Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
https://arxiv.org/abs/2201.11903
LLM을 프롬프팅할때, 사고의 과정을 예시로 함께 넣어주면, 정확도가 올라간다고 한다.
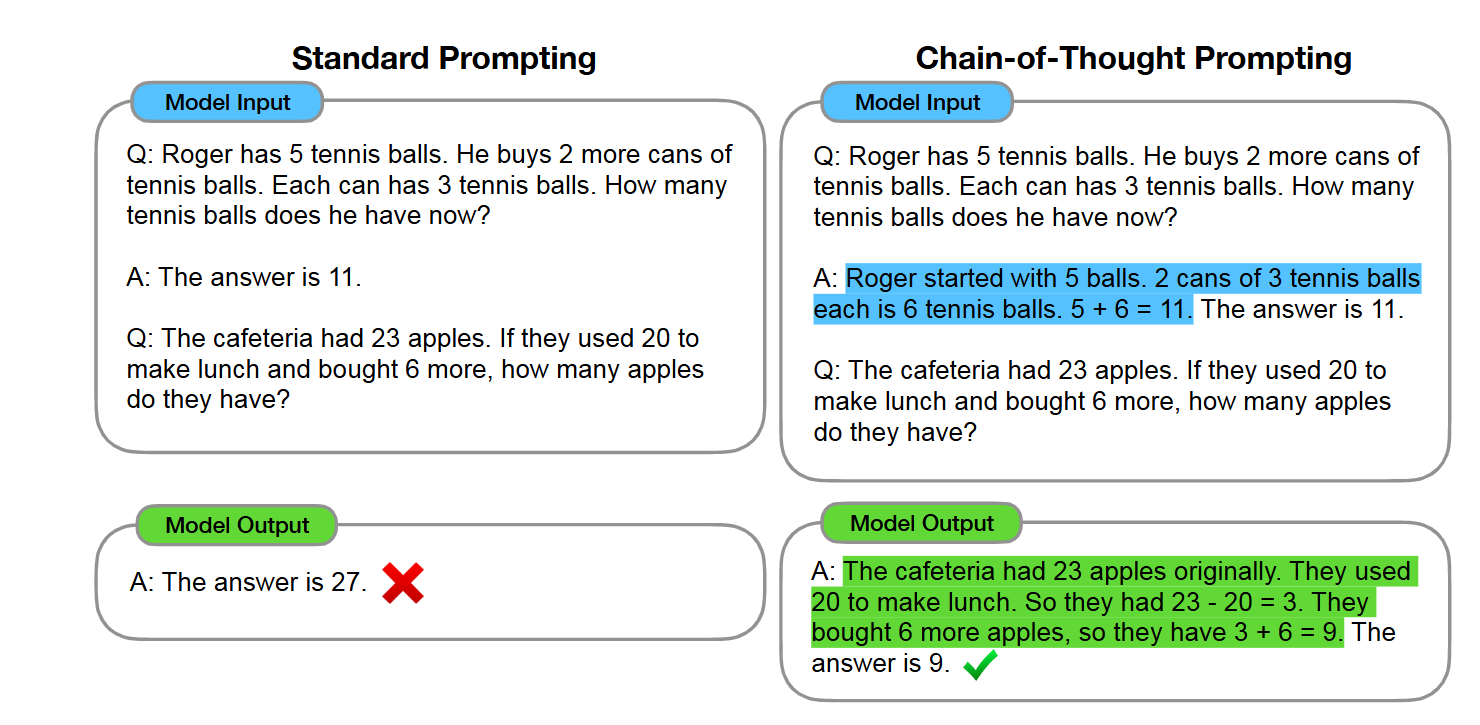
요즘 LLM들은 이런 방식으로 사고를 하는듯 하다.
사용자에게는 사고의 과정은 숨기는 방식이지 않을까 싶다.
이런 방식의 텍스트를 학습시키기는 쉽지 않다.
기본적으로 길이가 길기 때문이다.
길이가 긴 텍스트는 forward시키는것만으로도 많은 메모리를 필요로 하게 된다.
따라서 이를 개선하는 다양한 기법들이 있는것 같다.(sparse attention등)
메모리가 부족하다면 추가로 공부해봐야겠다.
