Proximal Policy Optimization Algorithms
https://arxiv.org/abs/1707.06347
Background: Policy Optimization
아래는 TRPO 알고리즘이다.
constraint를 하며 위 항을 최대화 시킨다.
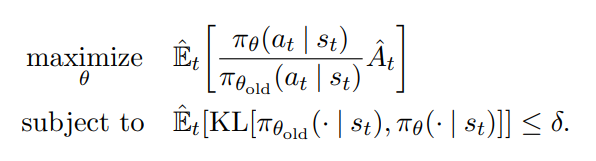
constraint대신 penalty를 이용하는 버전은 다음과 같다.
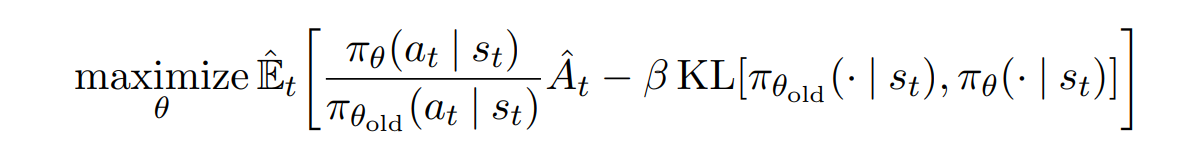
이 방법은 β를 몇으로 해야하는지, 학습중에 바뀌어야 하는지 알기 어렵기 때문에 TRPO에서 constraint방법을 이용했다고 한다.
이 논문의 목적인 TRPO의 구현의 어려움을 개선하면서
성능이 뒤쳐지지 않도록 하기 위해 위 수식에서 추가적인 변형이 필요하다.
Clipped Surrogate Objective
먼저 probability ratio를 새롭게 정의한다.
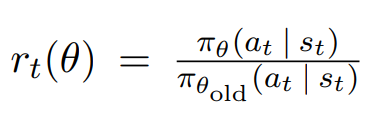
기존의 surrogate objective를 다음과 같이 표현 가능하다.
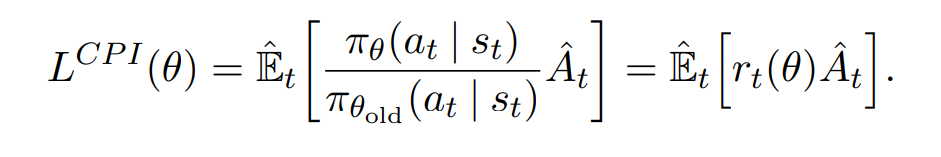
constraint 없이 단순히 이 값을 최대화 시키게 되면 과도하게 업데이트 되는 문제가 생긴다.
따라서 다음과 같은 objective를 제안하였다.
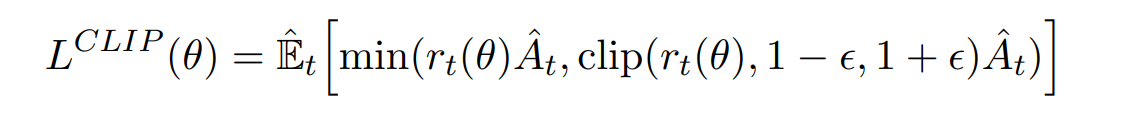
여기서 ε은 하이퍼파라미터이다.
위 수식은 특정 조건일때 L값이 커지도록 하는 변화를 무시한다.
아래 그림은 A 값이 양 혹은 음의 값일때, r 값에 따른 L 값의 그래프이며,
위 수식에서 두 항 중 최솟값으로 clip이 되어있는 모습이다.
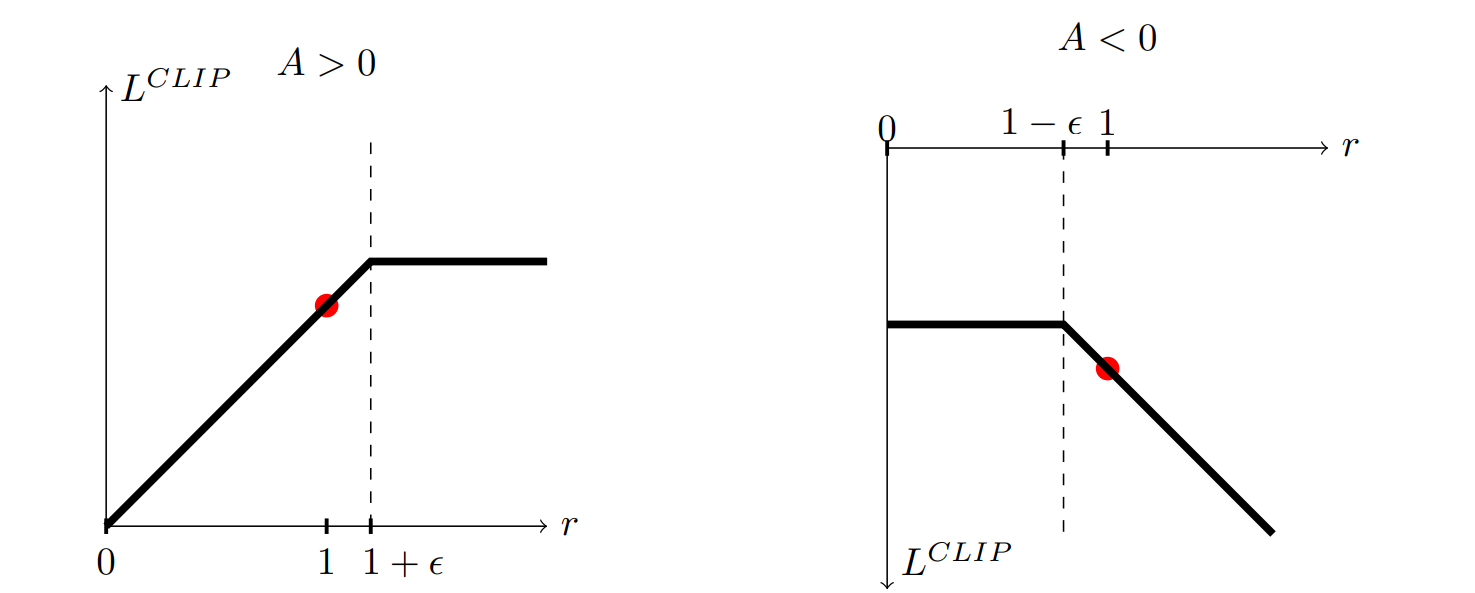
Lclip을 사용하게 되면 위 최대화 수식에서 L이 과도하게 커지는데에 penalty를 부여하는 역할을 하게 된다.
Algorithm
정책과 가치함수의 파라미터가 공유되는 뉴럴 네트워크 구조에서는 하나의 손실함수를 써야한다고 한다.
(이 논문에서는 그러한 구조를 사용하는 듯 함)
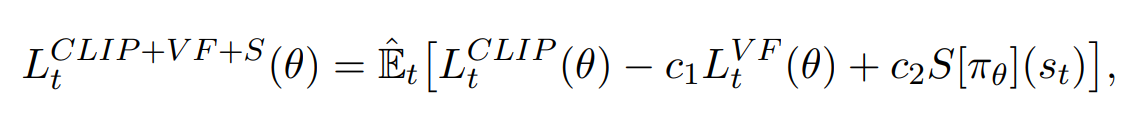
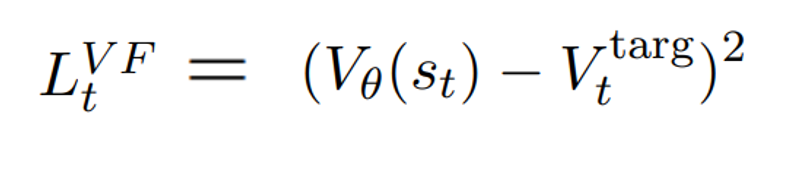
따라서 위 값이 증가하도록 학습을 시켜주면 된다.
S는 탐험을 위한 엔트로피 보너스라고 한다.
또한 A(advantage) 값을 GAE방식으로 계산한다.
https://velog.io/@nrye4286/GAE-%EB%85%BC%EB%AC%B8-%EB%A6%AC
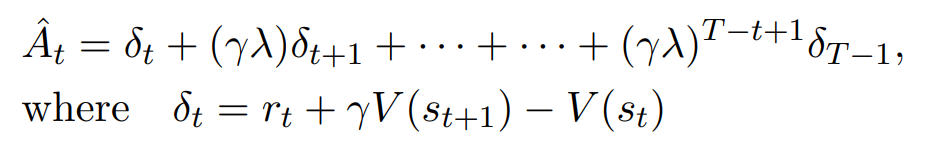
전체 알고리즘은 다음과 같다고 한다.

개념 요약
특정 단위마다 θold를 고정시킨 뒤 데이터를 수집후 θ를 학습하게 된다.
이때 상태, 행동, 그 행동이 선택될 확률, 이득 등의 데이터를 수집한다.
특정 단위의 데이터가 모이게 되면 미니 배치처리를 해서 θ를 학습하기 시작하는데, 학습이 진행될수록 행동이 선택될 확률이 θ와 θold에서 다르게 될 것이다.
두 확률의 비율이 특정 조건(L을 과도하게 올리는)을 넘을시에 clip(기울기가 0이 되며 학습되지 않음)하여 규제를 하게 된다.
코드 요약
critic이 가치를 근사하게 된다.
특정 행동이 좋은지 아닌지를 critic을 통해 판단하며, 좋다면 actor가 해당 행동을 할 확률을 높이도록 업데이트 된다고 이해하면 된다.
이는 코드로 다음과 같이 구현된다.
1. 행동 공간이 discrete할 때
actor가 softmax 확률을 반환할것이다.
softmax확률에 맞게 행동을 샘플링한 뒤,
해당 행동이 좋다면 인덱싱을 통해 softmax 확률 값에 접근한다.
위 값을 높이는/줄이는 방향으로 업데이트 되도록 코드를 작성하면 된다.
2. 행동 공간이 continuous할 때
actor가 평균값과 표준편차를 반환하며 이를 이용해 정규분포를 만든다.
여기서도 확률 분포를 통해 행동을 샘플링하게 된다.
다른점은 인덱싱을 통해 확률에 접근하는 것이 아닌, 수학적 계산을 통해 해당 행동이 선택될 확률 밀도를 계산하게 된다.
마찬가지로 위 확률 밀도 값을 높이는/줄이는 방향으로 업데이트 되도록 코드를 작성하면 된다.
