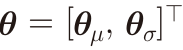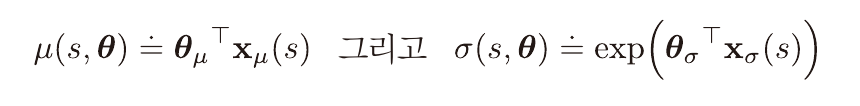여태까지 정책은 가치에 대해 탐욕적인 정책을 사용하였다.
정책 또한 파라미터화 하는 방법은 어떨까?
행동 선호도 방법
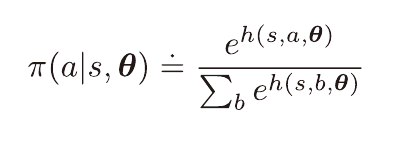
정책 π를 위와 같이 정의한다.
각 상태 s, 행동 a쌍에 대해 수치적 선호도 h가 주어지고
이를 이용하여 소프트맥스 분포 확률을 만든다.
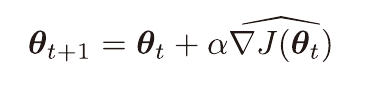
이때 θ는 정책의 성능 지표 J가 증가하는 방향으로 업데이트 되며, 미분 가능해야 한다.
이를 사용함으로 인한 첫번째 장점은 정책이 결정론적인 정책으로 수렴할 수 있다는 점이다.
최적 행동의 선호도가 다른 값들에 비해 무한히 커지게 되며 가능하다.
이는 가치를 기반으로 만든 소프트맥스 분포 확률에서는 불가능하다
두번째 장점은 최적의 정책이 확률론적 정책일때 이를 찾을 수 있다는 점이다.
또한 탐욕적 정책과 달리 정책이 부드럽게 변화하기 때문에
수렴성을 강하게 보장할 수 있다.
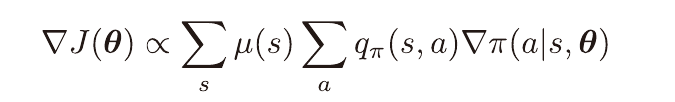
에피소딕 문제에서 할인율이 1일때의 ∇J(θ)는 위와같은 비례관계를 갖는다.
비례상수는 평균 에피소드 길이이다.
증명과정

연속적인 문제에서는 비례상수가 1이되며, 등식이 된다고 한다.
이는 평균 보상과 관련하여 새롭게 정의되기 때문이며 이에 대한 증명과정은 위 증명 과정보다 더 길다. 따라서 생략하겠다.
몬테카를로 방법에서의 적용
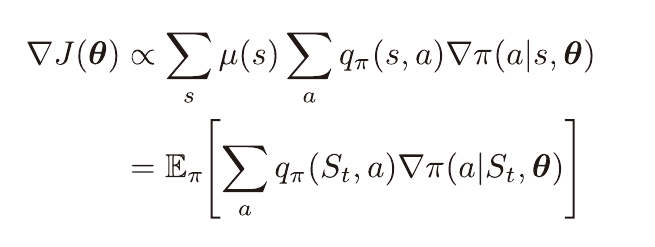
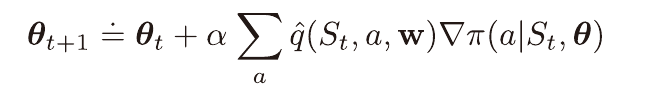
기댓값 내 관측된 표본 이득은 가치와 같기 때문에 아래와 같이 변형 가능하며
따라서 가치 함수 없이 정책 선호도 방식으로 학습이 가능하다.
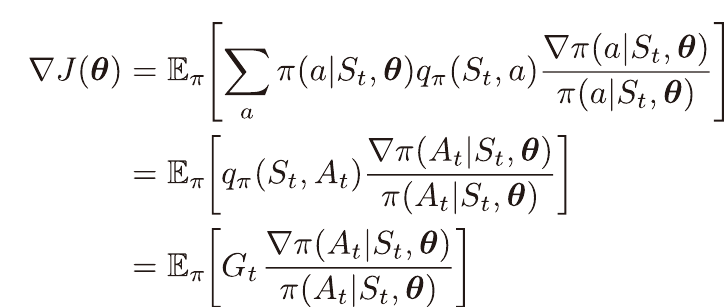
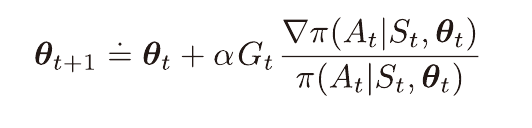
θ의 갱신마다 더해지는 값은 G와 어떤 벡터의 곱과 비례한다.
파라미터 공간에서 이 벡터의 방향은 상태 St에서 At를 선택할 확률을 증가시키는 방향이 된다.
이때의 증가량은 G와 비례하며, 취해진 행동이 선택될 확률과는 반비례한다.
이득이 클수록 많이 증가하며, 자주 선택된다고 많이 증가하지는 못하도록 막기 때문에 일리가 있다.

자세한 알고리즘은 위와 같다.
기준값이 있는 방법
a와 독립적인 기준값을 포함하도록 수정할 수 있다.
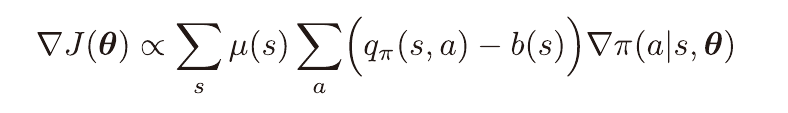
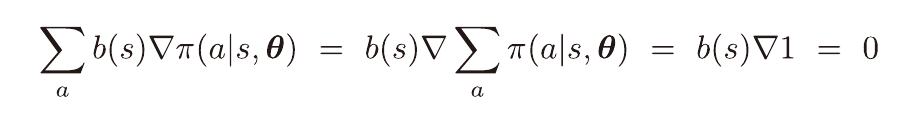
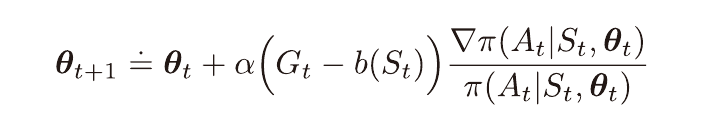
특정 상태에서 모든 행동이 가치가 높을때 더 높은 행동과 아닌 행동을 구별하기 위해 기준값을 사용한다.
모든 행동들의 선호도가 무한히 커지는것을 막아준다.
이때의 기준값은 상태 가치의 추정값이 적절할것이며,
이를 위해 추가적으로 학습을 시켜줘야 한다.

이때의 전체 알고리즘은 위와 같다.
시간차 학습
정책과 가치를 모두 근사하는 방법을 Actor-Critic 방법이라고 한다.
위 방법에서 가치 함수는 기준값으로만 쓰였다.
가치함수를 부트스트랩으로서 이용하며 시간차 학습을 할 수 있다.
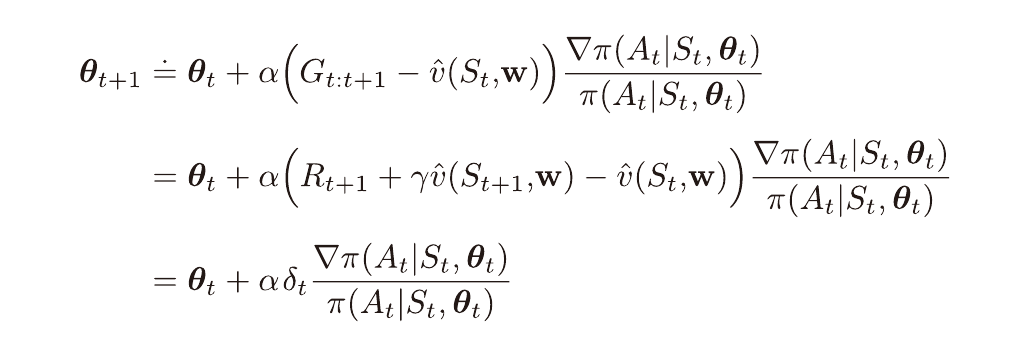
또한 적격 흔적을 적용할 수 있다.
연속적인 문제
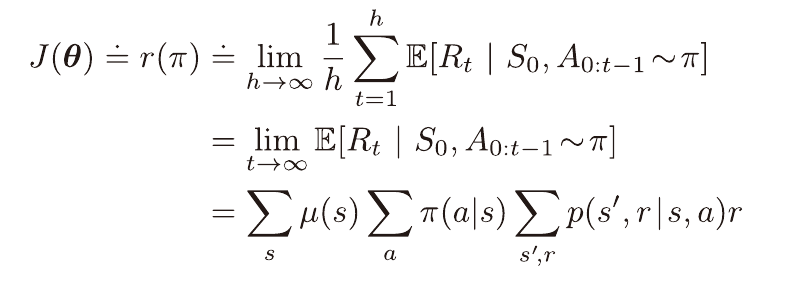
연속적인 문제에서는 시간 단계별 평균 보상을 이용하여 다음과 같이 성능 지표를 정의할 필요가 있다.

연속적인 문제에서 시간차 학습과 적격 흔적을 사용하며,
정책 근사 또한 사용하는 좀 더 자세한 알고리즘은 위와 같다.
연속적인 행동
행동공간이 연속적일때 일반적인 Q-Learing은 사용하기 어렵다.
행동가치가 가장 높은 행동을 선택해야 하지만, 행동이 무한개이기 때문이다.
정책 근사 방법, 즉 π(a|s,θ)를 이용해서 해결 가능하다.
여태까지 설명한 방법은 행동이 연속적일 때(무한개일 때)는 사용하지 못한다.
이때 정책은 정규 분포의 확률 밀도로 정의될 수 있다.
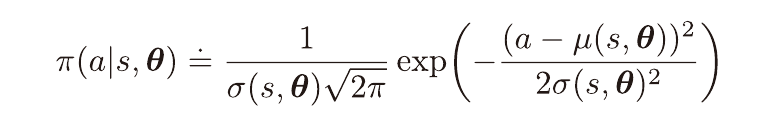
이때 파라미터는 평균, 표준 편차의 근사를 위해 두 부분으로 나눈다.