
Logistic Regression
로지스틱리그레션은 이름은 회귀이지만 분류모델에 사용한다.
기존의 선형회귀 모델이 있을때 확률이 음과 양의 방향으로 무한대로 뻗어 나간다.
그래서 옆의 그림처럼 로지스틱회귀 모델처럼 변화해 줘야한다.
- 선형회귀 => 로지스틱회귀
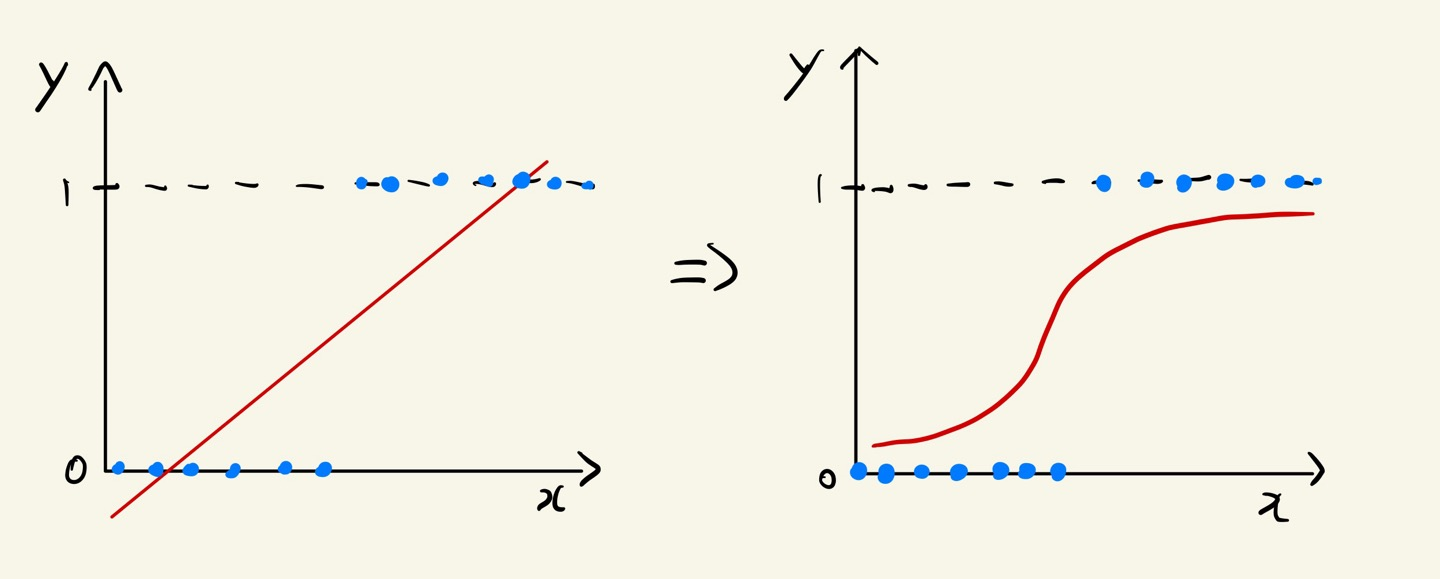
로지스틱 함수
- f(x) 범위는 -∞ ~ +∞ 이다.
- p는 (0, 1) 범위를 가지는 확률 값 얻음
- 시그모이드 함수
- 확률 값 p는 값이 커디면 1, 작아지면 0 에 가까워짐
- 기본적으로 확률 값 0.5를 임계값으로 하여 이보다 크면 1, 아니면 0으로 분류함
(0,1) [0,1]
- (0,1)은 0 ~ 1 사이 값 0과 1 포함 o
- [0,1]은 0 ~ 1 사이 값 0과 1 포함 x
- ex) (0,1] 0~1 사이값에 0포함 1제외
1. 로지스틱 함수를 사용하여 평가하는 방법
# 불러오기
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = LogisticRegression()
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))2. 로지스틱함수에 임계값을 설정하는 방법
# 예측값 확인
print(y_test.values[:20])
print(y_pred[:20])
# 확률값 확인
p = model.predict_proba(x_test)
print(p[:20])
# 임계값 조정 0.44
p1 = p[:, [1]]
y_pred2 = np.array(['1 if x > 0.44 else 0 for x in p1])
# 성능평가
print(y_pred2[:20])
print(classification_report(y_test, y_pred2))K-Fold Cross Validation
K분할교차검증
- 예측을 하기 위해 사용하는 것임
- 성능이 좋아지는 것은 아니다.
1. Random Split의 문제
- 새로운 데이터에 대한 모델의 성능으 예측하지 못한 상태에서 최종 평가를 수행
- 데이터에서 학습용 데이터, 검증용 데이터, 평가용 데이터가 있음
- 여기서 학습용데이터를 공부자료, 검증용데이터를 모의고사, 평가용데이터를 수능 이라 정해보면
- 맨날 같은 모의고사로 공부해도 수능을 잘칠 수가 없음
- 그러므로 학습용데이터에 있는 자료를 한번씩 검증용으로 사용해야함
2. K분할교차검증
- 모든 데이터가 평가에 한번 학습에 k-1번 사용함
- k는 최소 2이상 되어야 함
- 장점
- 모든 데이터를 학습과 평가에 사용
- 과소적합 문제 방지
- 일반화된 모델을 만들 수 있음
- 단점
- 반복 횟수가 많아서 모델 학습과 평가에 많은 시간이 소요됨
3. K분할교차검증 평가 방법
cross_val_score(모델, x_train, y_train, cv=분할개수)- 실제 평가에서 얻은 성능이 이 성능보다 더 높거나 낮을 수 있음
# 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
# 선언하기
model = DecisionTreeClassifier(max_depth=3)
# 검증하기
cv_score = cross_val_score(model, x_train, y_train, cv=10)
# 확인
print(cv_score)
print(cv_score.mean())
# 저장
result = {}
result['DecisionTree'] = cv_score.mean()
... KNN, Linear Regression저장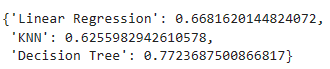
# 시각화
plt.figure(figsize=(5, 3))
plt.barh(list(result), result.values())
plt.xlabel('Score')
plt.ylabel('Model')
plt.show()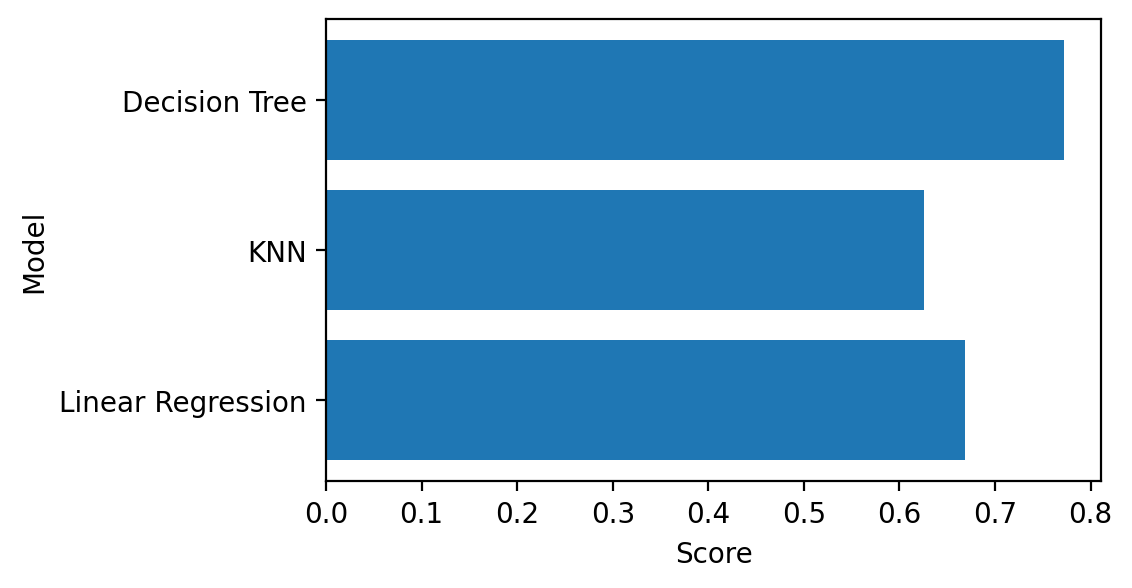
# 실제 값과 비교
model = DecisionTreeRegressor()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
from sklearn.metrics import mean_absolute_error, r2_score
print('MAE: ', mean_absolute_error(y_test, y_pred))
print('R2: ', r2_score(y_test, y_pred))- 보통 r2와 비교함
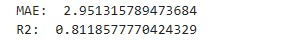
Hyperparameter
- 모델 성능을 최적화하기 위해 조절할 수 있는 매개변수
- KNN - n_neighbors
- Decision Tree - max_depth
- 다양한 시도 방법 (Grid Search, Random Search)
KNN
- k값에 따라 성능이 달라짐
- k 값이 가장 클때 가장 단순한 모델임
- 평균(회귀), 최빈값(분류)
- k 값이 작을 수록 복잡한 모델이 됨
- 유클리드 거리(Euclidean), 맨하튼 거리(Mangattan)
Decision Tree
(1) max_depth
- 트리의 최대 깊이 제한
- 기본값: max_depth=None
- 값이 작을 수록 모델이 단순해짐
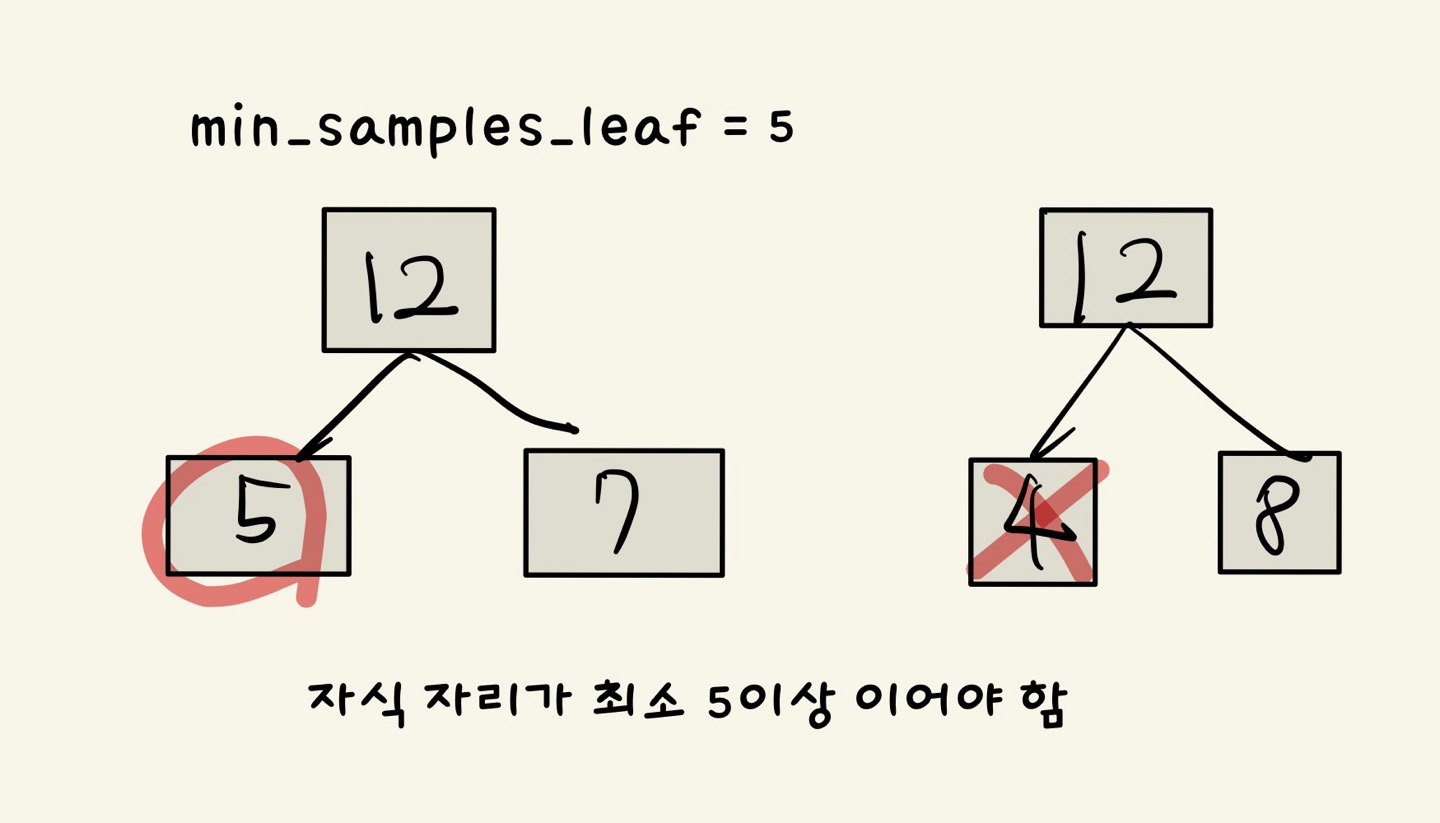
(2) min_sampls_leaf
- leaf가 되기 위한 최소한의 샘플 데이터 수
- 클수록 모델이 단순해짐
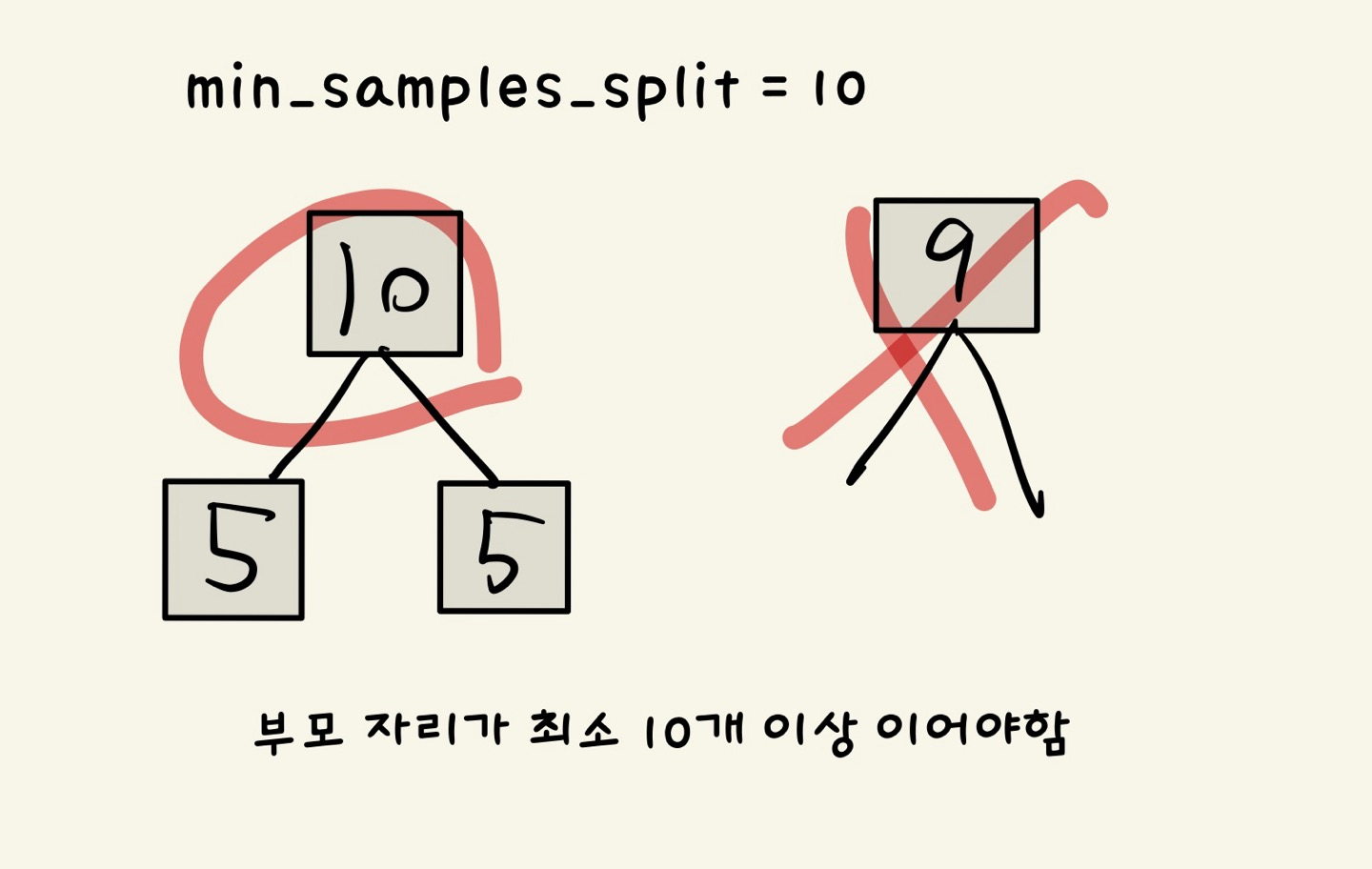
(3) min_samples_split
- 노드를 분할하기 위한 최소한의 샘플 데이터 수
- 클수록 모델이 단순해짐
Random Search, Grid Search
- 파라미터를 구하는 방법
max_depth나n_estimators등을 구할때 사용
Grid Search
- 성능을 테스트할 파라미터 값의 범위를 지정
- 파라미터 값 범위를 모두 사용하는 Grid Search 모델 선언 후 학습
- 가장 성능이 좋았던 때의 값 찾음
- n 값이 크면 많은 시간이 소요됨
# 파라미터 하나인 경우
param = {'n_neighbors': range(1,101)}
- 100번 수행되면서 모든 경우의 성능 확인
# 파라미터 두개인 경우
param = {'n_neighbors': range(1,101)
'metric' : ['euclidean', 'manhattan']}
- metric 값이 2개라 200개 조합이 만들어짐
- 200번 수행되면서 모든 경우의 성능 확인Grid Search 사용방법
GridSearchCV- n_iter 옵션 지정 x
# 함수 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 파라미터 선언
param = {'n_neighbors': range(1,500,10),
'metric' : ['euclidean', 'manhattan']}
# 기본모델 선언
knn_model = KNeighborsClassifier()
# Grid Search 선언
model = GridSearchCV(knn_model,
param,
cv=3) # n_iter 없음
# 모델 학습
model.fit(x_train, y_train)
# 수행정보
model.cv_result_
# 최적 파라미터
model.best_params_
# 최적 성능
model.best_score_Random Search
- 성능을 테스트할 파라미터 값의 범위를 지정
- 파라미터 값 범위에서 몇 개 선택할지 정하여 Random Search 모델 선언 후 학습
- 수집된 것 중 가장 성능이 좋았던 값을 찾음
- 시간 소모는 적음
- 선택되지 못한 값에서 더 좋은 성능이 보이는 값이 있을 수 있음
# 파라미터 하나인 경우
param = {'n_neighbors': range(1,101)}
- 지정한 개수의 임의의 값에 대해서만 성능 확인
# 파라미터 두개인 경우
param = {'n_neighbors': range(1,101)
'metric' : ['euclidean', 'manhattan']}
- 지정한 개수의 임의의 조합에 대해서만 성능 확인Random Search 사용방법
RandomizedSearchCVn_iter개수 지정
# 함수 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RandomizedSearchCV
# 파라미터 선언
param = {'n_neighbors': range(1,500,10),
'metric' : ['euclidean', 'manhattan']}
# 기본모델 선언
knn_model = KNeighborsClassifier()
# Random Search 선언
model = RandomizedSearchCV(knn_model,
param,
cv=3,
n_iter=20)
# 모델 학습
model.fit(x_train, y_train)
# 수행정보
model.cv_result_['mean_test_score']
# 최적 파라미터
model.best_params_
# 최적 성능
model.best_score_
뒤늦게 프로그래밍을 시작한 응애