Trust Region Policy Optimization
https://arxiv.org/abs/1502.05477
이 논문은 실전에서의 적용이 까다롭기로 유명하며,
PPO 등의 논문에서 TRPO의 개념을 활용하여 더 좋은 성능과 쉬운 적용을 가능하게 하기 때문에 개념을 이해하는것이 중요하다.
일단 이 논문은 Policy Gradients 방법을 다룬다.
Preliminaries
정책 성능의 정의
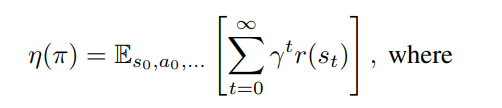
value funcion과 advantage function의 정의
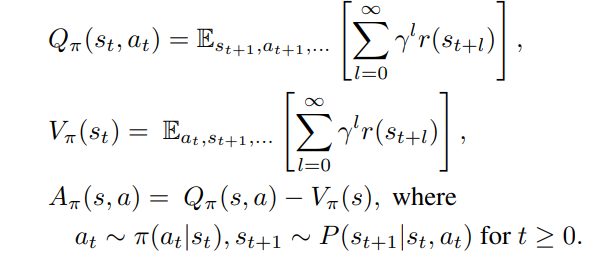
두 정책 사이의 관계
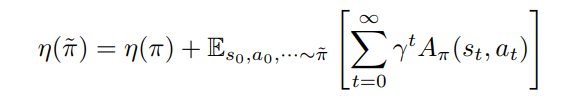
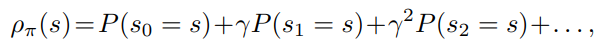
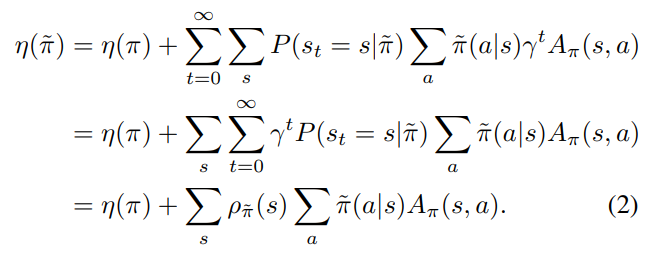
정책의 성능이 증가하는 방향으로 π를 업데이트 하면 된다.
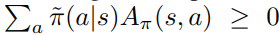
모든 s에 대해서 위를 만족하면 정책 성능의 향상은 보장된다.
하지만 함수 근사로 인해 이는 일반적으로 불가능하다.
따라서 보통 성능이 증가하는 방향으로 θ를 조정한다. (Policy Gradients)
위 η의 기울기를 구하는 것은 매우 어렵다고 한다.
따라서 아래와 같이 해결한다.
L을 새롭게 정의한다.
η에서 ρπ˜를 ρπ로 대체한 값이다.
π = π˜ 일때는 L = η이며 따라서 아래 식이 성립하게 된다고 한다.
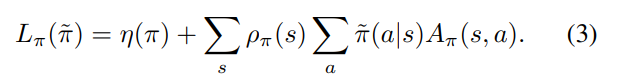
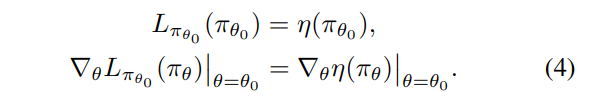
π에서 π˜로의 충분히 작은 step은 L의 증가가 η도 증가시킴을 암시한다.
하지만 너무 작은 step은 학습을 지연시키기 때문에 효율성도 따져야 하며,
얼마나 작은 step까지 안전한지 확인해야 한다.
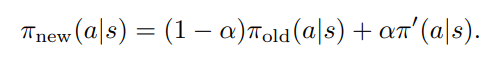
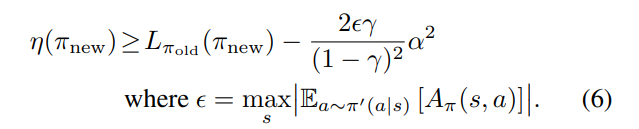
새로운 정책을 위와 같이 정의하게 되면
새로운 정책의 성능은 다음과 같은 lower bound를 갖는다고 한다.
증명 과정은 인용된 논문에 나온다.
https://people.eecs.berkeley.edu/~pabbeel/cs287-fa09/readings/KakadeLangford-icml2002.pdf
(수식이 살짝 다르다. 'We have modified it to make it slightly weaker but simpler.' 이 때문인듯 하다.)
새로운 정책의 lower bound가 기존 정책의 성능보다 높도록 최적화를 시킨다면
정책 성능의 단조 증가를 기대할 수 있다.
Monotonic Improvement Guarantee for General Stochastic Policies
위는 α를 이용한 mixture polices를 이용했다. (α: 두 정책 사이의 거리를 조절하는 값)
mixture polices 방법은 실전에서 거의 사용되지 않기 때문에
α를 다른 거리로 대체하고, ε 또한 적절하게 바꿔줌으로써
일반적인 확률론적 정책으로의 확장이 가능하다고 한다.
이 논문에서 사용하는 거리는 total variation divergence이다.
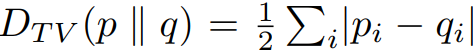
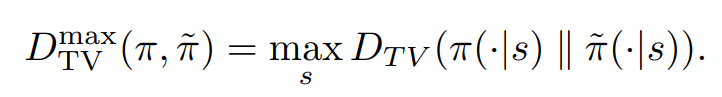
α를 다음과 같이 정의하게 되면 아래 식이 성립한다고 한다.
(mixture polices방법 적용 x)
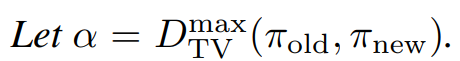
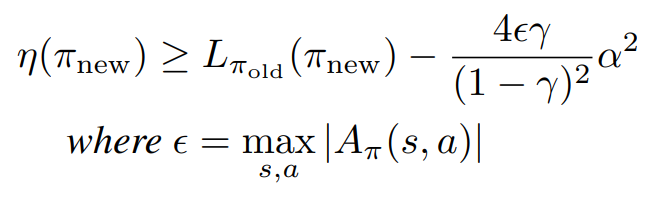
이에 대한 증명 과정은 논문에 수록되어 있다.
total variation divergence 와 KL divergence의 관계를 이용하여 다음 또한 성립한다고 한다.
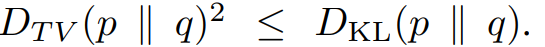
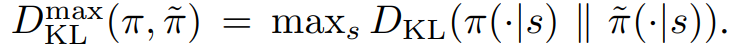
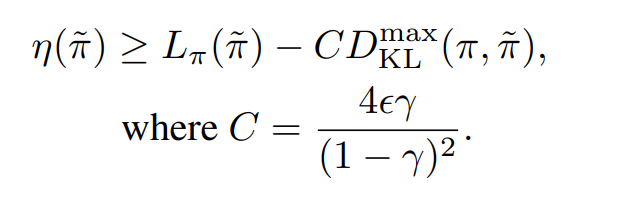
위 수식으로 인해 아래 알고리즘 1이 정책 성능의 단조 증가를 보장한다.
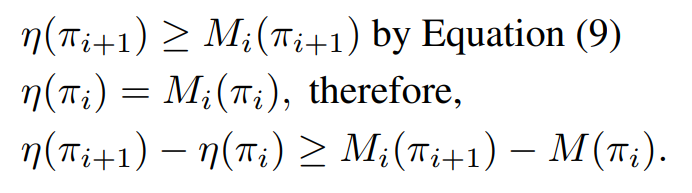

(여기부터는 현실에서 적용하기 위한 내용을 주로 다룬다.)
Optimization of Parameterized Policies
따라서 다음을 최대화 하게되면 정책 성능의 향상이 보장된다.
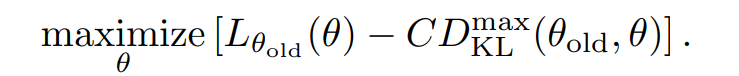
실전에서는 L을 최대화 하되, Dkl로 제약을 거는 방식을 사용하며,
(trust region constraint)
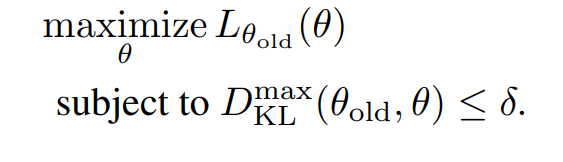
모든 s에 대해서 Dkl을 구할수 없으니 average KL divergence를 사용한다.
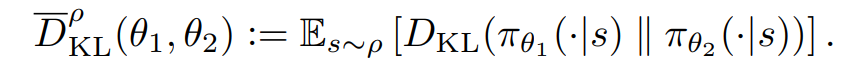
Sample-Based Estimation of the Objective and Constraint
이 부분은 sample-based 방법을 다룬다.
위 수식에서 L을 풀어쓰게 되면 아래와 같다.

sum을 기댓값으로 바꾼뒤, 샘플링 분포 q를 이용해서 아래와 같이 변형해 준다.
(중요도 샘플링을 이용한 듯 함.)
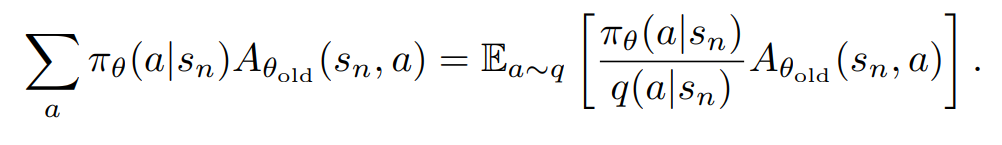
이 뒷부분은 샘플링 방법에 대해서 다루는 듯 하다.
PPO 논문을 읽기 위해 필요하다면 다시 읽어봐야겠다.
