node.js로 간단하게 배치 크롤러 만들어보겠습니다.
크롤러는 말그래도 html 문서를 가지고 사이트 내에 특정 내용을 뽑는것이고,
배치는 운영체제 기반의 태스크 스케줄러를 이용한 특정 주기에 특정 코드를 실행하는 방법입니다.
무엇을 크롤링?
타겟사이트 : (전력거래소) https://www.kpx.or.kr/
시뮬레이션 : 전력거래소에서
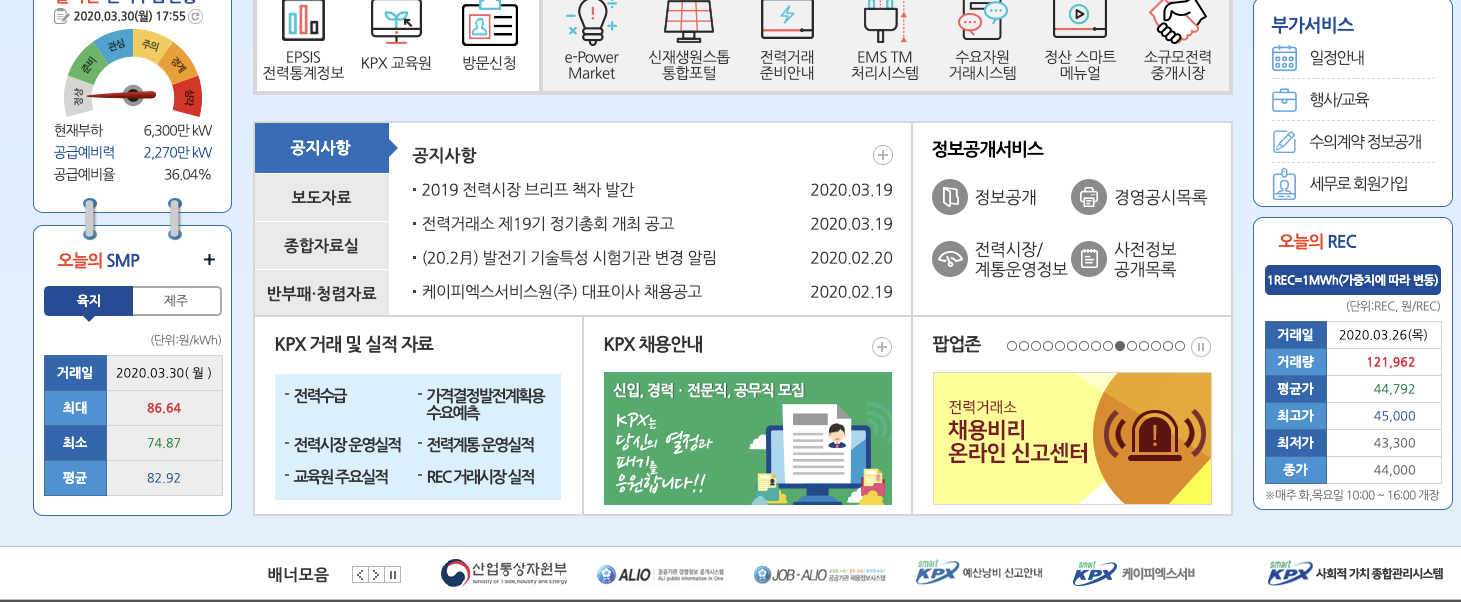
오늘의 SMP, 오늘의 REC를 하루에 한번씩 긁어오는 간단한 배치 크롤러를 구현해봅니다.
준비물
node v13.8.0
package.json
{
"name": "nodeCrawling",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node ./main.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^0.19.2",
"cheerio": "^1.0.0-rc.3",
"node-cron": "^2.0.3",
}
}- nodeCrawling 디렉토리를 하나 만듭니다.
npm init -ynpm 설정파일을 생성합니다.npm i axios cheerio node-cron
라이브러리 설명
axios : promise 기반 http 요청 라이브러리 ( get 요청을 통해 html을 응답받아야합니다. )
cheerio : jquery처럼 html을 참조할 수 있습니다.
node-cron : The node-cron module is tiny task scheduler in pure JavaScript for node.js based on GNU crontab. This module allows you to schedule task in node.js using full crontab syntax. ( 코드를 주기적으로 실행할 수 있습니다.)
프로젝트 구조
solarconnect-yosephnoh ~/Documents/practices/nodeCrawling tree -L 1
.
├── crawl.js
├── main.js
├── node_modules
├── package-lock.json
└── package.json
검사를 통해 긁어올 태그의 엘레먼트를 찾습니다.
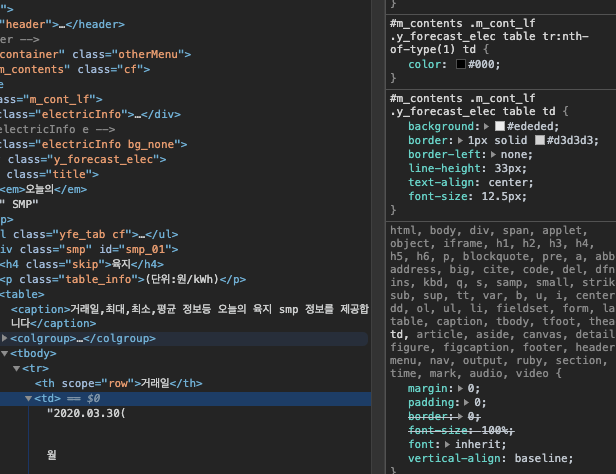
#m_contents .m_cont_lf .y_forecast_elec table에서 거래일, 최대, 최소, 평균 smp를 긁어올겁니다.
코드
이제 크롤링하는 코드를 작성합니다.
crawl.js
const axios = require("axios");
const cheerio = require("cheerio");
let html = "";
async function getHtml() {
try {
return await axios.get("https://www.kpx.or.kr/");
} catch (error) {
console.error(error);
}
}
async function getSmp() {
if (!html) {
html = await getHtml();
}
const $ = cheerio.load(html.data);
let smp = {};
$("#m_contents .m_cont_lf .y_forecast_elec table")
.find("tr")
.each(function(index, elem) {
switch (
$(this)
.find("th")
.text()
.trim()
) {
case "거래일":
smp[`date`] = $(this)
.find("td")
.text()
.replace(/([\t|\n|\s])/gi, "");
break;
case "최대":
smp[`max`] = $(this)
.find("td")
.text()
.replace(/([\t|\n|\s])/gi, "");
break;
case "최소":
smp[`min`] = $(this)
.find("td")
.text()
.replace(/([\r|\n|\s])/gi, "");
break;
case "평균":
smp[`avg`] = $(this)
.find("td")
.text()
.replace(/([\r|\n|\s])/gi, "");
break;
}
});
return smp;
}
async function getRec() {
if (!html) {
html = await getHtml();
}
const $ = cheerio.load(html.data);
let rec = {};
$("#m_contents .m_today_rec table")
.find("tr")
.each(function(index, elem) {
switch (
$(this)
.find("th")
.text()
.trim()
) {
case "거래일":
rec[`date`] = $(this)
.find("td")
.text()
.replace(/([\t|\n|\s])/gi, "");
break;
case "거래량":
rec[`volumn`] = $(this)
.find("td")
.text()
.replace(/([\t|\n|\s])/gi, "");
break;
case "평균가":
rec[`avg`] = $(this)
.find("td")
.text()
.replace(/([\r|\n|\s])/gi, "");
break;
case "최고가":
rec[`max`] = $(this)
.find("td")
.text()
.replace(/([\r|\n|\s])/gi, "");
break;
case "최저가":
rec[`min`] = $(this)
.find("td")
.text()
.replace(/([\r|\n|\s])/gi, "");
break;
case "종가":
rec[`last`] = $(this)
.find("td")
.text()
.replace(/([\r|\n|\s])/gi, "");
break;
}
});
return rec;
}
module.exports = { getRec, getSmp };
2분마다 크롤링하는 배치를 생성합니다.
main.js
const { getRec, getSmp } = require("./crawl.js");
const cron = require("node-cron");
async function handleAsync() {
const rec = await getRec();
const smp = await getSmp();
console.log("rec", rec, "smp", smp);
}
cron.schedule("*/2 * * * *", async () => {
console.log("running a task every two minutes");
await handleAsync();
});배치 돌리기
이제 프로젝트 루트 디렉토리에서 npm start 통해 프로그램을 실행해줍니다.
https://jongmin92.github.io/2017/05/26/Emily/4-crawling/
todo
퍼펫티어로 로그인이 필요한 크롤링 해보기
https://ncube.net/14128
medium 처럼 클래스를 css 클래스명으로 크롤링 못하게 해놓은 곳은 무슨수로 크롤링하나?
크롤러 업체들이 https://www.torproject.org/ 를 활용해서
ip를 변경해가면서 크롤링 하는거 같습니다.
pupeteer 활용 예제
https://gist.github.com/stephonchen/7647575d6a2f063a9973f398ef281db8
selenium 임의 ip로 크롤링 하기
https://wkdtjsgur100.github.io/selenium-change-ip/
torproject.orgtorproject.org
The Tor Project | Privacy & Freedom Online
Defend yourself against tracking and surveillance. Circumvent censorship.
JangJang
selenium에서 임의의 ip로 크롤링하기 (python, Ubuntu, Firefox)
selenium으로 크롤링을 하다보면 ip를 막아버리는 사이트도 있습니다. 이를 피하기 위해 Tor를 이용해, selenium에서 임의의 ip로 크롤링하는 방법에 대해서 작성했습니다.(Ubuntu, Firefox)

좋은 포스트 감사합니다 :)
이 포스트를 보고 느낀건데, 링크를 조금 더 예쁘게 인용 할 수 있는 기능을 만들면 좋을것같네요 ㅋㅋ 한번 작업해보겠습니다!