RAMBO-RL 논문을 읽기 위해 필요해보여서 RARL 논문을 읽게 되었다.
현재 연구들, 지금으로 치면 2024 2025 논문을 읽고 싶은데 그 과정이 참으로 길다..
RARL(Robust Adversarial RL)
Offline-RL을 다루진 않는다. 따라서 Distribution shift가 아닌 Robust함에 초점을 맞춘 논문이다.
policy가 robust하면 당연히 좋을 것이다.
그 예시로 시뮬레이션을 현실로 옮겼을 때, 환경, 역학 등이 완벽하게 동일할 수는 없기 때문에 robust함은 중요할 것이다.
Overview
adversarial network를 학습해서 policy를 교란시키도록 학습한다.
-> policy는 교란에 대해 robust 해질 것이다.
Object
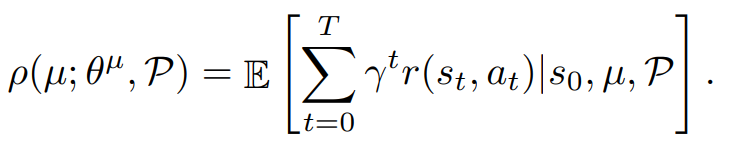
P는 transition probability이다. 보통의 강화학습에서 P는 고정이다. (표기할 필요 X)
policy는 위 object를 최대화 시키는 θ를 찾는 것이다.
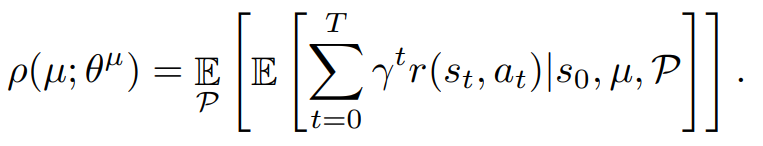
하지만 adversarial network가 환경을 교란시킬것이기 때문에 object는 위와 같이 되며, policy는 object를 최대화, adversarial network는 object를 최소화 시키는 방식이다.
adversarial network의 output의 크기는 크면 클 수록 효과가 커지니 크기에 제한 혹은 규제가 들어갈 듯 하다.

adversarial network도 object를 최소화 시키는 action의 교란 값(policy의 action과 더해지는)을 반환할 듯 싶다.
adversarial network가 P를 교란시키는 것이 목표에 적합할 것으로 생각되나, 이는 적용하기 어려워서 위와 같이 하는 듯 싶다.
RAMBO-RL(Robust Adversarial Model-Based Offline Reinforcement Learning)
Problem Formulation
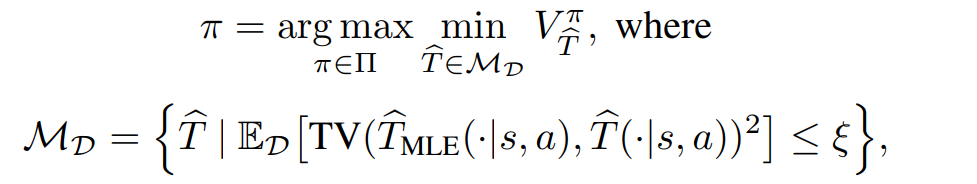
환경을 학습
-> 여러 환경(기존 환경과의 차이가 일정 수준 내의)들에서의 성능 중 최소가 최대가 되도록 하는 정책 == robust한 정책
offline RL처럼 모델은 supervised learning(MLE)해준 뒤,
위 모델에서 크게 벗어나지 않는 선에서 가치의 기댓값을 낮추는 방향으로 업데이트 하는 방식인 듯 하다.
Model Gradient

위 내용은 아래 글을 참고하면 이해하기 쉬울 것이다.
Adversarial Model Training

위의 이론의 적용을 위해 규제의 형식으로 구현한다.
특정 기준 내에서 최소를 찾아야 했다.
특정 기준을 벗어날 수록 값이 커지도록 규제를 하는 방식인 듯 하다.
최종 알고리즘
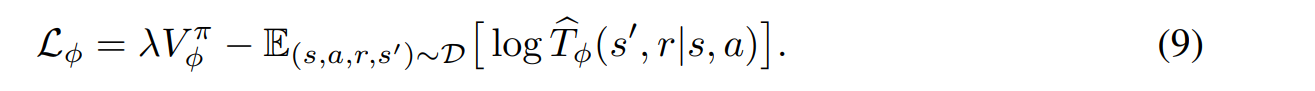

기존 모델(MLE)을 학습하고, 기존 모델을 이용하여 Adversarial Model을 구하는 방식이 아닌, 한번에 최적화 할 수 있는 최종 loss함수를 제안한다.
대부분의 논문이 이런식이다.
과정에서의 복잡한 수식은 결국 다 사라지고, 매우 간단한 최종 알고리즘만 남게 된다.
직관적으로 알고리즘을 짜고, 돌리는 동안 수학적으로 분석해보는 방식으로 연구를 하지 않을까 생각해 본다.
그냥 MOPO알고리즘에서 모델 loss함수에 policy에 적대적이도록 하는 항 추가한게 전부잖아!
