[Imitation Learning] Overview of Imitation Learning, Distribution Shift
Reinforcement-Learning
In RL, we can get agent by designing reward function.
But designing reward function for complex task is too hard.
I thought 'how about reward funtion with neural network?'.
There was similar idea, IRL (Inverse RL) in Imitation Learning.
Imitation learning can be broadly classified into BC (Behavioral Cloning) and IRL
Imitation learning vs RL
Imitation learning use expert data.
RL can also use expert data.
But if we can not access reward function for some task, imitation learning can be breakthrough.
And if it is important to do safe exploration, imitation learning is better than RL.
RL can also use expert data in offline RL area.
If we both have expert data and reward function, which way is the best?
After study this area, I will add my opinion.
Behavioral Cloning
BC is an IL technique that treats the problem of learning a behavior as a supervised learning task.
It mimics an expert’s behavior by learning to map the state of the environment to the corresponding expert action.
One of its drawbask is called Covariate shift(Distribution shift).
The state distribution observed during testing can differ from that observed during training.
Interactive IL
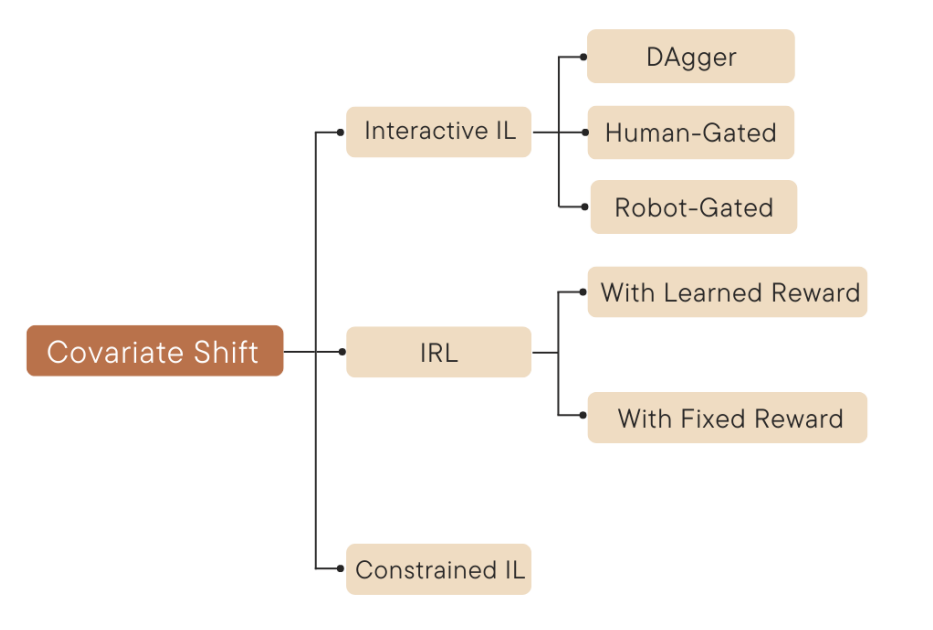
Interactive IL need expert's intervention.
DAgger(Dataset aggregation) queries the expert to relabel the data collected by the agent with the appropriate action that should have been taken.
Human-Gated DAgger allow the expert to decide when to provide the corrective interventions. -> less burden, no limits.
Robot-Gated DAgger is the way robot ask humans for intervention.
Inverse RL
'Algorithms for Inverse Reinforcement Learning' paper
Training reward function from demonstrations.
And then training RL agent.
-> slow
ADVERSARIAL IMITATION LEARNING
'Generative Adversarial Imitation Learning' paper (GAIL)
Adversarial Imitation Learning can be described as 'Doing IRL and RL simultaneously'.
-> faster than IRL
IMITATION FROM OBSERVATION
Above algorithms need demostrations.
They need (state, action) data pairs.
But human can imitate someone just by observation.
No needs data of their low-level actions like muscle commands.
There is area where using this concept.
