keys.RETURN을 통해서 엔터를 눌러주는 것과 같은 효과를 얻을 수 있습니다.(사실 정확하지않음ㅋㅋ)
다음은 이미지 검색 후 스크롤 해주는 부분!
이미지 크롤링을 하는 경우에는 대부분의 검색엔진을 제공하는 웹사이트가 이미지 검색 결과를 스크롤을 통해서 추가 결과를 보여줍니다.
저같은 경우 많은 데이터를 모으고 싶어서 최대한으로 스크롤을 내린 후에 모든 이미지를 저장하기 위해서 스크롤을 끝까지 내리는 코드를 사용했습니다.
이 부분의 코드는 유튜버 조코딩님의 영상을 참조했습니다.
last_height = driver.execute_script("return document.body.scrollHeight") #initialize standard of height first
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
new_height = driver.execute_script("return document.body.scrollHeight") ## update new_height
if new_height == last_height:
try:
driver.find_element_by_css_selector(".mye4qd").click() ## click more button
except:
break
last_height = new_height ##last_height updatedriver.execute_script() 위 함수를 통해서 현재 페이지의 스크롤 길이를 측정할 수 있습니다.
코드들의 인자들을 보면 0, document.body.scrollHeight 두개인 것을 확인할 수 있는데.
처음부터 현재 볼 수 있는 스크롤의 끝 위치를 통해 페이지의 스크롤 길이를 구하는 것입니다.
last_height 변수의 스크롤 길이를 저장하고
new_height 변수에 새 스크롤 길이를 저장해줍니다.
이 두 변수를 비교해주면서 스크롤을 내리다보면 두 변수가 같은 지점.
더 이상 스크롤을 내리지 못하는 지점을 찾을 수 있습니다.
이는 두가지 경우인데 스크롤을 하다보면 결과 더보기 버튼이 나오면서 스크롤을 더 내릴 수 없게됩니다. 이때는 스크롤이 멈추지만 결과가 더 있는 것이기 때문에 더보기버튼이 나오면 버튼을 눌러주는 코드를 통해 버튼을 눌러 결과를 더 출력하게 해줍니다.
버튼이 나오지 않는다면 정말 모든 결과가 나온 것 이므로 반복문을 종료합니다
그럼 이제 이미지를 저장할 차례입니다.
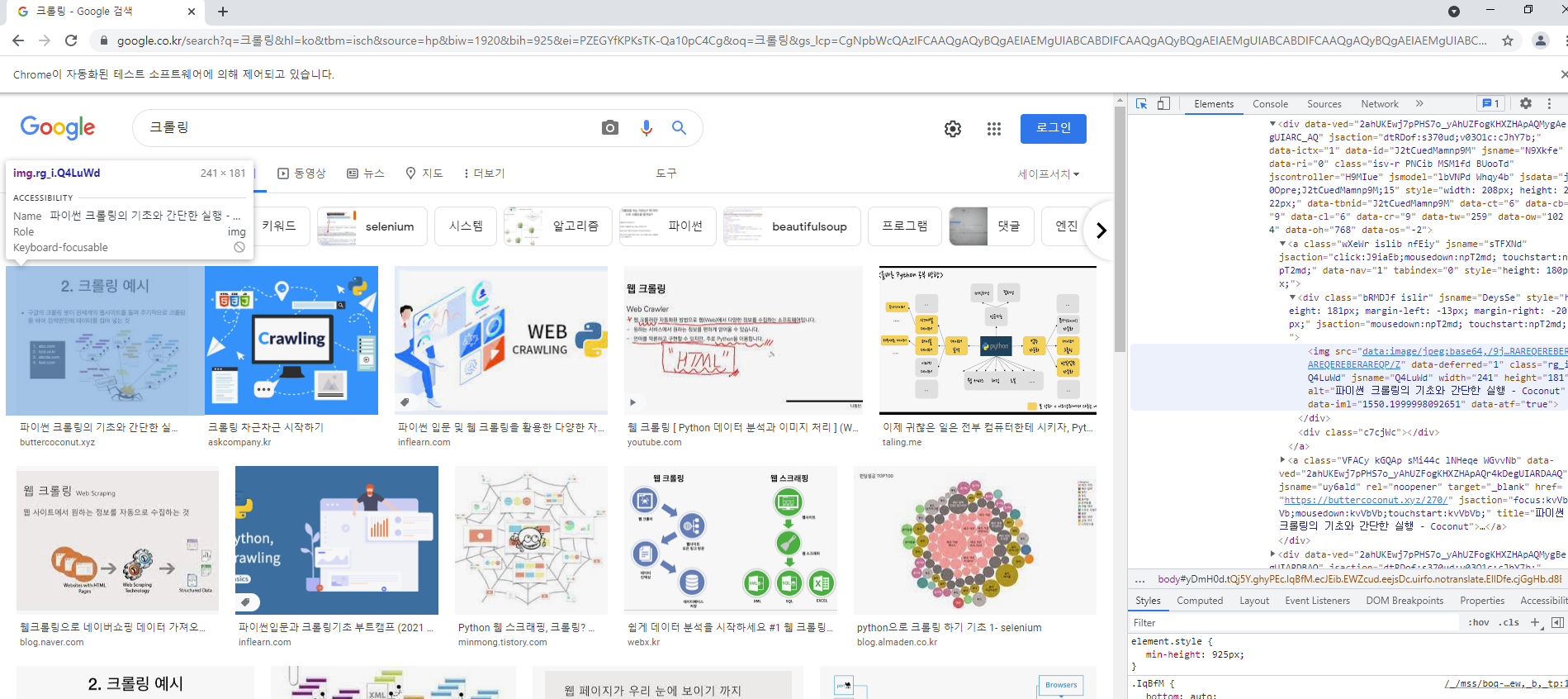
위 사진처럼 다시 개발자모드를 통해 사진들의 css요소를 찾아줍니다.
list = driver.find_elements_by_css_selector("img.rg_i.Q4LuWd")##thumnails listwebdriver의 find 종류의 메소드를 사용할 때 주의해줘야 할 포인트는 element와 elements의 구분입니다.
한개의 요소를 찾느냐, 같은 이름의 여러개의 요소들을 찾느냐의 차이로 많은 오류가 여기서 발생하곤 합니다.
오타가 나는 경우도 있고 요소를 정확히 찾지 못하고 사용하는 경우도 있으니 조심하셔야 합니다.
대부분의 검색 엔진 사이트들은 검색 결과 사진들의 css요소를 같이 설정하니 elements 함수를 이용하여 리스트에 저장해주고 사용해주면 좋습니다.
list[i].get_attribute("src")위 코드는 elements 함수를 이용해 찾은 구성요소들의 목록중에 i번째 구성요소를 골라서
get_attribute()함수를 이용해 src 속성의 값을 가져오는 함수입니다.
처음 보시는 분들은 이게 무슨소리인지 머리가 아파오실 수 있습니다.
그래서 상세하게 말씀드리자면
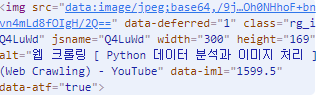
위 사진의 개발자 모드에서 img태그부분을 확대한 것입니다.
img태그의 속성들을 보여주고 있습니다.
(html의 기초인 태그와 속성에 관한 이해도가 부족하시다면 이 링크를 보시면 됩니다 https://thrillfighter.tistory.com/430)
src속성은 이미지의 주소값을 담고있는 속성이며 각 이미지들을 저장하기 위해 주소값만을 저장하고 싶어서 src속성의 속성값을 get_attribute()함수를 사용해 가져온 것 입니다.
get_attribute() 함수는 태그의 속성값을 지정하여 가져오는 함수로 src뿐만 아니라 다른 속성인 class나 id, width같은 다른 속성들의 값도 가져올 수 있습니다!
그럼 이제 반복문을 돌려서 list에 저장된 모든 이미지요소들의 src값을 뽑아올 수 있겠죠?
그럼 이제 마지막입니다.
address = "저장하고싶은 위치"
urllib.request.urlretrieve(url,address+"/"+str(keyword)+".jpg") # download images in address folderurilib.request의 urlretrieve()함수는 인자로 받은 url주소의 정보를 저장하는 함수입니다.
url주소와 파일을 저장할 위치와 파일이름, 그리고 파일의 형식을 인자로 넘겨주면 끝입니다!
(추가적인 urlretrieve함수의 사용법은 https://blog.naver.com/smartboy1989/222361844173 를 참조해주시기 바랍니다!)
이렇게 세부적으로 함수들의 사용방법을 알아보았는데 다시한번 위로 올라가 전체 코드를 읽어보면 이해하기가 쉬울 것 입니다.
해당 코드는 구글의 이미지검색 서비스를 통해 크롤링하는 코드이며 네이버나 다른 검색엔진을 사용하실 경우는 주소와 개발자모드에서 태그의 class를 다시 찾아서 바꿔주면 똑같이 이용할 수 있습니다.
