강화학습은 보상함수를 필요로 한다.
보상함수 설계가 매우 어려운 경우가 있으며(ex. LLM), 설계한다 하더라도 모델이 편법으로 보상을 최대화한다던가, 보상이 sparse해서 학습이 느려진다던가 하는 문제가 발생한다.
RLHF는 인간 선호도 데이터를 통해 보상함수 네트워크를 학습하고, 이를 이용해서 강화학습을 하는 분야이다.
특정 task를 잘하기 보단, 특정 task를 잘하는지 판단하는것의 복잡도가 더 낮기 때문에 쓰임새가 있는것이 아닐까 생각해본다.
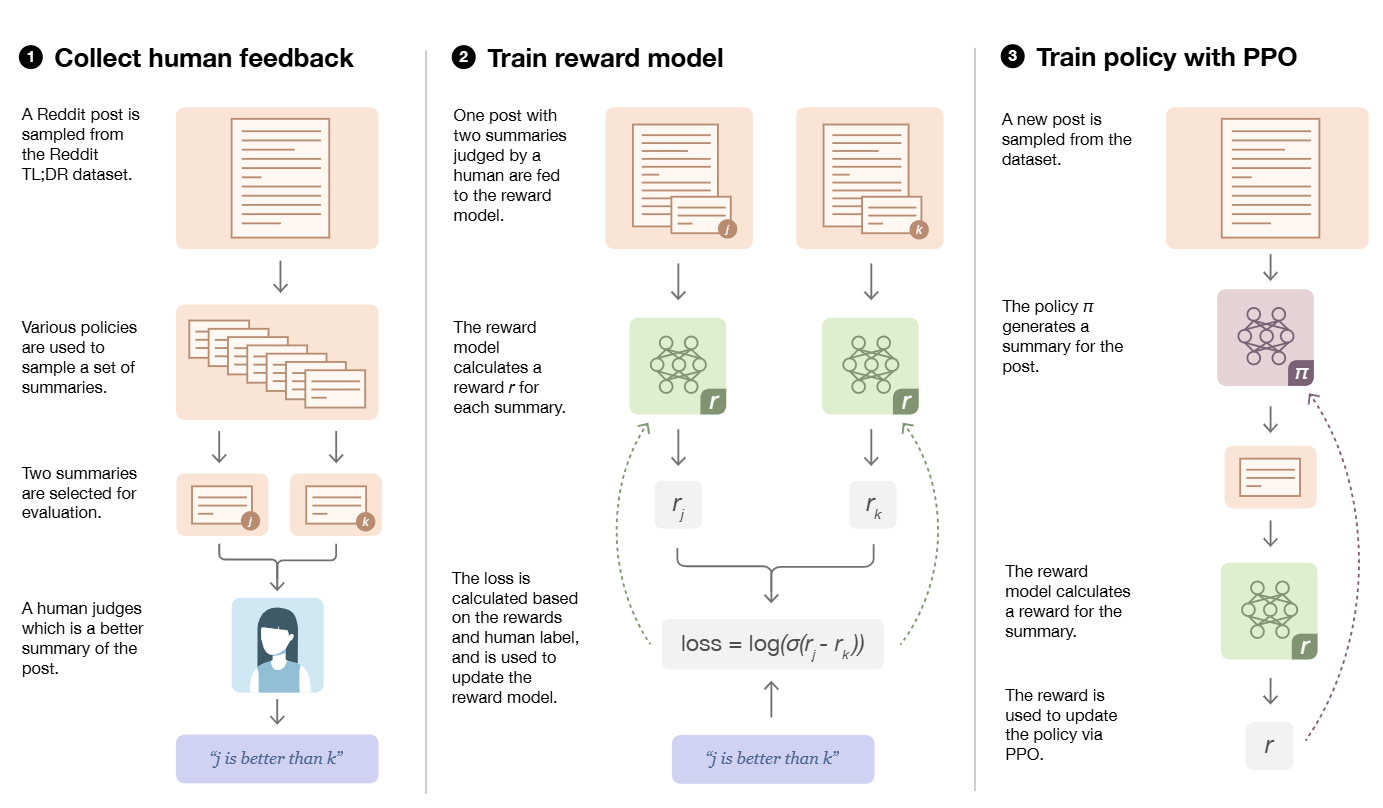
인간 선호도 데이터 수집
인간의 선호도 데이터를 정량적으로 수집하기는 쉽지 않다.
따라서 하나의 인풋에 대한 여러 output의 상대적인 선호도를 포함하는 데이터가 주로 이루게 된다.
보상함수 학습
보상함수는 더 선호되는 output의 보상이 더 크도록 설계된다.
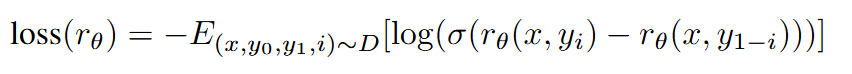
강화학습
PPO
자세한 알고리즘은 이전에 정리했으니 패스하겠다.
PPO방법은 actor-critic 알고리즘으로 critic이 필요하다.
따라서 actor, reward_model, critic으로 3개의 모델이 필요하게 되는데, LLM같이 무거운 모델을 학습하게 될 때 많은 VRAM이 필요하게 된다.
GRPO
DeepSeek R1모델이 강화학습 시에 GRPO 알고리즘을 이용했다고 한다.
GRPO는 critic을 이용하지 않는 알고리즘이다.
critic이 행동의 가치를 근사하기 위해 사용되나, GRPO는 하나의 input에 대해서 여러 output을 반환하고, 평균 보상을 이용하여 가치를 대체하게 된다.
LLM을 예로 들었을때, 보상은 output 시퀀스 마지막에 주어지게 된다.
문장 전체를 하나의 행동으로 보며, 선호되는 문장의 모든 토큰의 확률을 일률적으로 업데이트 하게 된다.
반면 PPO는 토큰단위의 가치를 근사할수 있기 때문에 섬세하게 조절 가능하다.
