
이전 포스트의 크롤러
앞서 작성한 크롤링 프로그램은 구글 이미지 검색시 나오는 썸네일들을 크롤링하는 코드였습니다.
빠르고 쉽다는 장점이 있지만 사실 썸네일들은 픽셀이 압축된 이미지이기 때문에 화질이 좋지는 않습니다.
실제 썸네일을 크롤링한 결과와 원본 이미지를 크롤링한 결과 비교 사진입니다.
그럼 바로 수정된 코드를 보고 설명하겠습니다.

CODE
for img in list: ActionChains(driver).click(img).perform() time.sleep(1) imgurl = driver.find_element_by_xpath('/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img').get_attribute("src") try: urllib.request.urlretrieve(imgurl,address+str(keyword)+str(i)+".jpg") i+=1 except: pass
이전 코드에서 수정된 부분만을 가져왔습니다.(전체 코드는 이전 게시글에서 확인하시길 바랍니다)
먼저 바뀐점은 처음에 썸네일들을 css_selector 를 이용해서 찾은 list 에서 src 를 바로 추출하지 않는다는 점입니다.
다들 구글에서 검색을 해보셨다면 알겠지만 썸네일을 클릭하면 오른쪽에 원본사진이 크게 나옵니다.
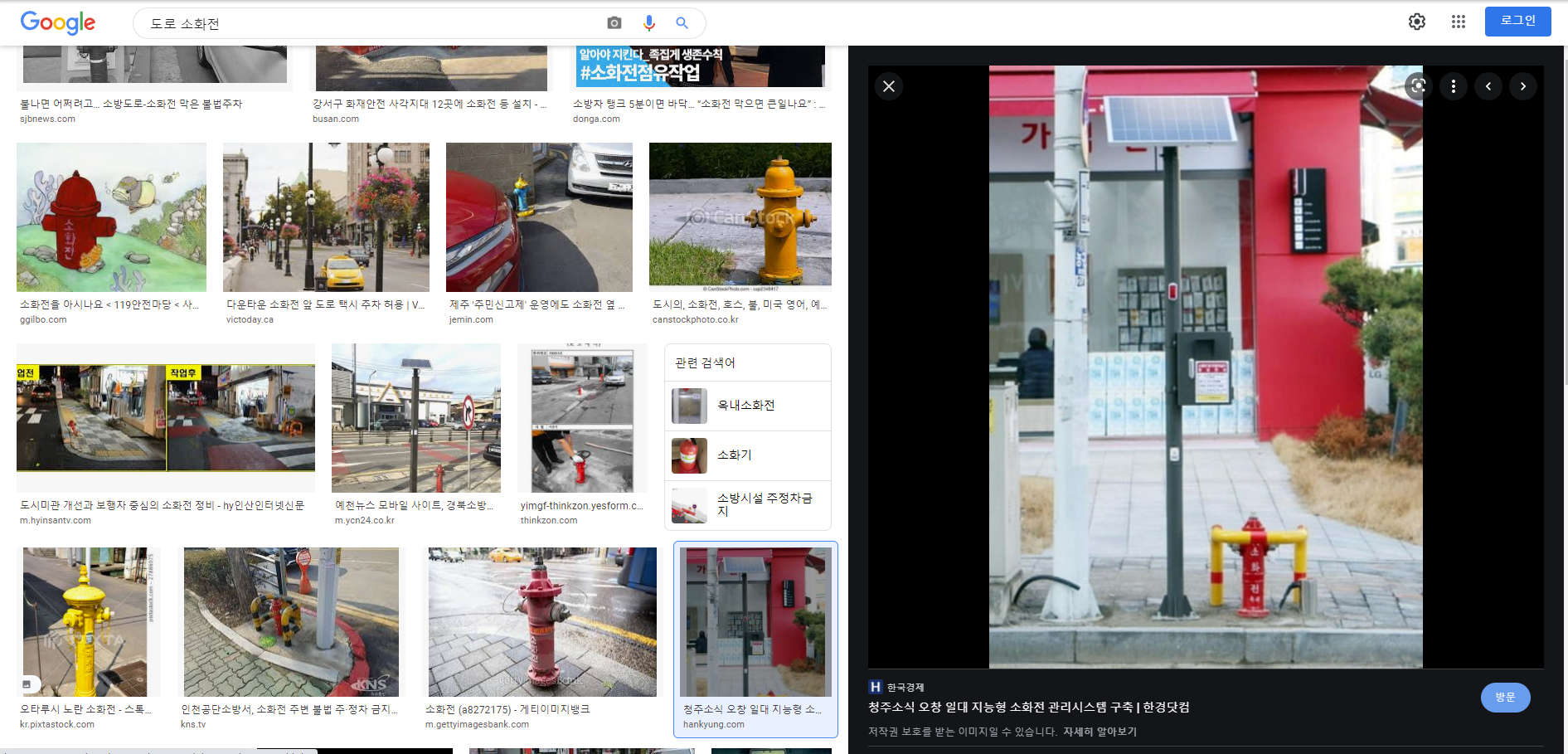
이런 화면을 나타내기 위해 ActionChains(driver) 을 사용합니다. Selenium 의 내장 함수로, 우리가 마우스나 키보드로 행하는 I/O 행위를 대신 해주는 코드를 구현할 수 있습니다.
ActionChains(driver) 를 사용해 list 내의 썸네일을 클릭합니다.
그 뒤 xpath 를 이용해서 원본 사진을 선택해줍니다.
xpath 란 html 의 개선된 버전인 eXtended Markup Language 의 줄임말인 XML 의 트리구조에서 특정 요소의 위치 경로를 나타낸 것입니다.
xpath를 사용한 이유는css를 이용해서 찾을 경우 같은class를 가진 요소가 여러개 존재하는 경우가 있어서 원하는 커다란 원본사진을 선택하지 못할 수 있기 때문입니다.
xpath 는 유일한 특정 요소를 가르킬 수 있기 때문에 이러한 문제를 방지할 수 있습니다.
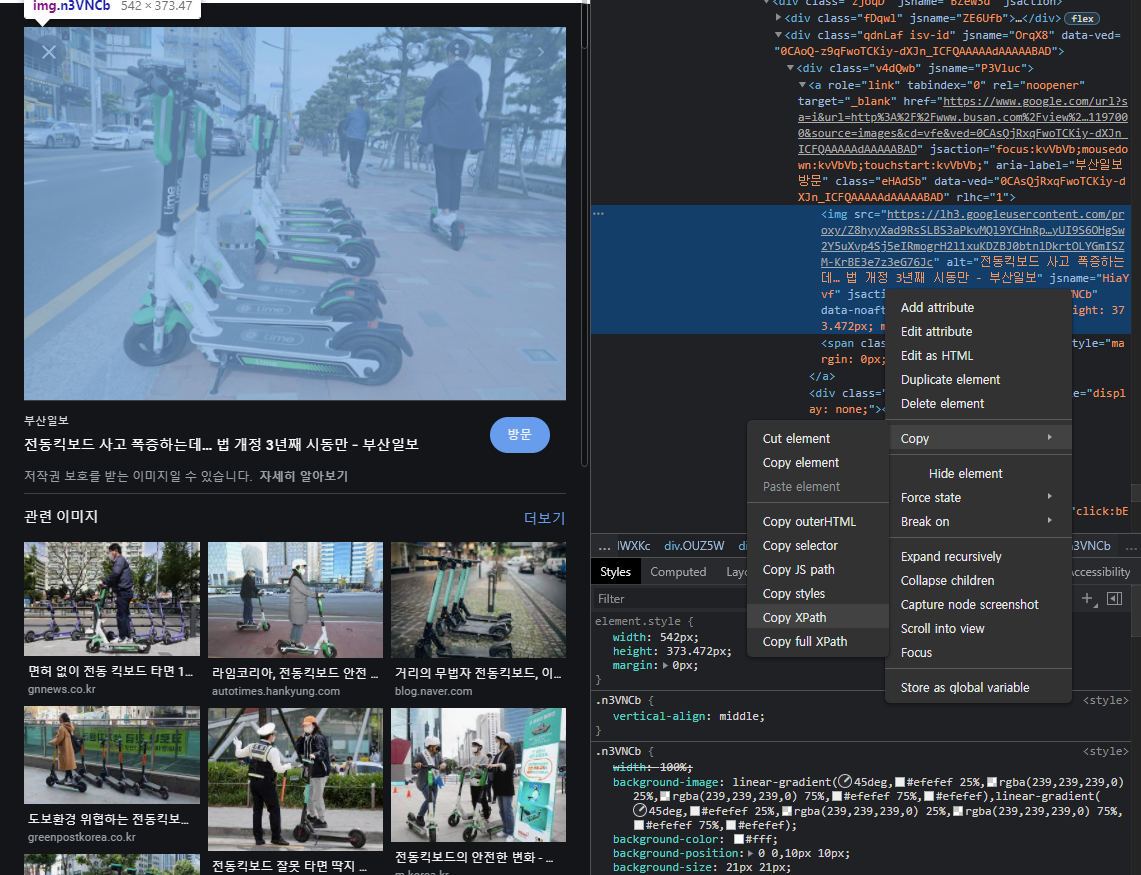
xpath 를 사용하는 방법은 간단합니다. 개발자 모드에서 css 요소를 선택하고 선택된 요소의 css 코드를 마우스 우클릭 -> copy -> Copy full XPath로 xpath 를 복사해오면 됩니다.
그 후에는 find_element_by_xpath("full xpath") 를 사용하여 원본 이미지를 선택하면 됩니다. 그 후 get_attribut('src')를 사용하여 src 를 추출하여 이전과 동일하게 urlretrieve 함수를 통해 이미지를 저장해주면 됩니다.
결과

그럼 이렇게 지정해준 주소에 이미지가 저장됩니다!
