YOLO 이전의 object detection 모델들은 window sliding방식으로
물체를 찾고, 그 물체가 뭔지 분류하는 방식인듯 하다.
이는 end-to-end 모델이 아니다.
좋은 end-to-end 모델에 비해 일반화, 속도, 오차의 증폭 측면에서 불리함은 필연적이라 생각된다.
YOLO는 convolution모델로 end-to-end 방식 object detection 모델이며, 꽤 좋고 빠른 성능을 보인다고 한다.
논문을 읽으며, 이를 어떻게 가능하게 했는지 공부해 봤다.
You Only Look Once: Unified, Real-Time Object Detection
https://arxiv.org/abs/1506.02640
2. Unified Detection
먼저 이미지를 S × S grid로 나눈다.
각 grid들은 B개의 bounding box와 각 bounding box에 해당하는 confidence score를 예측한다.
confidence score는 해당하는 bounding box에 물체가 있는지, bounding box가 정확한지에 대한 값을 갖는다.
실제로는 [x, y, w, h, confidence score]의 형태로 예측한다.
x, y는 해당하는 grid에서의 상대적인 위치,
w, h는 전체 이미지 크기에 대한 상대적인 크기이다.
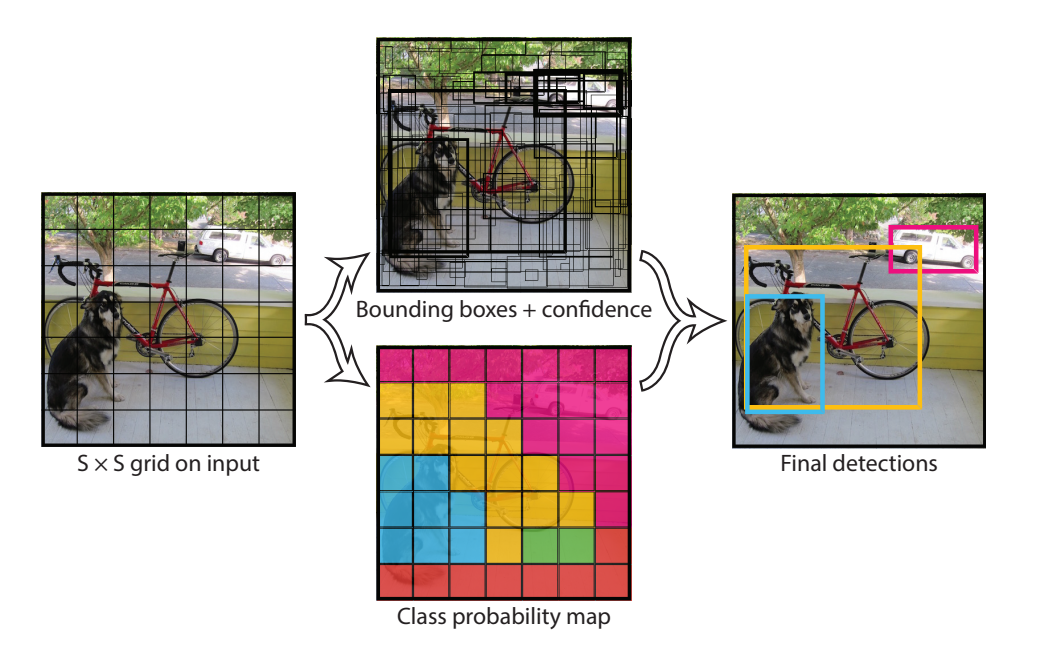
위 이미지를 보면 bounding box의 크기가 grid cell의 크기를 벗어나도 되는것을 알 수 있다.
또한 동시에 grid cell 단위로 물체(C개)를 예측한다고 한다고 하며, 이는 bounding box의 개수와 관련 없이 진행된다고 한다.
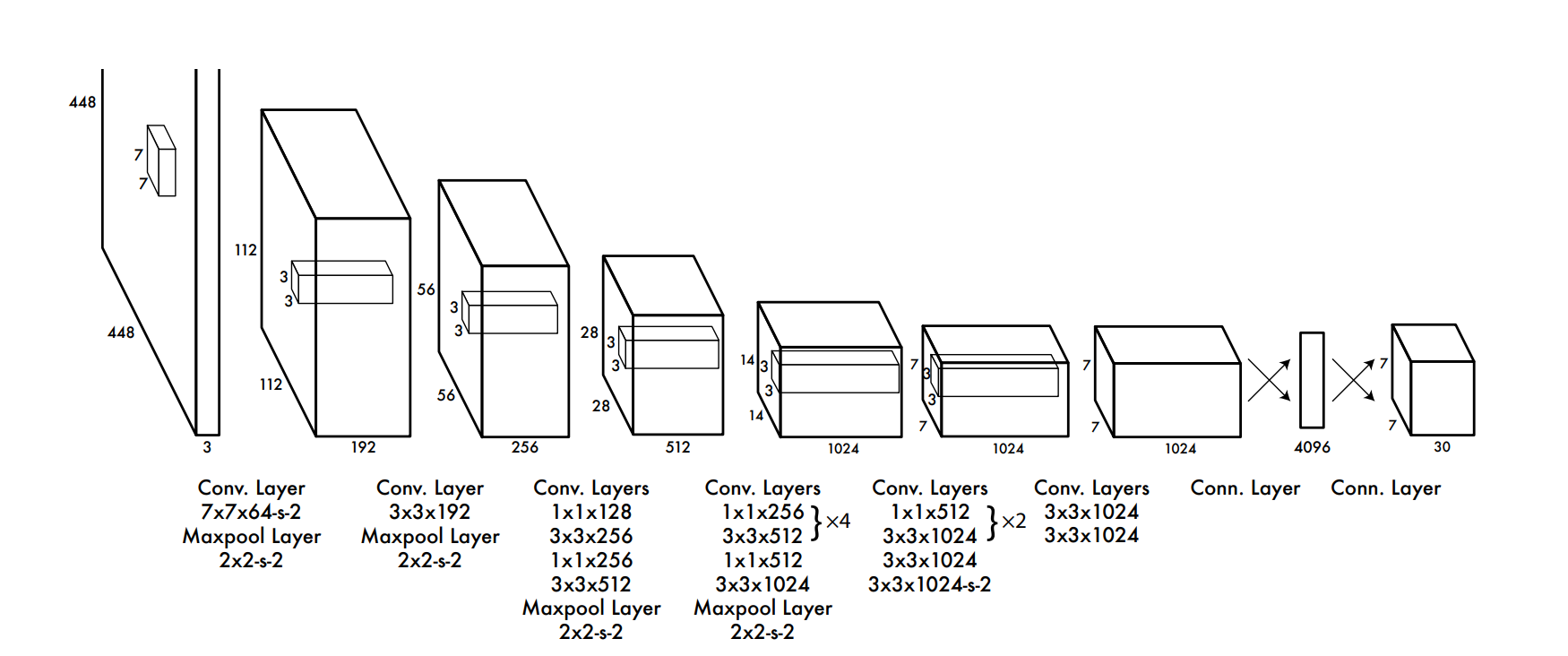
떠라서 모델은 S × S × (B ∗ 5 + C)의 shape을 갖는 텐서를 반환하게 된다.
bounding box들 중 confidence score가 임계값을 넘는 bounding box들에 대해, 해당하는 grid가 예측하는 물체를 부여해서 object detection을 하겠다는 전략인 듯 하다.
PASCAL VOC detection dataset으로 평가했다고 한다.
S = 7, B = 2, C = 20 -> 7 × 7 × 30 텐서로
위 모델의 구조 그림과도 맞는다.
2.2. Training
그렇다면 다음으로 궁금한 점은 위와 같이 이상적으로 작동하도록 학습하기 위해서 어떤 알고리즘, 어떤 loss 함수를 사용했는가이다.
먼저 앞쪽 20개의 convolution layer는 pretrain 시켜줬다고 하며,
target 데이터들을 모델의 아웃풋과 같은 형태로 처리해 둔 뒤,
단순하게 squared error로 loss함수를 구현한 듯 하다.

2.4. Limitations of YOLO
grid별로 하나의 물체만을 예측하기 때문에 새 때같은 것들을 탐지하는것에 어려움을 보인다고 한다.
grid cell의 개수를 대폭 늘리게 되면 해결할 수 있지 않나 싶지만,
이렇게 함으로 인한 단점들이 더 크기 때문에 그렇게 안 하겠지 싶다.
사용
코랩에 복붙하기만 하면 아래와 같이 실행된다.
from transformers import YolosImageProcessor, YolosForObjectDetection
from PIL import Image
import torch
import requests
import numpy as np
import matplotlib.pyplot as plt
url = "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS9-IvIgFnCkoS-wgGs-oYJ1BLUMfEJbj06vDtPAW4X8U49SIIf46SSMaWUIQn7iP9V4Iw&usqp=CAU"
image = Image.open(requests.get(url, stream=True).raw)
plt.imshow(image)
plt.show()
model = YolosForObjectDetection.from_pretrained('hustvl/yolos-tiny')
image_processor = YolosImageProcessor.from_pretrained("hustvl/yolos-tiny")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# model predicts bounding boxes and corresponding COCO classes
logits = outputs.logits
bboxes = outputs.pred_boxes
# print results
target_sizes = torch.tensor([image.size[::-1]])
image = np.array(image)
results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
image[int(box[1]), int(box[0]):int(box[2]), :] = 255
image[int(box[3]), int(box[0]):int(box[2]), :] = 255
image[int(box[1]):int(box[3]), int(box[0]), :] = 255
image[int(box[1]):int(box[3]), int(box[2]), :] = 255
plt.imshow(image)
plt.show()
