종단 상태가 없는 연속적인 문제에서 평균 보상을 이용할 수 있으며,
할인율 대신 평균 보상을 이용하는것이 좋다고 한다.
평균 보상을 이용하는 방법과, 그 이유에 대해서 소개해 보겠다.
평균보상
평균 보상은 특정한 정책을 따를때의 평균 보상을 의미한다. (당연)
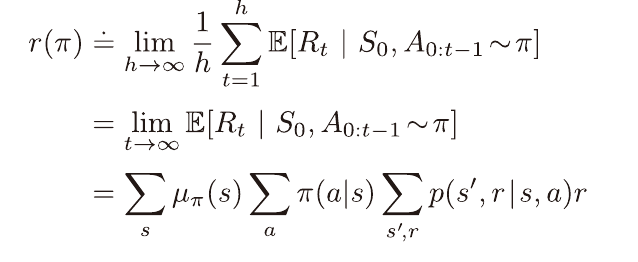
수식은 위와 같다.
μ는 안정 상태 분포로, 정책을 따를때 마주치는 상태의 분포(비율)로 이해하면 되겠다.
이는 모든 정책마다 존재하고 시작상태에 대해 독립적인 분포라고 가정하며,
이로 인해 위 평균 보상의 극한값이 존재함을 보장할 수 있다.
보상이 무한히 누적된다면 이득은 발산하게 되기 때문에 할인율은 필요하다.
하지만 이득을 계산할 때 매 시간단계마다 평균보상과의 차이를 합산해주는 방식을 사용하게 된다면 할인율을 대체할 수 있다.
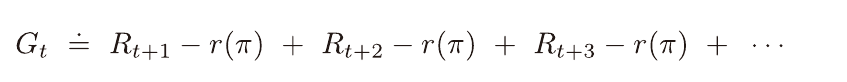
또한 할인율이 없어지게 됨으로 인해 장기적인 보상에도 집중할수 있게 된다.
할인율에 대한 반대
연속적인 문제에서 근사적 방법을 이용할 시 정책 제어를 하기 위해서
오랜 구간에 대한 평균 이득을 측정해야 할 것이다.
이때 각 보상에 부여되는 할인율은 1 + γ + γ^2 + ... = 1/(1-γ)로 같다.
따라서 평균 이득은 r(π)/(1-γ)가 된다.
정책의 평균 보상간의 차이가 유의미할 뿐
할인율의 크기가 얼마인지는 중요하지 않으며, 정책 제어시에 영향을 끼치지 못함을 의미한다.
