가중치를 이용하여 가치를 근사할 경우에
제한된 재원을 이용하여 모든 상태의 가치를 근사해야 한다.
이때 가치를 정확히 아는것이 중요한 상태와 상대적으로 그렇지 않은 상태가 있을것이다.
따라서 재원을 목표 지향적으로 활용한다면 성능을 향상시킬수 있을것이다.
interest지표와 emphasis지표를 활용하여 이를 구현한다.
각 표본에 대해 I값(interest, 양수)을 부여한다.
이는 어떠한 방식이든 상관 없다.
I값을 통하여 M값(emphasis)을 갱신해 나가며 학습시에 M에 비례하여 가중치가 업데이트되도록 한다.
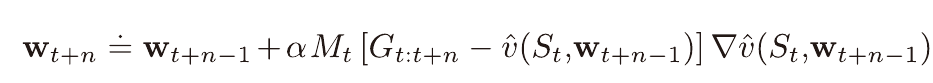
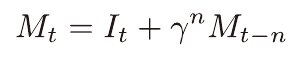
이때의 M은 시간차 학습을 통해 표본을 만들때에
강조하는 크기를 계승시키기 위해 도입된것으로 이해할 수 있겠다.
(시간차 학습에서의 n을 이용)
구현
파이토치에서 구현하는 방법에 대해 연구해 보았다.
모델의 output과 실제 가치를 이용하여 loss를 계산하고, 이를 역전파시키게 되는 원리를 이용한다.
모델의 output과 loss에 M값을 곱해주게 되면 역전파되는 값에 M이 곱해지게된다.
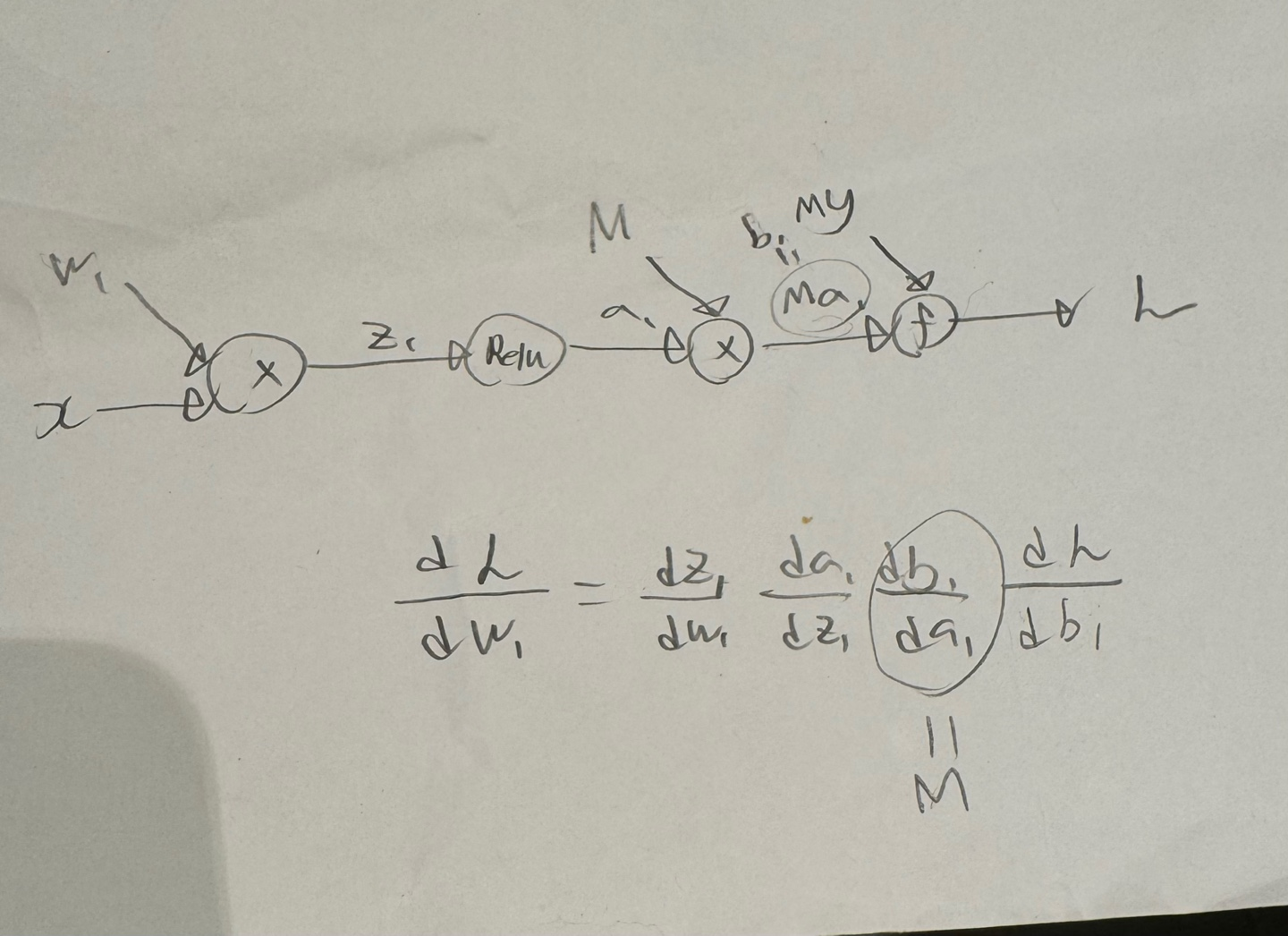
위 방법을 이용할 시 배치처리시에도 문제 없이 학습이 가능하다.
손실함수에 따라서 수정이 필요하다.
MSELoss를 사용할 경우에는 M대신 루트M을 적용해야 한다.
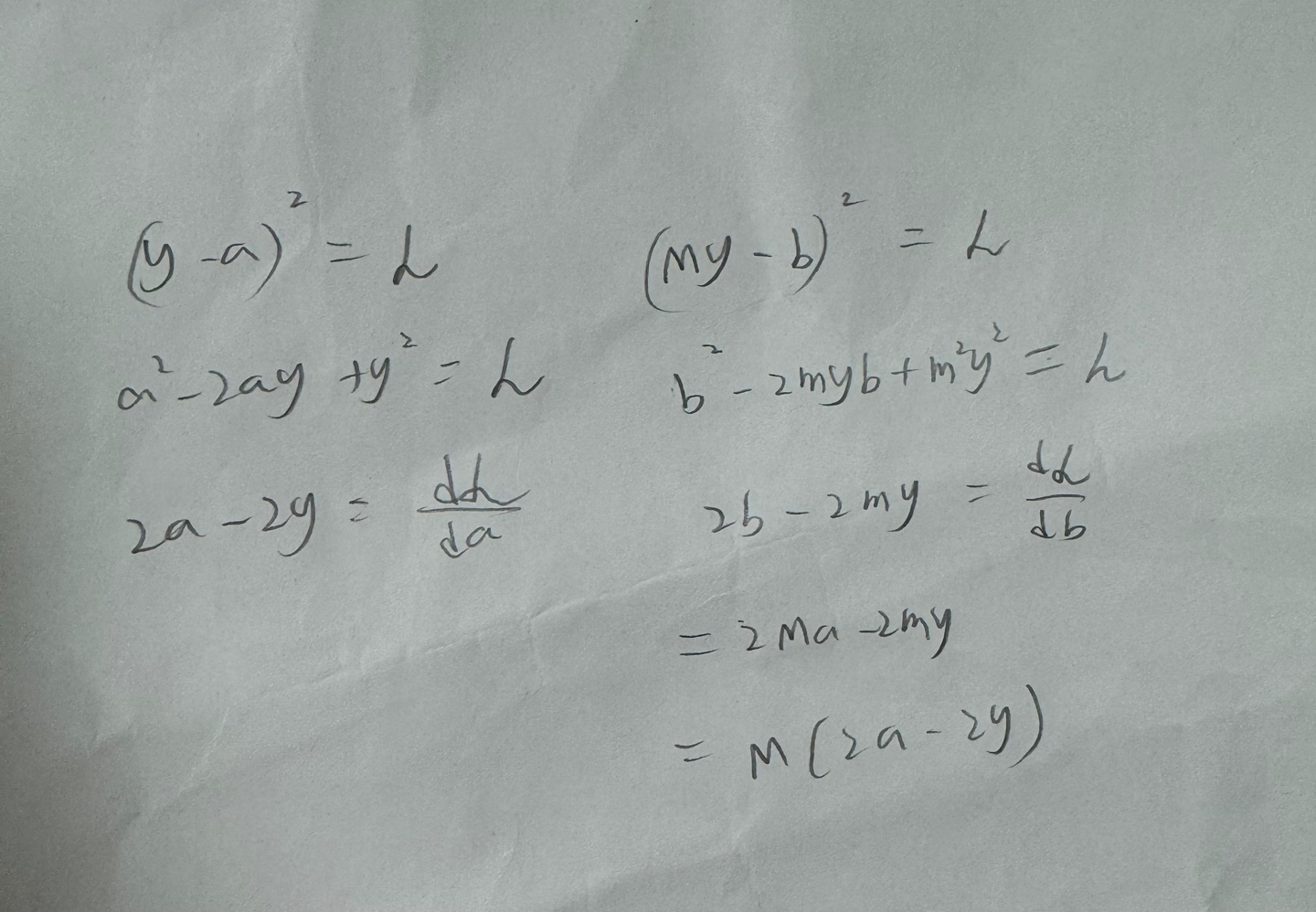
적용
오목 강화학습을 할때 두 모델끼리 시뮬레이션을 통해 학습을 해 본 적이 있다.
한 모델이 계속해서 지게 될 경우 학습이 제대로 이루어지지 않았다.
이상한 수를 두어서 진 표본에 대해서만 학습하게 되기 때문으로 추측된다.
이때 위와 같은 상태에서는 낮은 I값을, 승리하게 된 경우에는 높은 I값를 부여한다면 보완 가능할것으로 예측된다.
