LoRA: Low-Rank Adaptation of Large Language Models
https://arxiv.org/abs/2106.09685
LLM 파인튜닝 시, 모든 파라미터를 조정하는것은 많은 비용을 필요로 한다.
일단 모델을 불러오는것만으로도 파라미터 개수 7B모델(float16) 기준 14GB의 VRAM을 필요로 한다.
또한, gradient를 저장, 계산하기 위해서 옵티마이저에 따라서는 몇배의 추가 VRAM을 필요로 한다.
그리고, forward시키는것만으로도 gradient와는 무관하게 VRAM을 필요로 한다.
셀프 어텐션 때문에 인풋 시퀀스의 길이가 길어질수록 길이의 제곱에 비례하는 VRAM을 소모하게 된다.
정확한 사용량은 모르겠으나, 7B모델 기준, 학습 없이 길이 300의 인풋을 forward시키는 것만으로도 30GB이상의 VRAM을 필요로 하였다.
학습까지 시킨다면, 50GB이상의 VRAM을 필요로 할것으로 예상된다.
LoRA
LoRA는 모델을 파인튜닝 시, 저렴하게 학습할 수 있는 방법 중 하나이다.
비슷한 목적을 가진 다른 방법들도 많이 있는듯 하다.
이 방법들은 단순히 저렴하게 학습할 수 있다는 장점 말고도, pretrained된 기본 성능을 크게 잃지 않도록 할 수 있다는 장점도 있다.
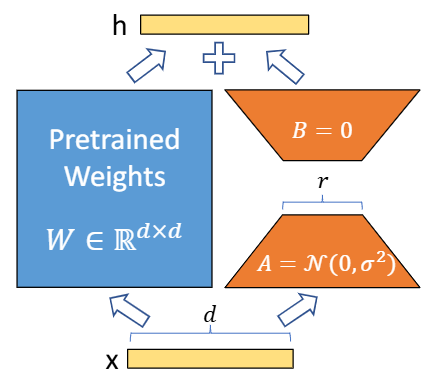
linear layer에서의 예시가 위와 같다.
파란색의 pretrained weights를 학습하는것은 비싸니, 주황색 layer를 추가하고, 주황색 layer를 학습하는 방법이다.
주황색 layer는 input, output의 크기가 파란색 layer와 같아야 한다.
파란색이 dxd크기라면, 주황색은 중간에 r로 차원으로 압축했다가 복원하는 방식으로, dxr + rxd의 크기가 된다.
r이 d보다 충분히 작다면 총 파라미터 개수는 주황색이 훨씬 적어지게 된다.
transformer
쿼리, 키, 벨류 행렬들이 보통 linear layer로 구현되어 있다.
쿼리, 키 layer들에 위 주황색 어댑터를 적용하는 방식 등으로 구현이 되는듯 하다.
peft 라이브러리를 통해 쉽게 구현 가능하다.
QLoRA
모델 자체를 float16보다도 더 낮은 메모리를 차지하는 int8과 같은 값을 사용한다면, 메모리 사용량을 낮출수 있을것이다.
하지만 정확도가 낮아지는 문제가 발생하는데, QLoRA는 traed-off를 개선한 새로운 자료형(NF4)을 개발했다고 한다.
해당 자료형을 사용한다면, 더 적은 메모리 사용량으로 모델을 불러올 수 있다.
