object detection 모델인 YOLO를 공부했었다.
동영상에서 프레임들간의 물체를 tracking하게 되면 물체의 속도, 예측 이동 방향 등을 알 수 있게 되어 여러 방면에서 쓸모가 있다.
object tracking은 object detection모델과 tracking 알고리즘을 결합하여 구현하기도 하고, End-to-End 모델로 구현하기도 하는듯 하다.
트랜스포머를 이용한 End-to-End 방식 object tracking 모델인 MOTR에 대해서 공부해봤다.
이 모델이 트랜스포머를 이용하는 만큼, 트랜스포머 구조를 자세히 알고 있지 않으면 이해가 불가능하다.
MOTR: End-to-End Multiple-Object Tracking with Transformer
https://arxiv.org/pdf/2105.03247
이 논문에서의 object tracking은 단순히 이전 프레임에서 detect된 object가 다음 프레임에서도 유지될 시 대응시켜주는 작업이라고 생각하면 될 것 같다.
한 object가 가려졌다 다시 나타났을 때 "그때 그 친구?" 까지는 구현하진 않는듯 하다.
간단한 설명
트랜스포머는 인코더-디코더 구조로 이루어져 있다.
간단하게 설명하자면, 동영상의 각 프레임마다 해당하는 이미지를 인코더-디코더 구조를 통해 object detect 작업를 진행하게 된다.
이전 프레임에서 detect된 물체에 대한 정보를 다음 프레임 계산시에 사용하게 되면 두 프레임에서 detect된 물체 간의 관계를 알 수 있겠다는 전략이다.
이때, 이전 프레임에 대한 정보가 쿼리의 형태로 입력되는데,
아웃풋의 길이는 쿼리의 길이와 같으며, 각 아웃풋은 쿼리와 대응할 수 있게 된다.
이전 프레임의 쿼리에 대응하는 아웃풋에서 object detect가 되었다면 같은 물체라고 보는 방법이다.
자세한 구조
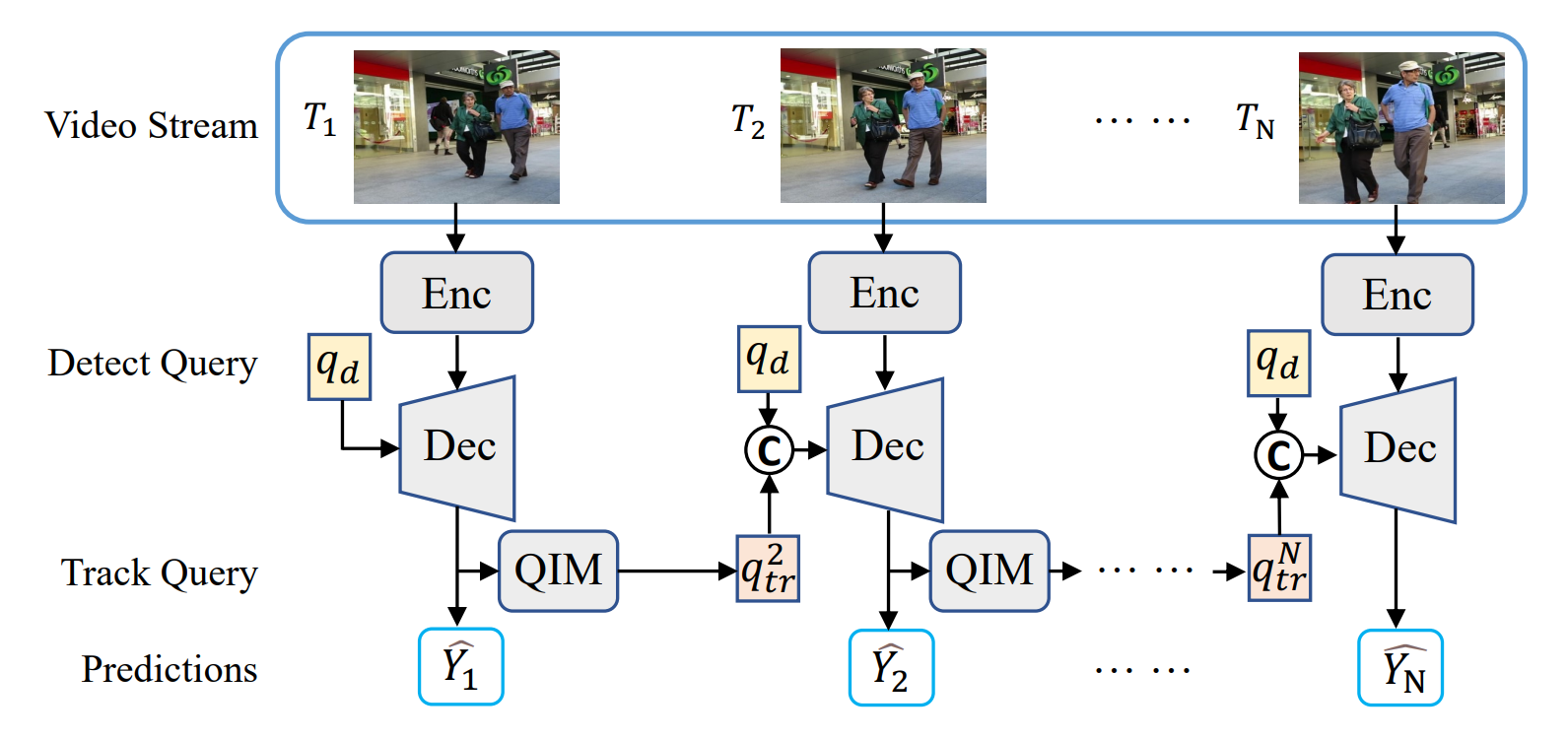
먼저 각 이미지들은 CNN을 통해 특징이 추출되며, 이가 인코더에 입력된다.
인코더의 아웃풋은 당연히 디코더로 들어가게 될 것이다.
이때 디코더에 detect query와 track query가 concatenate되어 디코더에 추가로 주어지게 된다.
detect query는 새로운 물체를 감지하도록 하는 미리 학습된 쿼리이며,
track query는 기존의 물체를 감지하는 역할을 하고 디코더의 이전 아웃풋을 통해 만들어진다.
위 그림에서의 QIM 모듈과 그 내부에 TAN 모듈은 다음과 같은 구조를 갖는다고 한다.
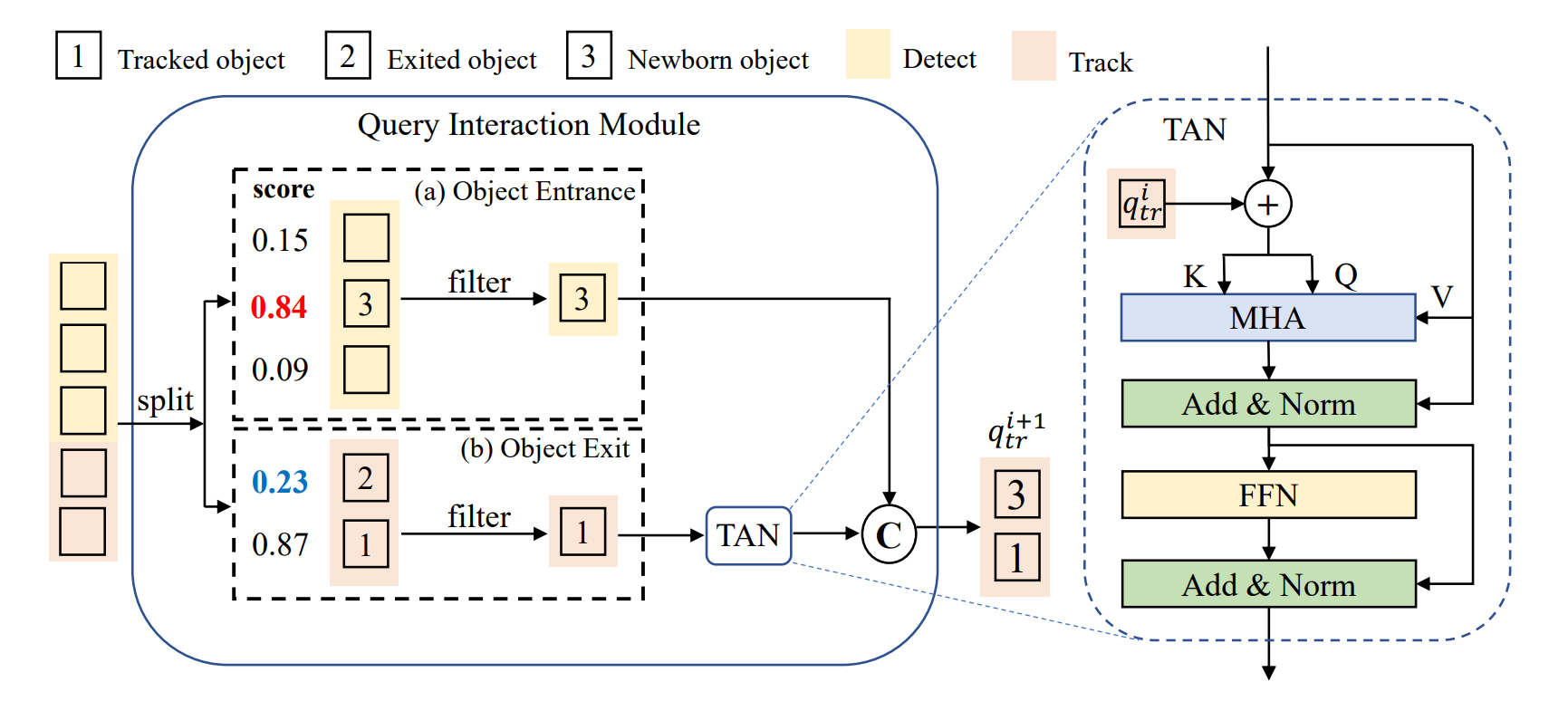
MHA는 multi-head self-attention, FFN은 feed-forward network로 트랜스포머의 디코더 구조와 유사하다.
tracking test
YOLO와 tracking 알고리즘을 이용한 방법으로 쉽게 object tracking을 할 수 있길래 이거 썼다.
결과물은 비슷할테니 상관 없나 싶다가도
이럴거면 tracking 알고리즘을 공부해볼걸 하는 생각도 든다.
!pip install ultralytics
from ultralytics import YOLO
model = YOLO('yolo11n.pt')
result = model.track(source = '/content/Untitled.mov',show=True, save=True)영상 파일 주소만 넣어주면 되며, 결과 영상 링크이다.
