Reinforcement-Learning
1.정책 향상 정리

미리 알아야 하는 지식- 정책, 가치함수 등 강화학습 기초모든 상태 s에 대해서 아래 수식은 만족하면 π'는 π만큼 좋거나 그 이상으로 좋다고 말할 수 있다.어떠한 정책π 의 가치함수를 안다면 그 가치함수에 탐욕적이도록 하는 새로운 정책π'을 찾을수 있다.위 π'은 기
2.DP 방법 배팅액 정책 찾기
동전을 던져서 앞면이 나올시 배팅액만큼 벌고,뒷면이 나올시 배팅액을 잃는 게임이 있다.지민이는 100원을 벌어야 한다.앞면이 나올 확률이 0.4라고 할 때현재 가지고 있는 금액에서 얼마를 배팅하는것이 좋은지 정책을 마련하라.100원에 달성할시 보상을 1로, 그 외 나머
3.몬테카를로 방법 운전 정책 찾기
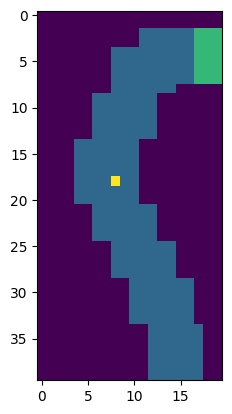
몬테카를로방법으로 이용하여 운전 정책을 찾아보려 한다. 파란색은 도로, 초록색이 목적지이며 도로의 맨 아랫부분의 랜덤한 위치에 노란색 차가 정지된 채 생성된다. 상하좌우에 대해 -1,0,1만큼 가속을 가할수 있으며(9가지 행동) 차는 x축과 y축에 대해 -3~3의
4.n단계 시간차 학습 (부트스트랩)
미리 알아야 하는 지식: 몬테카를로, 시간차 학습 n단계 TD 기댓값일때와 아닐때 p의 범위가 다른 이유 학습효과 차이, 살사, q러닝 포함 일반화 가능 설명 n단계 살사 n단계 q러닝 가중치 설명, 알고리즘 마지막에 max q(s,a)들어가야 함. off pol
5.강화학습 On-policy Off-policy
_미리 알아야 하는 지식 - 강화학습 기초, 몬테카를로 방법_ 최적 정책을 찾기 위해서는 탐험이 필요하다. 이를 위한 방법으로 on-policy 방법과 off-policy 방법이 있다. on-policy 방법 학습을 하는 정책으로 탐험또한 진행하며 두가지
6.강화학습 모델 개념, 환경이 변화하는 미로 예제
시간차학습은 강화학습에서 모델이라고 부르는 p(s',r|s,a)를 사용하지 않는다.동적프로그래밍 방식은 모델을 이용하여 학습한다.시간차학습 도중에 모델을 학습하는 방식으로 위 둘을 통합할수 있다.모델의 종류로 각 가능성에 대한 확률을 제공하는 분포 모델모든 가능성 중에
7.강화학습 근사적 해법
미리 알아야 하는 지식- 표(tabular)의 기반한 해결법
8.오목 강화학습
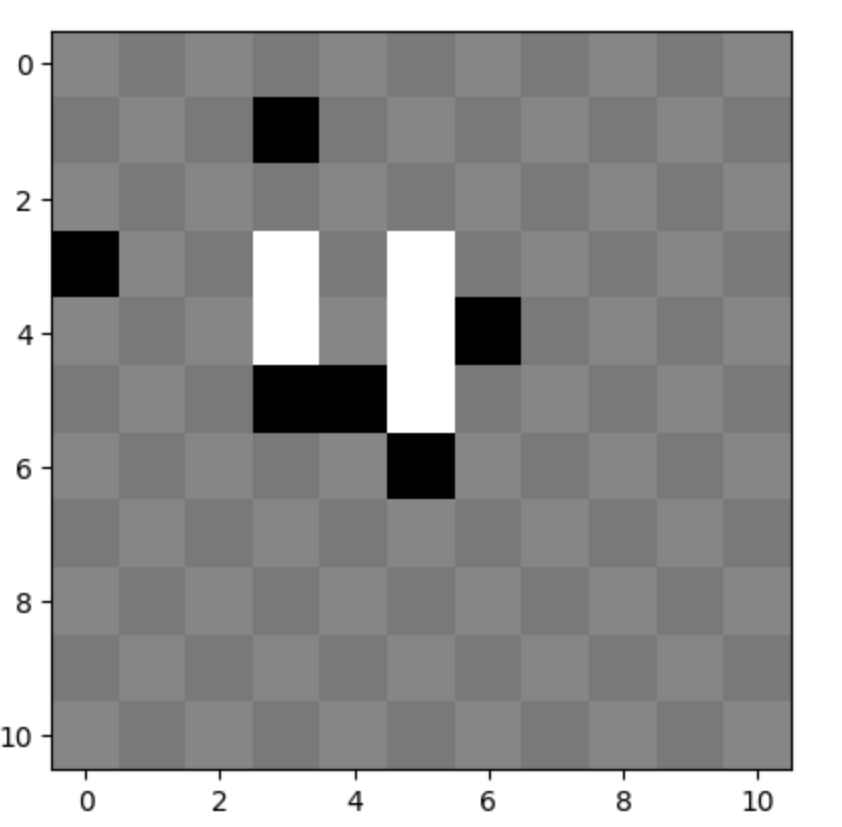
오목 강화학습을 해보았다. https://www.youtube.com/watch?v=SvE2tEFq7j4 직접 학습한 ai들끼리 대결하는 영상이다. 오목은 가능한 경우의 수가 매우 많기 때문에 표에 기반한 강화학습 방법으로는 해결이 불가능하다. 따라서 인공신경망을
9.강화학습 interest, emphasis
가중치를 이용하여 가치를 근사할 경우에 제한된 재원을 이용하여 모든 상태의 가치를 근사해야 한다. 이때 가치를 정확히 아는것이 중요한 상태와 상대적으로 그렇지 않은 상태가 있을것이다. 따라서 재원을 목표 지향적으로 활용한다면 성능을 향상시킬수 있을것이다. inte
10.강화학습 평균 보상
종단 상태가 없는 연속적인 문제에서 평균 보상을 이용할 수 있으며,할인율 대신 평균 보상을 이용하는것이 좋다고 한다.평균 보상을 이용하는 방법과, 그 이유에 대해서 소개해 보겠다.평균 보상은 특정한 정책을 따를때의 평균 보상을 의미한다. (당연)수식은 위와 같다.μ는
11.적격 흔적, TD(λ)
n단계 TD방법을 사용할 때 n은 몇으로 해야할까?미래를 내다봐야 하며, 복잡한 TD, MC 방법을 간단하게 바꿀수는 없을까?여기서 사용할 λ 이득의 개념을 설명하겠다.n에 따른 이득을 가중평균하는 식이다.λ에 따라서 가중치가 감소된다.위 λ 이득을 이용한 알고리즘이다
12.Actor-Critic
여태까지 가치를 근사하여 정책을 결정하였다. 문제가 tabular할때 최적의 정책을 찾기 위한 해법을 연속적인/규모가 큰 문제에서 적용하기 위해 개선한 방법이다. 가치를 근사함으로 인해 이론상으로라도 완벽한 정책을 찾는것이 불가능해졌다. 그렇다면 차라리 정책을 근
13.Cart Pole Actor-Critic

Cart Pole 강화학습을 해보았다.처음에는 Q-learning으로 시도를 했다.성능이 처참했다.학습을 하는 데이터들이 시퀀스 데이터다보니 데이터들끼리의 상관관계가 높아서 안정적인 학습을 하지 못하는듯 하였다.Playing Atari with Deep Reinforc
14.GAE
HIGH-DIMENSIONAL CONTINUOUS CONTROL USING GENERALIZED ADVANTAGE ESTIMATION https://arxiv.org/abs/1506.02438 PPO 논문 구현에 있어 필요한 개념이다.
15.TRPO
Trust Region Policy Optimization https://arxiv.org/abs/1502.05477 이 논문은 실전에서의 적용이 까다롭기로 유명하며, PPO 등의 논문에서 TRPO의 개념을 활용하여 더 좋은 성능과 쉬운 적용을 가능하게 하기 때문에
16.REINFORCE, TRPO 비교
REINFORCE 알고리즘과 TRPO 알고리즘을 공부하였다. 두 알고리즘을 비롯하여 다양한 알고리즘에서 비슷한 요소를 발견해서 비교 분석을 해보았다. 갱신 규칙 REINFORCE 갱신 규칙
17.PPO
Proximal Policy Optimization Algorithms https://arxiv.org/abs/1707.06347 Background: Policy Optimization 아래는 TRPO 알고리즘이다. constraint를 하며 위 항을 최대화 시킨
18.Mujoco Hopper PPO

mujoco hopper를 PPO알고리즘으로 학습시켜 보았다.https://www.youtube.com/watch?v=XvzSEMZdvrUopen AI의 PPO논문을 읽고, 공개한 PPO코드를 분석해보았다.이론에 맞게 코딩을 한 느낌이 아니라, 코딩을 해보고
19.Atari DQN
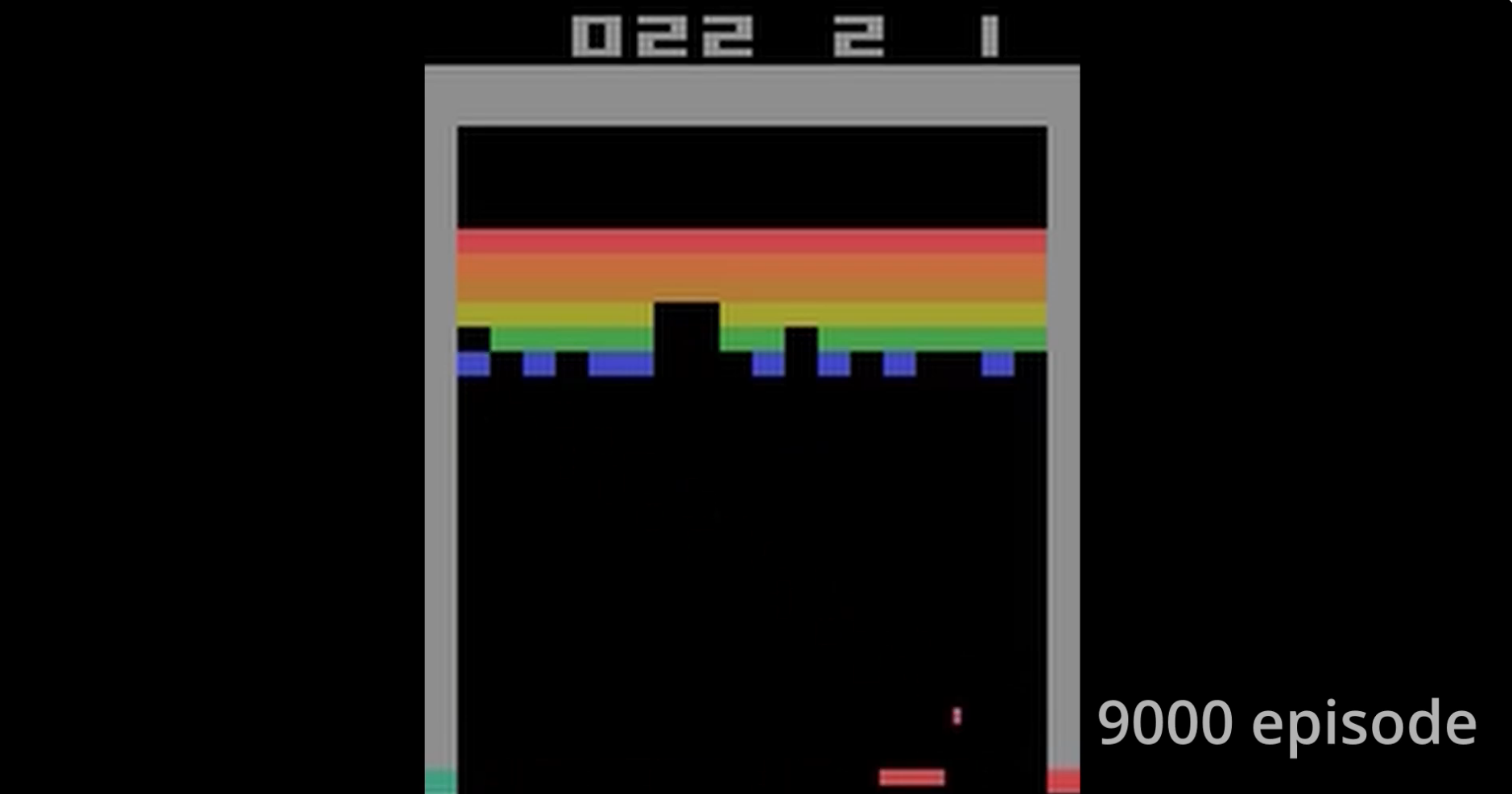
atari breakout를 학습시켜 보았다.영상 링크https://www.youtube.com/watch?v=CVjnIaWjUZEPlaying Atari with Deep Reinforcement Learning 논문 링크https://www.cs.
20.SAC
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor https://arxiv.org/abs/1801.01290 Soft Actor-Critic(
21.DDPG
DDPG는 actor-critic 방법 중 deterministic policy를 사용하는 방법이다. 확률론적인 정책을 사용하는 방법은(ex. PPO) 이득이 +인 행동의 확률을 올리고, -인 행동의 확률을 내리며 actor를 학습한다. DDPG critic이 Q-
22.[Imitation Learning] Overview of Imitation Learning, Distribution Shift
In RL, we can get agent by designing reward function. But designing reward function for complex task is too hard. I thought 'how about reward funtio
23.[Imitation Learning] Algorithms for Inverse Reinforcement Learning
Algorithms for Inverse Reinforcement Learning https://ai.stanford.edu/~ang/papers/icml00-irl.pdf This paper is old. It would not include neural netw
24.[Imitation Learning] GAIL
Let's go to understand GAIL algorithms.IRL is extremely expensive to run, requiring reinforcement learning in an inner loop.H is π's entropy, c is cos
25.Overview of Meta-RL
Meta-Learning Meta-learning can be described as 'learning to learn' by training on various tasks. One example is MAML (Model-Agnostic Meta-Learn
26.[Offline RL] MOPO
Data inefficiency is a critical issue in RL. And sometimes it could be dangerous to interact with real world. Offline RL has an advantage in this reg
27.[Offline RL] RARL, RAMBO-RL
RAMBO-RL 논문을 읽기 위해 필요해보여서 RARL 논문을 읽게 되었다.현재 연구들, 지금으로 치면 2024 2025 논문을 읽고 싶은데 그 과정이 참으로 길다..
28.RLHF
강화학습은 보상함수를 필요로 한다.보상함수 설계가 매우 어려운 경우가 있으며(ex. LLM), 설계한다 하더라도 모델이 편법으로 보상을 최대화한다던가, 보상이 sparse해서 학습이 느려진다던가 하는 문제가 발생한다.RLHF는 인간 선호도 데이터를 통해 보상함수 네트워