Algorithms for Inverse Reinforcement Learning
https://ai.stanford.edu/~ang/papers/icml00-irl.pdf
This paper is old.
It would not include neural network.
So I will read it briefly now, and read it in detail if necessary.
Algorithms for Inverse Reinforcement Learning
The problem can be categorized like this.
-
is the state discrete? or continuous? (infinite?)
-
is the model known? (we know chess's model but not for driving)
-
is the policy given? or just known only through a finite set of observed trajectories?
This paper start first with finite state, known model, given policy.
IRL in Finite State Space
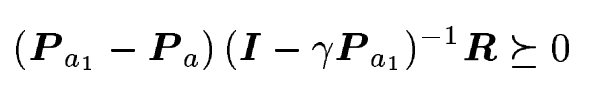
'a1' means optimal action, and 'a' means another action.
P means transition probabilities.
If obove equation is True, a1 is optimal action.
You can see proof in paper.
But there are a lot of reward function satisfying above equation. (i.e. all zero reward)

It is good to find a function which maximize this equation for meaningful reward function.
And reward function composed small reward is simpler and preferable.
So add −λ∥R∥ to objective.
If λ is too big, all reward would be 0.
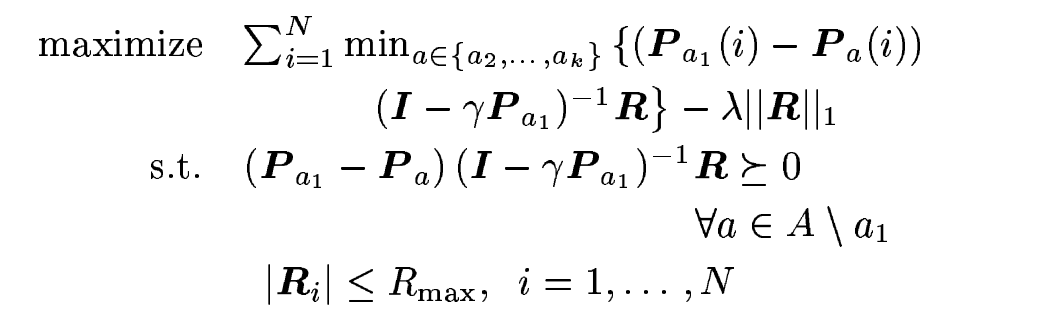
IRL in Infinite State Space
I think this section will introduce the way to generalize for infinite state space.
But neural network would be better.
So if I need, I will read it later.
