HIGH-DIMENSIONAL CONTINUOUS CONTROL USING GENERALIZED ADVANTAGE ESTIMATION
https://arxiv.org/abs/1506.02438
PPO 논문 구현에 있어 필요한 개념이다.
적격 흔적을 공부할때 λ 이득의 개념을 공부했었다.
https://velog.io/@nrye4286/%EC%A0%81%EA%B2%A9-%ED%9D%94%EC%A0%81-TD
λ 이득은 가중치 λ에 따라 감소하는 가중 평균 이득이다.
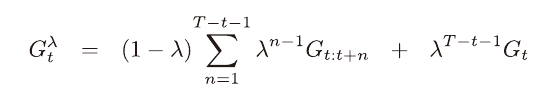
이를 advantage function에 적용한 버전이다.
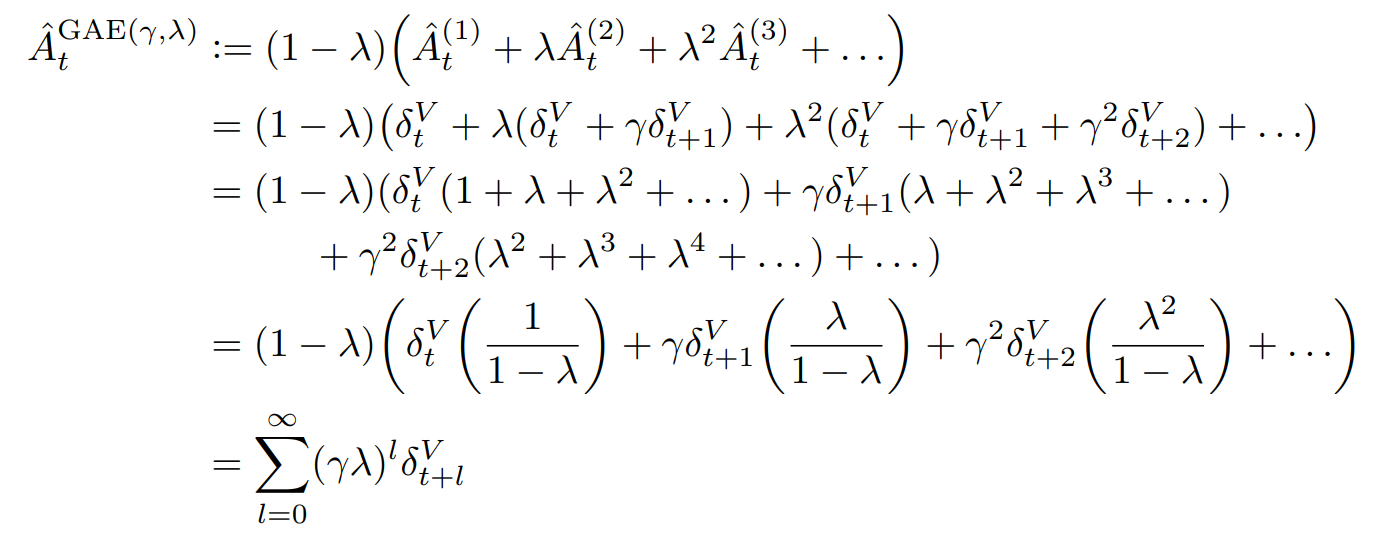
기존 λ 이득의 장점과 같다.
λ가 0일때는 첫번째 항만 부트스트랩으로 활용하게 되며, bias가 존재한다.
λ가 1일때에는 부트스트랩을 활용하지 않게 되어 bias는 존재하지 않게 되지만,
분산이 커진다는 단점이 있다.
λ가 적절한 값을 가질때 두 장점을 적절히 활용할 수 있게된다.
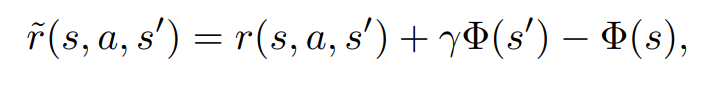
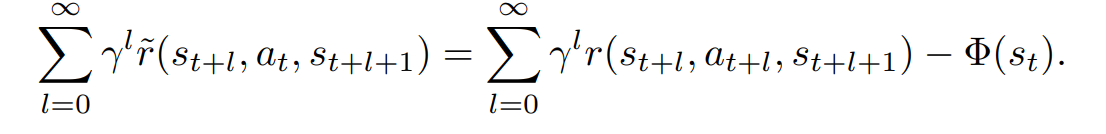
오타가 의심되는 수식을 발견하였다.
좌항에서 at가 아닌, at+l이여야 할 것 같다.
매우 유명한 논문이고 이를 지적하는 사람을 찾지 못하였기 때문에 내가 틀릴 가능성이 크지만,
논문에서 크게 중요하지 않은 부분이기도 하고, at이면 누가봐도 이상한 수식이 되기 때문에 지적을 안하는건가 싶기도 하다.
(에피소드 동안 한가지 행동만 했을 때의 보상은 아무 쓸모 없음)
