
mujoco hopper를 PPO알고리즘으로 학습시켜 보았다.
https://www.youtube.com/watch?v=XvzSEMZdvrU
open AI의 PPO논문을 읽고, 공개한 PPO코드를 분석해보았다.
hopper
이전까지 학습했던 환경과 가장 큰 차이점은 행동 공간이 연속적이라는 점이다.
따라서 정책이 확률분포를 반환하며 그 분포에서 샘플링하는 방식의 정책을 적용하였다.
구현
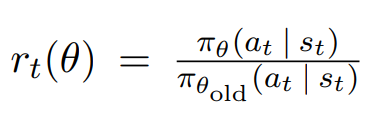
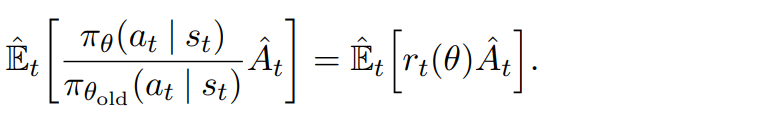
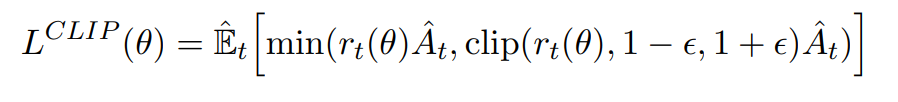
이 부분이 실제로 어떻게 구현되는지 설명해보겠다.
gradient를 계산할때 θold는 상수로 고정시키고, θ의 gradient를 계산하는 시스템이다.
θ를 업데이트 시키기 전에는 θold와 θ의 값은 같다.
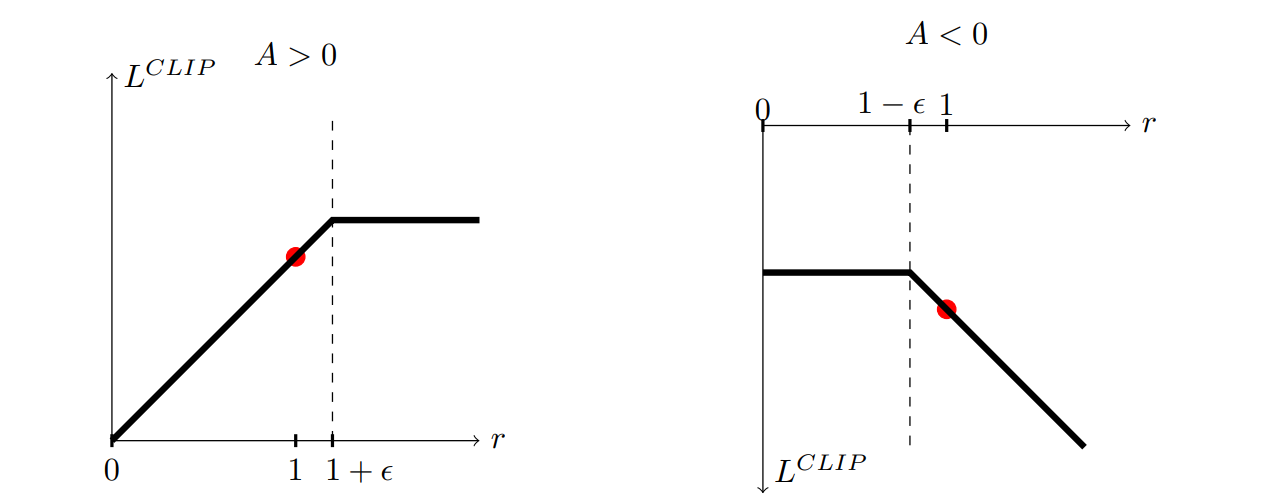
그렇다면 위 그림에서 clip을 시킴으로써 L이 커지는데에 penalty를 부여하는 부분이 어떻게 작동하는건지가 의문이였다.
위 코드에서는 다음과 같이 구현되어있었다.
표본을 특정 단위로 나눠서 학습을 진행하며, 이 단위로 θold가 고정된다.
이 특정 단위를 미니 배치 처리를 하여 여러개로 나눈 뒤, 여러번 업데이트 시킨다.
첫번째 업데이트시에는 위의 의문처럼 penalty가 작동하지 않는다.
하지만 두번째 업데이트부터는 θold와 θ가 달라지게 되며,
θ에서 선택된 행동이 θold에서보다 L이 임계점 이상 커졌다면 업데이트를 할 때 penalty가 부여된다.
여러 환경을 동시에 시뮬레이션 시키는 코드는 라이브러리에서 Pipe를 임포트한 뒤, 통신을 하는 시스템이 사용되었는데,
이 부분은 잘 이해가 안되서 내 방식으로 새롭게 구현하였다.
backward
확률 분포에서 한가지 행동을 샘플링하게 되면 이는 랜덤성을 이용하니 연산 그래프가 끊어질텐데 backward를 이용한 학습이 가능할까? 하는 의문이 있었다.
실제 구현은 다음과 같이 이루어진다.
정책이 반환한 확률 분포에서 샘플링된 행동이 어떤 확률 밀도를 갖는지 구할 수 있고 이는 그래프로 구현 가능하다.
이 밀도가 증가 혹은 감소하는 방향을 계산하며 backward를 통한 학습이 진행된다.
하이퍼파라미터
TRPO와 PPO등의 알고리즘이 등장하게 된 배경은 policy gradient를 계산 후, step을 할 때 이 step의 크기가 크다면 성능 향상이 보장되지 않는다는 점이다.
이는 사실 옵티마이저를 SGD를 사용하고, 학습률을 매우 낮게 설정하면 해결된다고 생각한다.
하지만 위 알고리즘을 사용하는 이유는 위 방법은 학습이 매우 느려질 수 있으며,
특정한 알고리즘을 사용함으로써 학습 속도를 향상시킬 수 있다면 좋기 때문이라고 생각하였다.
따라서 직접 구현하며 하이퍼파라미터를 조절할 때 위를 고려해서 조절했다.
간단 요약
actor의 output으로 인해 행동이 결정된다.
critic으로 해당 행동이 좋은지를 판단하며, 좋았다면 해당 행동을 할 확률을 높이는 방향으로 actor의 output이 조정되며,
안좋았다면 그 반대로 조정된다.
이때 PPO의 핵심인 clip은 조정이 너무 쎄게 되지 않도록 하는 테크닉 정도로 이해하면 되겠다.
https://github.com/nrye4286/reinforcementLearning/blob/main/Hopper_PPO.py
